文章目录
- 模型概要
-
- 1、状态、决策空间(略)
- 2、奖励函数
- 3、决策模型
模型概要
1、状态、决策空间(略)
状态空间:roll(X轴)、pitch(Y轴),以及沿这两个轴的角速度。 注意,状态空间中并没有使用所有可用的传感器测量值。例如,IMU还提供了基体的偏移(即x,y方向的偏移),有些imu还会提供加速度,这些我们都不考虑。我们排除这些值,是因为imu的数值会存在漂移(误差),使用的数据越多,最终我们的决策模型转移到现实当中时就会越大,紧凑的观察空间有助于将策略转移到真实的机器人上。最重要的是经过实验,研究人员发现只含这四个值的状态空间已经足够本文所演示的训练任务了。
")
2、奖励函数
") pn、pn-1 为当前位置和上一位置, d是期望运动方向, ∆t为步长时间, τ为电机扭矩, q为点击速度, w为权重值 第一项是评判移动距离,第二项是能量消耗,w用于平衡这两项奖励,我们来看一看pybullet中minitaur_gym 奖励函数实现: 初始权重值:
pn、pn-1 为当前位置和上一位置, d是期望运动方向, ∆t为步长时间, τ为电机扭矩, q为点击速度, w为权重值 第一项是评判移动距离,第二项是能量消耗,w用于平衡这两项奖励,我们来看一看pybullet中minitaur_gym 奖励函数实现: 初始权重值:
distance_weight=1.0,
energy_weight=0.005,
shake_weight=0.0,
drift_weight=0.0,函数:
def _reward(self):
# 获取当前位置
current_base_position = self.minitaur.GetBasePosition()
# 计算前进距离
forward_reward = current_base_position[0] - self._last_base_position[0]
# Cap the forward reward if a cap is set.
forward_reward = min(forward_reward, self._forward_reward_cap)
# 计算Y轴偏移
drift_reward = -abs(current_base_position[1] - self._last_base_position[1])
# 获取旋转角度(四元素)
orientation = self.minitaur.GetBaseOrientation()
# 将四元素转成旋转矩阵,在pybullet中用一个长度为9的列表表示
rot_matrix = pybullet.getMatrixFromQuaternion(orientation)
# 取最后旋转矩阵最后一行
local_up_vec = rot_matrix[6:]
shake_reward = -abs(np.dot(np.asarray([1, 1, 0]), np.asarray(local_up_vec)))
# 计算能量消耗
energy_reward = -np.abs(
np.dot(self.minitaur.GetMotorTorques(),
self.minitaur.GetMotorVelocities())) * self._time_step
objectives = [forward_reward, energy_reward, drift_reward, shake_reward]
# 每一项再乘以权重得到最终奖励值
weighted_objectives = [o * w for o, w in zip(objectives, self._objective_weights)]
reward = sum(weighted_objectives)
self._objectives.append(objectives)
return reward
3、决策模型
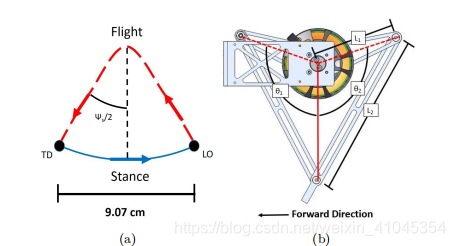
尽管从头开始学习可以降低对人门对专业知识的需求,有时还可以获得更好的性能,但是控制所学习的策略对于机器人应用程序同样非常重要。例如,我们可能需要指定步态的细节(例如不同步态或离地距离)。因此,我们将运动控制器解耦为两个部分,一个是允许用户提供参考轨迹的开环组件,另一个是基于状态调整腿部姿势的反馈组件。
")
")
def _gen_signal(self, t, phase):
"""Generates a sinusoidal reference leg trajectory.
The foot (leg tip) will move in a ellipse specified by extension and swing
amplitude.
Args:
t: Current time in simulation.
phase: The phase offset for the periodic trajectory.
Returns:
The desired leg extension and swing angle at the current time.
"""
period = 1 / self._step_frequency
extension = self._extension_amplitude * math.cos(2 * math.pi / period * t + phase)
swing = self._swing_amplitude * math.sin(2 * math.pi / period * t + phase)
return extension, swing 其中step__frequency用于控制minitaur的前进速度。 如果我们想完全使用指定的决策,我们可以把π(o)的上界和下界设置为零。如果我们想要一个决策是从头开始学,我们可以设置一个aˉ(t)=0,给反馈组件π(o)一个较大的输出范围。π(o)部分可以使用ppo算法实现,研究人员给出以下参数作为参考。该神经网络具有两个完全连通的隐层。其大小是通过超参数搜索确定的。
| 步态 | 状态空间 | 决策网络 | 价值网络 |
|---|---|---|---|
| trot | 4 | [125, 89] | [89, 55] |
| bound | 12 | [185, 95] | [95, 85] |
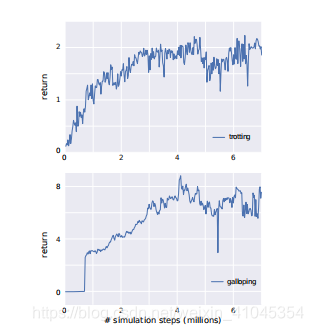
效果如下: