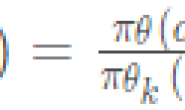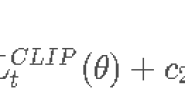前面两节讲完了critic、actor以及缓冲区的设计,下面就到了actor和critic的损失函数的环节了。对于神经网络来说,最重要的就是计算损失函数进行反向传播更新参数了。在计算损失函数之前,需要有batch的数据,所以上一节也把缓冲区的设计完成。这节完成损失函数的设计和整个PPO算法的更新。
价值函数的损失函数
价值函数的损失计算较为简单,我们一般使用当前obs的价值函数与reward-to-go的值进行差值平方取平均运算,即
def compute_loss_v(data):
obs, ret = data['obs'], data['ret']
ppo_logger.log("obs={},ret={},loss_v={}".format(obs,ret,((ac.v(obs) - ret) ** 2).mean()))
return ((ac.v(obs) - ret) ** 2).mean()
`
策略函数的损失函数
PPO的策略函数对应有两种形式:
(1)PPO-Penalty,对应的损失函数为")
其在损失函数中使用KL散度来作为损失函数中的惩罚项,而不是像CLIP形式那样进行严格的限制,这种惩罚形式类似TRPO的更新。
(2)PPO-Clip,其损失函数为")
它使用一个截断系数,来限制pi与pi old不会差别过大,因为pi的过大更新会导致难以收敛,同时,PPO算法为了提高数据的利用率,在新旧策略的更新上使用了相同的数据,虽然提高了样本利用率,但是由重要性采样可知,如果想对多个策略使用同样的数据进行参数更新,那么多个策略必须是相同的策略分布区间,所以PPO的clip达到了限制新旧策略差别过大的影响,即减小了由于策略分布不同而导致的更新错误。
在下面的实现中,我们使用Clip形式。这也是大多数算法库采用的形式。
ppo的策略函数的损失函数相对较为复杂,我们直接根据PPO的论文提供的损失函数来编写代码。
虽然PPO的原文使用的是下面这个较为复杂的公式")
即包含clip的损失,价值函数的损失和熵的损失,但是我们可以直接使用CLIP的损失即可,在达到近似的性能下计算开销更小。
在编写代码的时候,我们将CLIP 的公式稍微做一下简化,")
在代码实现中,我们同时实现了KL散度,但是不是作为损失函数的计算值,而是辅助更新作用,当当前的KL值大于1.5倍的target kl时,直接停止更新当前策略的参数,这对于限制策略的更新幅度同样起了作用。
def compute_loss_pi(data):
obs, act, adv, logp_old = data['obs'], data['act'], data['adv'], data['logp']
# Policy loss
pi, logp = ac.pi(obs, act)
ratio = torch.exp(logp - logp_old)
clip_adv = torch.clamp(ratio, 1 - clip_ratio, 1 + clip_ratio) * adv
loss_pi = -(torch.min(ratio * adv, clip_adv)).mean()
# Useful extra info
approx_kl = (logp_old - logp).mean().item()
ent = pi.entropy().mean().item()
clipped = ratio.gt(1 + clip_ratio) | ratio.lt(1 - clip_ratio)
clipfrac = torch.as_tensor(clipped, dtype=torch.float32).mean().item()
pi_info = dict(kl=approx_kl, ent=ent, cf=clipfrac)
return loss_pi, pi_info
下面,就只剩下PPO算法的更新过程了。
PPO更新策略参数
我们将根据这个算法流程来编写程序")
def update():
data = buf.get()
pi_l_old, pi_info_old = compute_loss_pi(data)
#ppo_logger.log("pi_l_old={},pi_info_old={}".format(pi_l_old,pi_info_old))
pi_l_old = pi_l_old.item()
v_l_old = compute_loss_v(data).item()
#ppo_logger.log("pi_l_old={},v_l_old={}".format(pi_l_old,v_l_old))
# Train policy with multiple steps of gradient descent
for i in range(train_pi_iters):
pi_optimizer.zero_grad()
loss_pi, pi_info = compute_loss_pi(data)
#ppo_logger.log("loss_pi={},pi_info={}".format(loss_pi,pi_info))
kl = mpi_avg(pi_info['kl'])
if kl > 1.5 * target_kl:
logger.log('Early stopping at step %d due to reaching max kl.' % i)
break
loss_pi.backward()
mpi_avg_grads(ac.pi) # average grads across MPI processes
