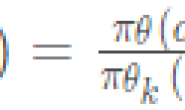文章目录
- 一、PPO主体
-
- 1、主结构
- 2、初始化部分
- 3、训练部分
- 二、环境交互
-
- 1、 交互部分主结构
- 2、初始化部分
- 3、调用
- 4、计算adv
- 5、检验函数
- 三、 run_ppo
一、PPO主体
1、主结构
PPO主体主要分为两个部分,初始化部分init用来设定网络的一些超参数,以及构建网络,第二部分train则用于更新网络参数(实际代码中,该PPO主体继承自另外一个主要用于设定超参数的类)。
class PPO():
def __init__(...):
pass
def train(self, states, actions, advantages, logp_olds, returns):
pass
2、初始化部分
根据动作类型选取合适的网络模型,关于不同网络模型的代码实现参考上一篇文章
def __init__(
self,
state_shape,
action_dim,
is_discrete,
max_action=1.,
actor_units=[256, 256],
critic_units=[256, 256],
lr_actor=1e-3,
lr_critic=3e-3,
const_std=0.3,
hidden_activation_actor="relu",
hidden_activation_critic="relu",
clip_ratio=0.2,
name="PPO",
**kwargs):
super().__init__(name=name, **kwargs)
self.clip_ratio = clip_ratio
self._is_discrete = is_discrete
# 创建网络模型
if is_discrete:
self.actor = CategoricalActor(
state_shape, action_dim, actor_units)
else:
self.actor = GaussianActor(
state_shape, action_dim, max_action, actor_units,
hidden_activation=hidden_activation_actor,
const_std=const_std)
self.critic = CriticV(state_shape, critic_units,
hidden_activation=hidden_activation_critic)
# 创建优化器
self.actor_optimizer = tf.keras.optimizers.Adam(
learning_rate=lr_actor)
self.critic_optimizer = tf.keras.optimizers.Adam(
learning_rate=lr_critic)
# This is used to check if input state to `get_action` is multiple (batch) or single
self._state_ndim = np.array(state_shape).shape[0]
3、训练部分
a、训练actor 因为这里actor跟critic分开两个网络进行,不共享网络参数,因此将value_loss独立开单独进行梯度计算,因此损失函数用以下公式表示(c2取0.01):
") 代码如下:
代码如下:
@tf.function
def _train_actor_body(self, states, actions, advantages, logp_olds):
with tf.device(self.device):
# Update actor
with tf.GradientTape() as tape:
# 计算熵
ent = tf.reduce_mean(
self.actor.compute_entropy(states))
if self.clip:
# 计算新策略的概率
logp_news = self.actor.compute_log_probs(
states, actions)
# 计算概率比例
ratio = tf.math.exp(logp_news - tf.squeeze(logp_olds))
# 对比例进行裁剪
min_adv = tf.clip_by_value(
ratio,
1.0 - self.clip_ratio,
1.0 + self.clip_ratio) * tf.squeeze(advantages)
# loss = (l_clip + entropy)
actor_loss = -tf.reduce_mean(tf.minimum(
ratio * tf.squeeze(advantages),
min_adv))
actor_loss -= self.entropy_coef * ent
else:
raise NotImplementedError
actor_grad = tape.gradient(
actor_loss, self.actor.trainable_variables)
self.actor_optimizer.apply_gradients(
zip(actor_grad, self.actor.trainable_variables))
return actor_loss, logp_news, ratio, ent熵值的计算:
def compute_entropy(self, state):
param = self._compute_dist(states)
log_stds = param["log_std"]
return tf.reduce_sum(log_stds + tf.math.log(tf.math.sqrt(2 * np.pi * np.e)), axis=-1)
b、训练critic
") 其中T指的是该序列τ 的长度,代码如下:
其中T指的是该序列τ 的长度,代码如下:
@tf.function
def _train_critic_body(self, states, returns):
with tf.device(self.device):
# Train baseline
with tf.GradientTape() as tape:
current_V = self.critic(states)
td_errors = tf.squeeze(returns) - current_V
critic_loss = tf.reduce_mean(0.5 * tf.square(td_errors))
critic_grad = tape.gradient(
critic_loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(
