分上下篇吧,一共有七八十个公式呢 ^-^ 写在一篇就太长了
基于优化的 IMU 与视觉信息融合(上篇)") 大批公式预警!
大批公式预警!
基于优化的 IMU 与视觉信息融合(上篇)")
基于 Bundle Adjustment 的 VIO 融合
视觉 SLAM 里的 Bundle Adjustment 问题
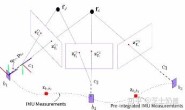
↓下图选自 SBA: A Software Package for Generic Sparse Bundle Adjustment [1],g2o和ceres都与SBA紧密联系,感兴趣的可以看下reference里面的论文。
基于优化的 IMU 与视觉信息融合(上篇)") 已知 1) 状态量初始值(特征点的三维坐标,相机的位姿);2) 系统测量值(特征点在不同图像上的图像坐标)。构建误差函数,利用最小二乘得到状态量的最优估计:
已知 1) 状态量初始值(特征点的三维坐标,相机的位姿);2) 系统测量值(特征点在不同图像上的图像坐标)。构建误差函数,利用最小二乘得到状态量的最优估计:
基于优化的 IMU 与视觉信息融合(上篇)")
是旋转四元数;
是平移向量;
是特征点 3D 坐标;
是第 i 个相机坐标系;
是投影函数;
是
对
的观测;
是
范数。
最小二乘问题的求解
最小二乘基础概念
找到一个
维的变量
,使得损失函数
取局部最小值:
基于优化的 IMU 与视觉信息融合(上篇)")
其中
是残差函数,比如测量值和预测值之间的差,且有
。局部最小值指对任意
有
。 假设损失函数
基于优化的 IMU 与视觉信息融合(上篇)")
其中
和
分别为损失函数
对变量
的一阶导和二阶导矩阵(Jacobian 和 Hessian)。 忽略泰勒展开的高阶项,损失函数变成了二次函数,可以得到如下性质: 如果在点
处有导数为 0,则称这个点为稳定点。在点
处对应的 Hessian 为
:
- 如果是正定矩阵,即它的特征值都大于0,则在
处有
为局部最小值;
- 如果是负定矩阵,即它的特征值都小于0,则在
- 如果是不定矩阵,即它的特征值大于0也有小于0的,则
迭代下降法求解:下降法
找一个下降方向使损失函数随
的迭代逐渐减小,直到
收敛到
:
基于优化的 IMU 与视觉信息融合(上篇)")
分两步:1)找下降方向的单位向量
;2)确定下降步长
。 假设
足够小,那么对损失函数
进行一阶泰勒展开:
基于优化的 IMU 与视觉信息融合(上篇)")
只需寻找下载方向,满足:
通过 line search 方法找到下载的步长:
基于优化的 IMU 与视觉信息融合(上篇)")
最速下降法:适用于迭代的开始阶段
从下降方向的条件可知:
,
表示下降方向和梯度方向的夹角。当
,有
,即梯度的负方向为最速下降方向。缺点是:最优值附近震荡 zigzag,收敛慢。
牛顿法:适用于最优值附近
在局部最优点
附近,如果
是最优解,则损失函数对
的导数等于 0,对公式(2)取一阶导有:
基于优化的 IMU 与视觉信息融合(上篇)")
基于优化的 IMU 与视觉信息融合(上篇)")
得到:
。缺点:二阶导矩阵计算复杂。
阻尼法 Damp Method
将损失函数的二阶泰勒展开记作:
基于优化的 IMU 与视觉信息融合(上篇)")
求以下函数的最小化:
基于优化的 IMU 与视觉信息融合(上篇)")
其中,
为阻尼因子,
是惩罚项,目的是限制
使它不能过大。 对新的损失函数求一阶导,并令其等于 0 有:
基于优化的 IMU 与视觉信息融合(上篇)")
符号说明
为了公式约简,可将残差组合成向量的形式:
基于优化的 IMU 与视觉信息融合(上篇)")
则有:
基于优化的 IMU 与视觉信息融合(上篇)")
同理,如果记
则有:
基于优化的 IMU 与视觉信息融合(上篇)")
高斯牛顿法 Gauss-Newton Method
残差函数
为非线性函数,对其一阶泰勒近似有:
基于优化的 IMU 与视觉信息融合(上篇)")
带入损失函数:
基于优化的 IMU 与视觉信息融合(上篇)")
这样损失函数就近似成了一个二次函数,而且如果雅可比是满秩的,则
正定,损失函数有最小值(半正定会使得
有非零
使得等式成立,而正定会仅有
)。另外,有:
,以及
。 令公式(7)的一阶导等于 0,得到:
基于优化的 IMU 与视觉信息融合(上篇)")
上式就是通常论文中看到的
,称其为 normal equation。
LM – 列文伯格马夸尔特算法(The Levenberg-Marquardt Method)
对高斯牛顿法进行了改进,求解过程中引入了阻尼因子:
基于优化的 IMU 与视觉信息融合(上篇)")
阻尼因子的作用
正定,迭代朝着下降方向进行。
非常大,则
,接近最速下降法。
,接近高斯牛顿法。
阻尼因子初始值的选取
阻尼因子
大小是相对于
的元素而言的。半正定的信息矩阵
特征值
和对应的特征向量
。对
做特征值分解后有:
可得:
基于优化的 IMU 与视觉信息融合(上篇)")
所以,一个简单的
初始值的策略就是:
基于优化的 IMU 与视觉信息融合(上篇)")
通常,按需设定
,由于每次求算
的特征值的最大值添加了很大计算量。那么
即取出
对角线上的最大值,其与特征值的最大值同一数量级。
阻尼因子
定性分析
- 如果
,则
,增大阻尼减小步长,拒绝本次迭代。
- 如果
,则
,减小阻尼增大步长,加快收敛,减少迭代次数。
定量分析
基于优化的 IMU 与视觉信息融合(上篇)")
此公式表示 实际下降/近似下降。 其中:
基于优化的 IMU 与视觉信息融合(上篇)")
这也是 SBA 控制因子
的来源。
Marquardt 策略
首先比例因子分母始终大于 0,如果:
,则
,应该
,增大阻尼减小步长。
- 如果
,让 LM 接近 Gauss-Newton 使得系统更快收敛。二阶收敛可以理解为用二次函数拟合曲线。
- 反之,如果是比较小的正数,则增大阻尼
1963年 Marquardt 提出了如下的阻尼策略:
基于优化的 IMU 与视觉信息融合(上篇)")
Nielsen 策略(被 g2o,ceres 采用)
基于优化的 IMU 与视觉信息融合(上篇)")