pi_optimizer.step()
logger.store(StopIter=i)
# Value function learning
for i in range(train_v_iters):
vf_optimizer.zero_grad()
loss_v = compute_loss_v(data)
ppo_logger.log("loss_v={}".format(loss_v))
loss_v.backward()
mpi_avg_grads(ac.v) # average grads across MPI processes
vf_optimizer.step()
# Log changes from update
kl, ent, cf = pi_info['kl'], pi_info_old['ent'], pi_info['cf']
logger.store(LossPi=pi_l_old, LossV=v_l_old,
KL=kl, Entropy=ent, ClipFrac=cf,
DeltaLossPi=(loss_pi.item() - pi_l_old),
DeltaLossV=(loss_v.item() - v_l_old))
# Prepare for interaction with environment
start_time = time.time()
o, ep_ret, ep_len = env.reset(), 0, 0
# ppo_logger.log("o={},ep_ret={},ep_len={}".format(o,ep_ret,ep_len))
# Main loop: collect experience in env and update/log each epoch
for epoch in range(epochs):
for t in range(local_steps_per_epoch):
a, v, logp = ac.step(torch.as_tensor(o, dtype=torch.float32))
# ppo_logger.log("a={},v={},logp={}".format(a,v,logp))
# print('a={}'.format(a))
next_o, r, d, _ = env.step(a)
ep_ret += r
ep_len += 1
# save and log
# print(Back.RED+'o={},\na={},\nr={},\nv={},\nlogp={}'.format(o,a,r,v,logp))
buf.store(o, a, r, v, logp)
logger.store(VVals=v)
# Update obs (critical!)
o = next_o
timeout = ep_len == max_ep_len
terminal = d or timeout
epoch_ended = t == local_steps_per_epoch - 1
if terminal or epoch_ended:
if epoch_ended and not (terminal):
print('Warning: trajectory cut off by epoch at %d steps.' % ep_len, flush=True)
# if trajectory didn't reach terminal state, bootstrap value target
if timeout or epoch_ended:
_, v, _ = ac.step(torch.as_tensor(o, dtype=torch.float32))
else:
v = 0
buf.finish_path(v)
if terminal:
# only save EpRet / EpLen if trajectory finished
logger.store(EpRet=ep_ret, EpLen=ep_len)
o, ep_ret, ep_len = env.reset(), 0, 0
# Save model
if (epoch % save_freq == 0) or (epoch == epochs - 1):
logger.save_state({'env': env}, None)
# Perform PPO update!
update()
以上就是PPO算法的全部了,全部代码可以在这里找到,这里面还包含了一些其他的相关资料。")
下一次,我们就要从头开始编写环境了。
猜你想看:
- Ubuntu助手 — 一键自动安装软件,一键进行系统配置
- 深度强化学习专栏 —— 1.研究现状
- 深度强化学习专栏 —— 2.手撕DQN算法实现CartPole控制
- 深度强化学习专栏 —— 3.实现一阶倒立摆
- 深度强化学习专栏 —— 4. 使用ray做分布式计算
- 深度强化学习专栏 —— 5. 使用ray的tune组件优化强化学习算法的超参数
- 深度强化学习专栏 —— 6. 使用RLLib和ray进行强化学习训练
- 深度强化学习专栏 —— 7. 实现机械臂reach某点之PPO算法实现(一)
- pybullet杂谈 :使用深度学习拟合相机坐标系与世界坐标系坐标变换关系(二)
- pybullet电机控制总结
- Part 1 – 自定义gym环境
- Part 1.1 – 注册自定义Gym环境
- Part 1.2 – 实现一个井字棋游戏的gym环境
- Part 1.3 – 熟悉PyBullet
- Part 1.4 – 为PyBullet创建Gym环境