zip(critic_grad, self.critic.trainable_variables))
return critic_loss
二、环境交互
1、 交互部分主结构
class OnPolicyTrainer(object):
def __init__(self,...):
'''
初始化训练参数,导入环境,policy等
'''
pass
def __call__(self):
'''
主循环,采集数据,更新网络
'''
pass
def finish_horizon(self, last_val=0):
'''
每一个序列T采集完的时候调用
用于计算adv,存储buffer
'''
pass
def evaluate_policy(self, total_steps):
'''
用于检验决策模型得分
'''
pass
def _set_from_args(self, args):
'''
设置参数
'''
pass
@staticmethod
def get_argument(parser=None):
'''
获取参数
'''
pass
2、初始化部分
def __init__(self, policy,
env,
args,
test_env=None):
self._set_from_args(args)
self._policy = policy
self._env = env
self._test_env = self._env if test_env is None else test_env
# 正则化状态
# obs-mean/(var+ 1e8)
if self._normalize_obs:
self._env = NormalizeObsEnv(self._env)
self._test_env = NormalizeObsEnv(self._test_env)
...
# 省略部分用于监测数据的代码
...
3、调用
ppo2算法里面,规定序列T 长度,即每一轮的最大步数,当步数达到最大值或者该轮结束时,通过以下式子进行网络更新,其中k⊆[0,T−1]
") buffer的存储调用利用cpprb库提供的api实现。回调函数如下
buffer的存储调用利用cpprb库提供的api实现。回调函数如下
def __call__(self):
# 准备每一轮更新用的buffer
# Prepare buffer
self.replay_buffer = get_replay_buffer(
self._policy, self._env)
kwargs_local_buf = get_default_rb_dict(
size=self._policy.horizon, env=self._env)
kwargs_local_buf["env_dict"]["logp"] = {}
kwargs_local_buf["env_dict"]["val"] = {}
if is_discrete(self._env.action_space):
kwargs_local_buf["env_dict"]["act"]["dtype"] = np.int32
self.local_buffer = ReplayBuffer(**kwargs_local_buf)
episode_steps = 0
episode_return = 0
episode_start_time = time.time()
total_steps = np.array(0, dtype=np.int32)
n_epoisode = 0
obs = self._env.reset()
tf.summary.experimental.set_step(total_steps)
while total_steps < self._max_steps:
# Collect samples
for _ in range(self._policy.horizon):
act, logp, val = self._policy.get_action_and_val(obs)
next_obs, reward, done, _ = self._env.step(act)
episode_steps += 1
total_steps += 1
episode_return += reward
done_flag = done
if hasattr(self._env, "_max_episode_steps") and \
episode_steps == self._env._max_episode_steps:
done_flag = False
self.local_buffer.add(
obs=obs, act=act, next_obs=next_obs,
rew=reward, done=done_flag, logp=logp, val=val)
obs = next_obs
if done or episode_steps == self._episode_max_steps:
tf.summary.experimental.set_step(total_steps)
self.finish_horizon()
obs = self._env.reset()
n_epoisode += 1
fps = episode_steps / (time.time() - episode_start_time)
self.logger.info(
"Total Epi: {0: 5} Steps: {1: 7} Episode Steps: {2: 5} Return: {3: 5.4f} FPS: {4:5.2f}".format(
n_epoisode, int(total_steps), episode_steps, episode_return, fps))
episode_steps = 0
episode_return = 0
episode_start_time = time.time()
self.finish_horizon(last_val=val)
tf.summary.experimental.set_step(total_steps)
# 更新参数
if self._policy.normalize_adv:
samples = self.replay_buffer._encode_sample(np.arange(self._policy.horizon))
mean_adv = np.mean(samples["adv"])
std_adv = np.std(samples["adv"])
with tf.summary.record_if(total_steps % self._save_summary_interval == 0):
for _ in range(self._policy.n_epoch):
samples = self.replay_buffer._encode_sample(
