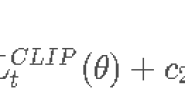文章目录
- 一、算法简介
-
- 1、关键点
-
-
- 1.1 损失函数的设计
- 1.2 优势函数设计
-
- 2、算法流程
- 3、代码结构
- 二、决策模型(policies)
-
- 1、确定性决策
- 2、随机决策
-
- 2.1 分类决策
-
- 2.1.1 创建模型
- 2.1.2 采样函数
- 2.1.3似然函数
- 2.2 连续决策(Diagonal Gaussian Policies)
-
- 2.2.1 模型创建
- 2.2.2 采样
- 2.2.3 似然函数
在上一篇强化学习应该知道的一些概念当中我们已经介绍了许多相关理论要点以及给出部分公式,下面就结合相关代码进行实践,由于篇幅过长,会分为两部分(或以上)进行讲解。
另外,可能有些地方名字不一样但指的是同一个东西的地方也请大家见谅,因为很多专业名词都暂时没有找到相关的翻译,后续会慢慢更改的~
一、算法简介
PPO受到与TRPO相同的问题的启发:我们如何才能使用当前拥有的数据在策略上采取最大可能的改进步骤,而又不会走得太远而导致意外导致性能下降?在TRPO试图通过复杂的二阶方法解决此问题的地方,PPO使用的是一阶方法,它使用其他一些技巧来使新策略接近于旧策略。PPO方法实施起来非常简单,而且从经验上看,其性能至少与TRPO相同。其次PPO算法也是AC架构。 PPO有两种主要形式:PPO-Penalty和PPO-Clip。 PPO-Penalty:近似地解决了TRPO之类的受KL约束的更新,但对目标函数中的KL偏离进行了惩罚而不是使其成为硬约束,并在训练过程中自动调整惩罚系数,以便对其进行适当缩放。 PPO-Clip:在目标中没有KL散度项,也完全没有约束。取而代之的是依靠对目标函数的专门裁剪来减小新老策略的差异。 在这里,我们只讨论PPO-Clip(OpenAI使用的主要形式)。 OPENAI的baseline里面有两个版本的ppo算法,安装他们的注释,ppo2应该才是正式版,其实两者差别不大,主要体现在算法的优化上面,基本思想还是限制新老策略的差别以防更新过快。
1、关键点
1.1 损失函数的设计
ppo算法最精髓的地方就是加入了一项比例用以描绘新老策略的差异,用
![]() 表示,损失函数如下:
表示,损失函数如下:
") 其中,ϵ是一个(很小的)超参数,用以粗略限制r ( θ )的变化范围。为了表达方便,我们将上面将该损失函数用L c l i p ( θ )表示 在ppo2里面,如果critic和actor共享参数的话,损失函数定义为如下:
其中,ϵ是一个(很小的)超参数,用以粗略限制r ( θ )的变化范围。为了表达方便,我们将上面将该损失函数用L c l i p ( θ )表示 在ppo2里面,如果critic和actor共享参数的话,损失函数定义为如下:
") 其中,c 1 , c 2是一个系数,S用于计算熵值,L V F是value函数的损失函数,形式为:( V θ ( s t ) − V t t a r g e t ) 2
其中,c 1 , c 2是一个系数,S用于计算熵值,L V F是value函数的损失函数,形式为:( V θ ( s t ) − V t t a r g e t ) 2
1.2 优势函数设计
给定长度为T的序列,t作为时间[ 0 , T ] 的下标
![]() 其中,
其中,
![]()
2、算法流程
PPO1的算法流程,ppo2里面大同小异,只是替换了里面某些公式。
")
3、代码结构
- 根据动作类型创建决策网络
- 计算loss
- 环境交互以及参数更新
class PPO(OnPolicyAgent):
def __init__(
self,
state_shape,
action_dim,
is_discrete,
max_action=1.,
actor_units=[256, 256],
critic_units=[256, 256],
lr_actor=1e-3,
lr_critic=3e-3,
const_std=0.3,
hidden_activation_actor="relu",
hidden_activation_critic="relu",
clip=True,
clip_ratio=0.2,
name="PPO",
**kwargs):
super().__init__(name=name, **kwargs)
self.clip = clip
self.clip_ratio = clip_ratio
self._is_discrete = is_discrete
if is_discrete:
self.actor = CategoricalActor(
state_shape, action_dim, actor_units)
else:
self.actor = GaussianActor(
state_shape, action_dim, max_action, actor_units,
hidden_activation=hidden_activation_actor,
const_std=const_std)
self.critic = CriticV(state_shape, critic_units,
hidden_activation=hidden_activation_critic)
self.actor_optimizer = tf.keras.optimizers.Adam(
learning_rate=lr_actor)
self.critic_optimizer = tf.keras.optimizers.Adam(
learning_rate=lr_critic)
# This is used to check if input state to `get_action` is multiple (batch) or single
self._state_ndim = np.array(state_shape).shape[0]
def train(self, states, actions, advantages, logp_olds, returns):
# Train actor and critic
actor_loss, logp_news, ratio, ent = self._train_actor_body(
states, actions, advantages, logp_olds)
critic_loss = self._train_critic_body(states, returns)
return actor_loss, critic_loss
@tf.function
def _train_actor_critic_body(
pass
@tf.function
def _train_actor_body(self, states, actions, advantages, logp_olds):
pass
@tf.function