其实就是在下降时,如果实际误差变化小于模型误差,
会取到
变大,使得步长小一点;如果实际误差变化大于模型误差,
会取到
,步长大一点更快收敛。当误差上升,因为
的分母是
而且如果持续上升就会一直以指数增大,使得步长很小,放弃该步拟合。
鲁棒核函数的实现
引言:最小二乘遇到 outlier 怎么处理?核函数如何在代码中实现?有很多方法[2],这里介绍 g2o 和 ceres 中使用的 Triggs Correction[3]。 鲁棒核函数直接作用残差
上,最小二乘函数变成了如下形式:
基于优化的 IMU 与视觉信息融合(上篇)")
将误差的平方项记作
,则鲁棒核误差函数进行二阶泰勒展开有:
基于优化的 IMU 与视觉信息融合(上篇)")
上述函数中
的计算稍微复杂一点:
基于优化的 IMU 与视觉信息融合(上篇)")
公式(15)代入公式(14)有:
基于优化的 IMU 与视觉信息融合(上篇)")
对公式(16)求和后,对变量
求导,令其等于 0,得到:
基于优化的 IMU 与视觉信息融合(上篇)")
Example: Cauchy Cost Function
IRLS
柯西鲁棒核函数的定义为:
基于优化的 IMU 与视觉信息融合(上篇)")
其中
为控制参数。对
的一阶导和二阶导为:
基于优化的 IMU 与视觉信息融合(上篇)")
Huber 核:
基于优化的 IMU 与视觉信息融合(上篇)")
核函数控制参数的设定
95% efficiency rule (Huber,1981) : it provides an asymptotic efficiency 95% that of linear regression for the normal distribution.[4]
基于优化的 IMU 与视觉信息融合(上篇)")
- 如果残差
是正态分布,Huber
,Cauchy
。
- 如果残差非正态分布,需估计残差方差,然后对残差归一化。median absolute residual 方法
。
这里正态分布是 DVO、SVO等算法早期把所有残差项都拿出来做一个统计,求出一个近似的方差,然后通过这个方差做一个 robust kernel 的处理。
Vector3D rho; // 用来保存鲁棒核函数,一阶导,二阶导
// rho[0] = rho(sq_norm), //sq_norm 均方差指的是f^T*f
// rho[1] = rho'(sq_norm),
// rho[2] = rho''(sq_norm),
this->robustKernel()->robustify(error,rho);
InformationType weightedOmega = this->robustInformation(rho);
omega_r *= rho[1]; // 公式中的 rho'(r^2) * r。omega_r就是r,*=一个rho的一阶导rho'
from->b().noalias() += A.transpose() * omega_r; // 公式中的 b = -rho'(r^2) * r^T * J。A是雅可比J
// noalias()用来解决混淆问题,alias在英语里是别名的意思
from->A().noalias() += A.transpose() * weightedOmega * A; // 公式中的 J^T * W * J
代码中,基本和前段的(17)推导一致,robustinformation()函数在base_edge.h中进行了实现:
InformationType robustInformation(const Vector3D& rho)
{
// _information 可以k看做单位矩阵
InformationType result = rho[1] * _information;
// 计算权重 w = rho' + 2 * rho'' * r * r^T
// 但是不知道作者为啥注释了这段代码,也就是变成了 w = rho' 应该是把二阶近似省略了
//ErrorVector weightedError = _information * _error;
//result.noalias() += 2 * rho[2] * (weightedError * weightedError.transpose());
return result;
}
参考
- ^SBA: A Software Package for Generic Sparse Bundle Adjustment http://users.ics.forth.gr/~lourakis/sba/sba-toms.pdf
- ^Zach C . Robust Bundle Adjustment Revisited[J]. 2014. http://vigir.missouri.edu/~gdesouza/Research/Conference_CDs/ECCV_2014/papers/8693/86930772.pdf
- ^Bill Triggs et al. “Bundle adjustment – a modern synthesis”. In: International workshop on vision algorithms. Springer. 1999. pp. 298-372. https://www.cct.lsu.edu/~kzhang/papers/BundleAdjustment.pdf
- ^Kirk MacTavish and Timothy D Barfoot. “At all Costs: A Comparison of Robust Cost Functions for Camera Correspondence Outliers”. In: 2015 12th Conference on Computer and Robot Vision. IEEE, 2015, pp 62-69. http://ncfrn.mcgill.ca/members/pubs/AtAllCosts_mactavish_crv15.pdf