np.random.permutation(self._policy.horizon))
if self._policy.normalize_adv:
adv = (samples["adv"] - mean_adv) / (std_adv + 1e-8)
else:
adv = samples["adv"]
for idx in range(int(self._policy.horizon / self._policy.batch_size)):
target = slice(idx * self._policy.batch_size,
(idx + 1) * self._policy.batch_size)
self._policy.train(
states=samples["obs"][target],
actions=samples["act"][target],
advantages=adv[target],
logp_olds=samples["logp"][target],
returns=samples["ret"][target])
4、计算adv
在ppo2里面,优势值通过以下方式计算:
")
def finish_horizon(self, last_val=0):
samples = self.local_buffer._encode_sample(
np.arange(self.local_buffer.get_stored_size()))
rews = np.append(samples["rew"], last_val)
vals = np.append(samples["val"], last_val)
# GAE-Lambda advantage calculation
deltas = rews[:-1] + self._policy.discount * vals[1:] - vals[:-1]
if self._policy.enable_gae:
advs = discount_cumsum(
deltas, self._policy.discount * self._policy.lam)
else:
advs = deltas
# Rewards-to-go, to be targets for the value function
rets = discount_cumsum(rews, self._policy.discount)[:-1]
self.replay_buffer.add(
obs=samples["obs"], act=samples["act"], done=samples["done"],
ret=rets, adv=advs, logp=np.squeeze(samples["logp"]))
self.local_buffer.clear()其中,discount_cumsum函数用以下方式实现
def discount_cumsum(x, discount):
"""
Forked from rllab for computing discounted cumulative sums of vectors.
:param x (np.ndarray or tf.Tensor)
vector of [x0, x1, x2]
:return output:
[x0 + discount * x1 + discount^2 * x2,
x1 + discount * x2,
x2]
"""
return lfilter(
b=[1],
a=[1, float(-discount)],
x=x[::-1],
axis=0)[::-1]
5、检验函数
def evaluate_policy(self, total_steps):
if self._normalize_obs:
self._test_env.normalizer.set_params(
*self._env.normalizer.get_params())
avg_test_return = 0.
if self._save_test_path:
replay_buffer = get_replay_buffer(
self._policy, self._test_env, size=self._episode_max_steps)
for i in range(self._test_episodes):
episode_return = 0.
frames = []
obs = self._test_env.reset()
for _ in range(self._episode_max_steps):
act, _ = self._policy.get_action(obs, test=True)
act = act if not hasattr(self._env.action_space, "high") else \
np.clip(act, self._env.action_space.low, self._env.action_space.high)
next_obs, reward, done, _ = self._test_env.step(act)
if self._save_test_path:
replay_buffer.add(
obs=obs, act=act, next_obs=next_obs,
rew=reward, done=done)
episode_return += reward
obs = next_obs
if done:
break
prefix = "step_{0:08d}_epi_{1:02d}_return_{2:010.4f}".format(
total_steps, i, episode_return)
return avg_test_return / self._test_episodes
三、 run_ppo
导入相关模块。utils主要涵盖了一些琐碎的功能,例如跟环境相关的。
import tensorflow as tf
from ppo import PPO
from on_policy_trainer import OnPolicyTrainer
from utils import is_discrete, get_act_dim主程序,先从trainer那里获取默认的超参数,然后设定跟训练集测试集相关的参数。ppo算法的是随机连续决策算法,根据openAI官方推荐,其模型输出的方差不是一个函数并且与环境无关。
官方说法: There is a single vector of log standard deviations,logσ, which is not a function of state: the log σ are standalone parameters. (You Should Know: our implementations of VPG, TRPO, and PPO do it this way.)