def _train_critic_body(self, states, returns):
pass
def get_action(self, state, test=False):
pass
def get_action_and_val(self, state, test=False):
pass
@tf.function
def _get_action_logp_v_body(self, state, test):
pass
二、决策模型(policies)
决策模型根据动作值是否由网络直接输出分为两种类型:确定性决策、随机决策。就流程上而言,随机决策的网络部分是跟确定性决策一致,而后者则少了采样、似然函数所引申出来的相关功能函数,因此本篇主要针对随机决策进行讨论
1、确定性决策
动作值直接由网络生成,其形式可以表达为:
![]()
2、随机决策
随机决策根据动作连续与否分为分类决策和高斯决策,决策模型输出的是动作的概率分布。其形式如下:
![]() 不管是哪一种,都包含以下两个技术要点:
不管是哪一种,都包含以下两个技术要点:
- 对动作进行采样
- 计算动作的似然函数
2.1 分类决策
分类决策网络输出层的激活函数使用softmax,将logit转换为概率。所以该决策网络的输出就是各种可能动作的概率,是一组向量。如果动作为k维向量,输出即为每个动作发生的概率所组成的向量。
2.1.1 创建模型
代码如下,重写keras.Model类,默认情况下只有两个隐藏层。输入的是时间t tt的状态,输出动作,动作的概率(用字典表达),以及其对数概率,给出的代码里面省略了两个功能函数,往后会详谈。
class CategoricalActor(tf.keras.Model):
def __init__(self, state_shape, action_dim, units=[256, 256],
name="CategoricalActor"):
super().__init__(name=name)
self.dist = Categorical(dim=action_dim)
self.action_dim = action_dim
self.l1 = Dense(units[0], activation='relu')
self.l2 = Dense(units[1], activation='relu')
self.prob = Dense(action_dim, activation='softmax')
self(tf.constant(
np.zeros(shape=(1,)+state_shape, dtype=np.float32)))
def _compute_feature(self, states):
features = self.l1(states)
return self.l2(features)
def _compute_dist(self, states):
"""
Compute categorical distribution
:param states (np.ndarray or tf.Tensor): Inputs to neural network.
NN outputs probabilities of K classes
:return: Categorical distribution
"""
features = self._compute_feature(states)
probs = self.prob(features)
return {"prob": probs}
def call(self, states, test=False):
"""
Compute actions and log probability of the selected action
:return action (tf.Tensors): Tensor of actions
:return log_probs (tf.Tensor): Tensors of log probabilities of selected actions
"""
param = self._compute_dist(states)
if test:
action = tf.math.argmax(param["prob"], axis=1) # (size,)
else:
action = tf.squeeze(self.dist.sample(param), axis=1) # (size,)
log_prob = self.dist.log_likelihood(
tf.one_hot(indices=action, depth=self.action_dim), param)
return action, log_prob, param
def compute_entropy(self, states):
pass
def compute_log_probs(self, states, actions):
'''
该函数用于计算动作概率分布的似然函数,
在2.1.3里面有具体实现,这是只是实现了调用。故省略
'''
2.1.2 采样函数
根据概率分布随机选取一个特定的动作。probs是神经网络输出的动作概率分布,
def sample(self, param):
probs = param["prob"]
# 注意: `tf.random.categorical` 的输入是对数概率
# 文档https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/random/categorical
# 输出的形状[probs.shape[0], 1]
return tf.random.categorical(tf.math.log(probs), 1)
2.1.3似然函数
将动作概率分布转换成对数概率。其值是一个由对数概率所组成的向量。使用该函数前,需要对采样得到的动作进行one-hot编码,才能作为x输入。parm是一个字典,里面包含了动作概率分布。
![]()
def log_likelihood(self, x, param):
"""
Compute log likelihood as:
\log \sum(p_i * x_i)
:param x (tf.Tensor or np.ndarray): Values to compute log likelihood
:param param (Dict): Dictionary that contains probabilities of outputs
:return (tf.Tensor): Log probabilities
"""
probs = param["prob"]
assert probs.shape == x.shape, \
"Different shape inputted. You might have forgotten to convert `x` to one-hot vector."
