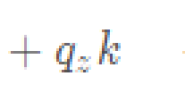嗨伙计们,我又来啦~ 在上次的文章[《webots玩转控制论之LQR控制器》](https://blog.75271.com/44222.html)中,我们假设系统是全状态反馈的,基于LQR实现了倒立摆的平衡控制,但是在实际情况中并非所有状态量都是能够直接通过测量得到的,那么这时基于全状态反馈的控制就不一定有效了。为了解决这个问题呢,我们就需要设计一个状态观测器,去估计系统不能直接给出反馈的状态量。 我们仍以倒立摆为例,完成今天的webots小案例!下面开始进入我要跟大家分享的内容。 首先来看下本次文章的安排:第一部分,我们通过思维导图简单回顾一下上次的倒立摆在webots中的模型节点关系;第二部分,同样属于回顾内容,给出上次根据动力学方程建立的系统状态方程;第三部分,是今天本文的重中之重!我们将仔细回顾状态观测器的设计步骤,最终得到基于状态观测器的LQR控制器;最后我们将在webots中编程实现这次的案例仿真!
1. webots建模
回顾上次建模的节点关系,如下图所示:

2. 系统动力学建模
假设关节旋转中心到质心距离为L,质心处转动惯量为I,忽略摩擦,通过输入力F使得倒立摆呈现平衡状态,如下图所示:
 取状态变量为:
取状态变量为:
 其中,
其中,
 则状态空间方程为(1),如下所示:
则状态空间方程为(1),如下所示:
 将系统动力学方程整理成状态空间方程为(2),如下所示:
将系统动力学方程整理成状态空间方程为(2),如下所示:

 在[《webots玩转控制论之LQR控制器》](https://blog.75271.com/44222.html)中我们已经验证了系统的可观可控性,这里直接省略该部分内容! 我们假设系统速度信息是不可测的,只能通过编码器来获得倒立摆的转角及位置数据,那么接下来我们开始进行状态观测器的设计。
在[《webots玩转控制论之LQR控制器》](https://blog.75271.com/44222.html)中我们已经验证了系统的可观可控性,这里直接省略该部分内容! 我们假设系统速度信息是不可测的,只能通过编码器来获得倒立摆的转角及位置数据,那么接下来我们开始进行状态观测器的设计。
3. 线性状态观测器的设计步骤
基于上次的内容,我们仍然使用LQR控制器,唯一不同的就是多了一个状态观测器的设计! 设x_hat为估计值,y_hat为估计输出,类比第2部分的状态空间方程,给出观测器状态空间方程为(3),如下所示:
 实际上这就是大名鼎鼎的Luenberge观测器! 将(3)式中的y_hat代入dot_{x_hat}可得:
实际上这就是大名鼎鼎的Luenberge观测器! 将(3)式中的y_hat代入dot_{x_hat}可得:
![]() 即:
即:
![]() 该式即为观测器的核心! 从上式可以得知,系统参数矩阵A、B、C、D均已知,要想得到状态估计值,我们首先需要知道系数L是多少,那么接下来的问题就变成了求解L的过程。 首先我们建立误差估计系统,由式(1)、(3)做差可得:
该式即为观测器的核心! 从上式可以得知,系统参数矩阵A、B、C、D均已知,要想得到状态估计值,我们首先需要知道系数L是多少,那么接下来的问题就变成了求解L的过程。 首先我们建立误差估计系统,由式(1)、(3)做差可得:
![]() 将测量值y代入上式,可得:
将测量值y代入上式,可得:
![]() 继续整理:
继续整理:
![]() 由此得到误差系统方程为:
由此得到误差系统方程为:
![]() 其中,
其中,
![]() 既然是估计系统,我们当然希望估计误差为0,那么我们就应该保证误差e趋向于0,也就是说(A-LC)的特征值的实部应该要小于0才行,即:
既然是估计系统,我们当然希望估计误差为0,那么我们就应该保证误差e趋向于0,也就是说(A-LC)的特征值的实部应该要小于0才行,即:
![]() 此外,由于我们将考虑使用状态观测器所估计出的参数值作为控制器的输入,所以我们当然希望状态估计值的收敛速度要快于整个闭环系统的输入的期望值。换句话说,我们希望观测器极点应该比控制器的极点要快才行。 现在参数矩阵L的求解又变成了极点配置问题! 根据经验来看,我们一般让观测器极点比控制器极点快4-10倍,但如果太快则可能会出现问题!至于为什么会出现这种现象呢?要想研究明白该问题我们就需要回去研究极点对系统的影响,实际上这也是控制论中的基本矛盾! 首先求得LQR控制器的极点,然后根据经验得到观测器极点配置信息,由此可得观测器的参数矩阵L。 这时,我们需要把状态反馈控制器和状态估计器结合起来:
此外,由于我们将考虑使用状态观测器所估计出的参数值作为控制器的输入,所以我们当然希望状态估计值的收敛速度要快于整个闭环系统的输入的期望值。换句话说,我们希望观测器极点应该比控制器的极点要快才行。 现在参数矩阵L的求解又变成了极点配置问题! 根据经验来看,我们一般让观测器极点比控制器极点快4-10倍,但如果太快则可能会出现问题!至于为什么会出现这种现象呢?要想研究明白该问题我们就需要回去研究极点对系统的影响,实际上这也是控制论中的基本矛盾! 首先求得LQR控制器的极点,然后根据经验得到观测器极点配置信息,由此可得观测器的参数矩阵L。 这时,我们需要把状态反馈控制器和状态估计器结合起来:
 整理上式,得到完整的控制方程如下:
整理上式,得到完整的控制方程如下:
 为了便于控制,写成递推形式如下。 设置初始值为:
为了便于控制,写成递推形式如下。 设置初始值为:
 循环递推:
循环递推:
 OK!下面我们来看该系统在webots中的仿真。
OK!下面我们来看该系统在webots中的仿真。
4. webots中的仿真
在该系统中,我们有4个状态变量,即:
![]() 而我们假设速度信息无法采集,因此只在webots中获取位置信息即可,数据获取通过PositionSensor节点来实现。 我们的控制器仍用u=-kx实现,使用上次的LQR参数,设置R=1,Q矩阵如下:
而我们假设速度信息无法采集,因此只在webots中获取位置信息即可,数据获取通过PositionSensor节点来实现。 我们的控制器仍用u=-kx实现,使用上次的LQR参数,设置R=1,Q矩阵如下:
 计算得到,K=[ -31.6228 -26.4636 236.8730 67.2227] 根据K值,得到LQR控制器的极点为eig(A-B*K)。
计算得到,K=[ -31.6228 -26.4636 236.8730 67.2227] 根据K值,得到LQR控制器的极点为eig(A-B*K)。
 从上可知最小极点为-3.397,我们让观测器极点为控制器极点的5倍(实际测试过程中发现,当设置为10倍时,系统极不稳定),那么观测器的极点可配置为P = [-16.9851 -17.9851 -18.9851 -19.9851]. 通过place命令得到L矩阵为:
从上可知最小极点为-3.397,我们让观测器极点为控制器极点的5倍(实际测试过程中发现,当设置为10倍时,系统极不稳定),那么观测器的极点可配置为P = [-16.9851 -17.9851 -18.9851 -19.9851]. 通过place命令得到L矩阵为:
 具体控制程序见第5部分,仿真效果如下:
具体控制程序见第5部分,仿真效果如下:

本文未给出全状态反馈LQR控制与基于状态观测器的LQR控制的效果对比,也未给出调参过程,具体对比情况还需屏幕前的你去尝试一下。
5. Demo程序
整体代码如下:
% MATLAB controller for Webots
% File: lqr_based_on_LSO_controller.m
desktop;
keyboard;
%% system model
% 系统动力学参数
m=2;
g=9.81;
I=1;
L=0.5;
% 状态空间模型
A = [0 1 0 0;
0 0 -m*g*L^2/I 0;
0 0 0 1;
0 0 m*g*L/I 0]
B = [0;
(I+m*L^2)/(I*m);
0;
L/I]
C = [1 0 0 0;
0 0 1 0]
D = [0;0];
% LQR参数求解
Q = C'*C;
Q(1,1) = 1000;
Q(3,3) = 100;
R = 1;
K = lqr(A,B,Q,R) % 状态反馈控制增益矩阵
% LQR system
Ac = [(A-B*K)];
Bc = [B];
Cc = [C];
Dc = [D];
% LQR控制器极点
poles = eig(Ac)
% 求LQR控制器的最小极点
minPoles = -min(abs(real(poles)))
% 根据控制器最小极点配置观测器极点
SoPoles = 5 * minPoles
P = [SoPoles,SoPoles-1,SoPoles-2,SoPoles-3]
L = place(A',C',P)'
TIME_STEP = wb_robot_get_basic_time_step();
linear_motor = wb_robot_get_device('lm');
rotational_motor = wb_robot_get_device('rm');
linear_position_sensor = wb_robot_get_device('lps');
wb_position_sensor_enable(linear_position_sensor, TIME_STEP);
position_sensor = wb_robot_get_device('rps');
wb_position_sensor_enable(position_sensor, TIME_STEP);
wb_motor_set_force(linear_motor, 0);
wb_motor_set_torque(rotational_motor, 0);
% 观测器初始值设置
dt = TIME_STEP/1000;
wb_robot_step(TIME_STEP)
x = wb_position_sensor_get_value(linear_position_sensor)
q = wb_position_sensor_get_value(position_sensor)
u = 0;
hat_x = zeros(4,1);
hat_y = zeros(2,1);
y=[x;q];
%% control loop
while wb_robot_step(TIME_STEP) ~= -1
time = wb_robot_get_time();
x = wb_position_sensor_get_value(linear_position_sensor);
q = wb_position_sensor_get_value(position_sensor);
% 状态观测器
y = [x;q]
err = y - hat_y
dot_hat_x = A * hat_x + L * err + B * u
hat_x = hat_x + dot_hat_x * dt
hat_y = C * hat_x + D * u
% 反馈控制器
u = -K*hat_x;
wb_motor_set_force(linear_motor, u);
end
小结
最后小结一下: (1)调参过程实际上是最麻烦的! (2)理论与实际工程实施中有很大差别,理论上可行但现实中不一定可行! (3)webots中,获取传感器的值时必须要保证模拟器仿真至少进行了一次,即一个step! 今天的内容我们就先讲到这儿,下期预告:我们将实现高效的simulink与webots的联合仿真,将是全网最新解决方案噢!
 读万卷书也要行万里路,我是罗伯特祥,下次见!
读万卷书也要行万里路,我是罗伯特祥,下次见!