if __name__ == '__main__':
parser = OnPolicyTrainer.get_argument()
parser = PPO.get_argument(parser)
parser.add_argument('--env-name', type=str,
default="Pendulum-v0")
parser.set_defaults(test_interval=20480)
parser.set_defaults(max_steps=int(1e7))
parser.set_defaults(horizon=2048)
parser.set_defaults(batch_size=64)
parser.set_defaults(gpu=-1)
parser.set_defaults(episode_max_steps=200)
args = parser.parse_args()
env = gym.make(args.env_name)
test_env = gym.make(args.env_name)
policy = PPO(
state_shape=env.observation_space.shape,
action_dim=get_act_dim(env.action_space),
is_discrete=is_discrete(env.action_space),
max_action=None if is_discrete(
env.action_space) else env.action_space.high[0],
batch_size=args.batch_size,
actor_units=[128, 64],
critic_units=[128, 64],
n_epoch=10,
n_epoch_critic=10,
lr_actor=3e-4,
lr_critic=3e-4,
discount=0.99,
lam=0.95,
hidden_activation=tf.nn.relu,
horizon=args.horizon,
normalize_adv=args.normalize_adv,
enable_gae=args.enable_gae,
gpu=args.gpu)
trainer = OnPolicyTrainer(policy, env, args)
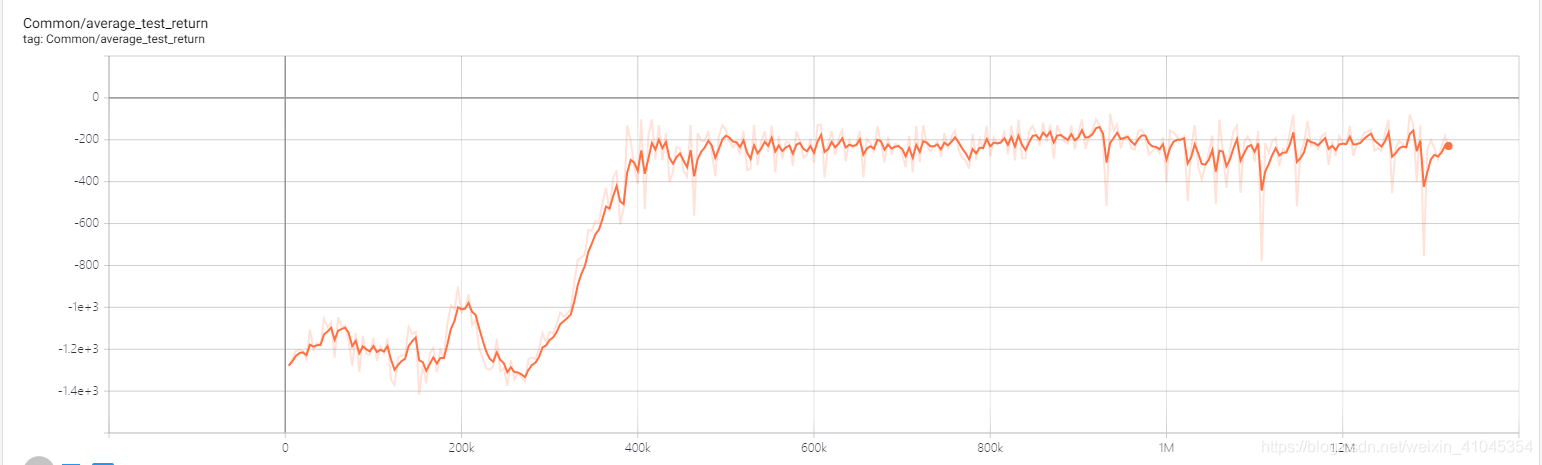
trainer() 最后来看下结果,大约在400k步的时候就开始收敛了,如果想收敛地更快可以自己尝试一下调整参数