return tf.math.log(tf.reduce_sum(probs * x, axis=1) + self._tiny)
2.2 连续决策(Diagonal Gaussian Policies)
高斯决策(连续决策)的特点是产生连续动作,其决策模型输出的是均值μ \muμ和对数方差log ( σ ) \log(\sigma)log(σ),其中对数方差有两种取值方式,一种是固定值,一种是由决策网络给出,下面我们只介绍第一种取值方法。(具体的理论部分可以去查看开头所引用的文章。)
2.2.1 模型创建
代码结构跟分类决策类似,主要是对象返回的内容不一样,这里返回的是动作值,其对数概率,以及字典保存的均值和方差
class GaussianActor(tf.keras.Model):
LOG_SIG_CAP_MAX = 2 # np.e**2 = 7.389
LOG_SIG_CAP_MIN = -20 # np.e**-10 = 4.540e-05
EPS = 1e-6
def __init__(self, state_shape, action_dim, max_action,
units=[256, 256], hidden_activation="relu",
const_std=0.1,
squash=False, name='GaussianPolicy'):
super().__init__(name=name)
self.dist = DiagonalGaussian(dim=action_dim)
self._const_std = const_std
self._max_action = max_action
self._squash = squash
self.l1 = keras.layers.Dense(units[0], name="L1", activation=hidden_activation)
self.l2 = keras.layers.Dense(units[1], name="L2", activation=hidden_activation)
self.out_mean = keras.layers.Dense(action_dim, name="L_mean")
self.out_log_std = tf.Variable(
initial_value=-0.5*np.ones(action_dim, dtype=np.float32),
dtype=tf.float32, name="logstd")
self(tf.constant(
np.zeros(shape=(1,)+state_shape, dtype=np.float32)))
def _compute_dist(self, states):
"""
Compute multivariate normal distribution
:param states (np.ndarray or tf.Tensor): Inputs to neural network.
NN outputs mean and standard deviation to compute the distribution
:return (Dict): Multivariate normal distribution
"""
features = self.l1(states)
features = self.l2(features)
mean = self.out_mean(features)
log_std = tf.ones_like(mean) * tf.math.log(self._const_std)
return {"mean": mean, "log_std": log_std}
def call(self, states, test=False):
"""
Compute actions and log probabilities of the selected action
"""
param = self._compute_dist(states)
if test:
raw_actions = param["mean"]
else:
raw_actions = self.dist.sample(param)
logp_pis = self.dist.log_likelihood(raw_actions, param)
actions = raw_actions
if self._squash:
actions = tf.tanh(raw_actions)
logp_pis = self._squash_correction(logp_pis, actions)
return actions * self._max_action, logp_pis, param
def compute_log_probs(self, states, actions):
'''
该功能函数用于计算似然函数,在2.2.3里面有具体实现,略
'''
def compute_entropy(self, states):
pass
def _squash_correction(self, logp_pis, actions):
pass
2.2.2 采样
给定输出动作的均值μ θ ( s )以及对数方差求动作最终输出值,其中z ∼ N ( 0 , 1 )
![]()
def sample(self, param):
means = param["mean"]
log_stds = param["log_std"]
# tf.math.exp : e^x
# log_std: ln (x)
# std = e^log_std
return means + tf.random.normal(shape=means.shape) * tf.math.exp(log_stds)
2.2.3 似然函数
对于k维动作a,其均值为μ = μ θ ( s ),方差为σ = σ θ ( s ),似然函数由以下公式给出:
")
def log_likelihood(self, x, param):
'''
parm同样是一个字典,记录了模型产生的均值和方差
'''
means = param["mean"]
log_stds = param["log_std"]
assert means.shape == log_stds.shape
zs = (x - means) / tf.exp(log_stds)
return - tf.reduce_sum(log_stds, axis=-1) \
- 0.5 * tf.reduce_sum(tf.square(zs), axis=-1) \
- 0.5 * self.dim * tf.math.log(2 * np.pi)
至此PPO算法的主体模型已经搭建完成,剩下的部分由于篇幅问题会放在下一篇中讲解,代码参考tf2rl开源强化学习库,ubuntu的小伙伴可以直接pip安装即可,window下想要安装可以参考这篇文章