自2013年DeepMind的论文Playing Atari with Deep Reinforcement Learning中提出的DQN(Deep Q-Network)算法实现程序学习到如何打Atari游戏以来,深度强化学习迎来了大发展的时机。
自2013年DeepMind的论文Playing Atari with Deep Reinforcement Learning中提出的DQN(Deep Q-Network)算法实现程序学习到如何打Atari游戏以来,深度强化学习迎来了大发展的时机。
 2015年DeepMind发布的Human-level control through deep reinforcement learning论文,提出了改进版的DQN算法,只通过将屏幕像素信息和游戏得分输入给强化学习模型,不断试错与学习后,在不改变模型参数和结构的情况下,模型在Atari 2600中的49个游戏达到了人类专业选手的性能,戳视频。
2015年DeepMind发布的Human-level control through deep reinforcement learning论文,提出了改进版的DQN算法,只通过将屏幕像素信息和游戏得分输入给强化学习模型,不断试错与学习后,在不改变模型参数和结构的情况下,模型在Atari 2600中的49个游戏达到了人类专业选手的性能,戳视频。
 2016年,Google DeepMind提出的AlphaGo系统,使用深度强化学习技术,以4-1战胜围棋世界冠军李世石,【纪录片|中英双字】AlphaGo世纪对决2017。在之后,DeepMind又陆续提出了AlphaGo Zero战胜了AlphaGO以及AlphaZero战胜了AlphaGO Zero,同时AlphaZero采用自我博弈的方法,不通过人类的棋谱即同时战胜了当时围棋、日本象棋、国际象棋的最强大程序。
2016年,Google DeepMind提出的AlphaGo系统,使用深度强化学习技术,以4-1战胜围棋世界冠军李世石,【纪录片|中英双字】AlphaGo世纪对决2017。在之后,DeepMind又陆续提出了AlphaGo Zero战胜了AlphaGO以及AlphaZero战胜了AlphaGO Zero,同时AlphaZero采用自我博弈的方法,不通过人类的棋谱即同时战胜了当时围棋、日本象棋、国际象棋的最强大程序。
 2018年OpenAI提出的OpenAI Five系统,在Dota2 5v5游戏中击败人类顶级战队。
2018年OpenAI提出的OpenAI Five系统,在Dota2 5v5游戏中击败人类顶级战队。
在游戏上取得了惊人的效果,深度强化学习在机器人、自动驾驶、金融、推荐系统等方面都取得了很好的效果。《强化学习 原理与python实现》这本书的作者肖智清指出,强化学习已经成为互联网等行业从业人员的必备知识。 在机器人(机械臂)的应用上,我们来看一下一些精彩的成就。
 2018年,Google Brain提出的Qt-Opt机械臂控制系统,在视觉输入方面,只使用RGB摄像头,从采集的580k抓取尝试中使用包含1.2M个参数的DQN算法来学习,最终的效果是对于训练中未出现过的物体,抓取成功率达到96%,戳视频。
2018年,Google Brain提出的Qt-Opt机械臂控制系统,在视觉输入方面,只使用RGB摄像头,从采集的580k抓取尝试中使用包含1.2M个参数的DQN算法来学习,最终的效果是对于训练中未出现过的物体,抓取成功率达到96%,戳视频。
 2019年,OpenAI提出的Solving Rubik’s Cube with a Robot Hand系统,只通过在仿真中训练机械手旋转魔方,强化学习算法通过自我学习,掌握了单手旋转魔方的能力,且通过sim2real技术,将模型成功的迁移到现实的机械手上,戳视频。
2019年,OpenAI提出的Solving Rubik’s Cube with a Robot Hand系统,只通过在仿真中训练机械手旋转魔方,强化学习算法通过自我学习,掌握了单手旋转魔方的能力,且通过sim2real技术,将模型成功的迁移到现实的机械手上,戳视频。
 2019年,Google Brain的Andy Zeng团队,通过强化学习算法与常规控制器结合的方式(Residual Reinforcement)设计的机械臂控制系统Tossingbot,使得机械臂可以完成抓取物体和抛掷物体的能力,戳视频。
2019年,Google Brain的Andy Zeng团队,通过强化学习算法与常规控制器结合的方式(Residual Reinforcement)设计的机械臂控制系统Tossingbot,使得机械臂可以完成抓取物体和抛掷物体的能力,戳视频。
深度强化学习在机器人(机械臂)上的成功应用还有很多,没法一一列举完全,感兴趣的小伙伴可以多在谷歌浏览下,我也会经常更新一些好玩的项目。
 在推荐系统方面,比较出名的是“虚拟淘宝”,论文Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning淘宝使用真实的交易数据生成一个虚拟的淘宝,在虚拟的淘宝中训练强化学习算法完成商品的推荐,使得淘宝的营收额提高2%。京东、美团等也都存在类似的使用强化学习训练的推荐系统。
在推荐系统方面,比较出名的是“虚拟淘宝”,论文Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning淘宝使用真实的交易数据生成一个虚拟的淘宝,在虚拟的淘宝中训练强化学习算法完成商品的推荐,使得淘宝的营收额提高2%。京东、美团等也都存在类似的使用强化学习训练的推荐系统。
强化学习在自动驾驶方面也有很多有趣的项目诞生,鉴于本人从事的是强化学习与机械臂的研究,自动驾驶方面的应用有待于小伙伴们去开发探索一下。
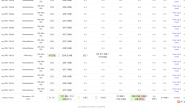
下表总结了上文提到的研究成果,从表中我们可以看出,主要的研究工作还是集中在Google DeepMind, OpenAI, Google Brain等几家单位,同时,加州伯克利、清华大学、上交等也做了很多出彩的工作,尤其是加州伯克利。这里列举了伯克利人工智能研究所的文章,这里是他们的博客。Researchers and labs in AI,这里列举了更多强化学习方面的著名的实验室和个人,在其主页上都罗列了很多的项目和精彩的文章。
| 年份 | 单位 | 项目 |
|---|---|---|
| 2013 | DeepMind | DQN玩Atari游戏 |
| 2015 | DeepMind | DQN玩Atari游戏 |
| 2016 | DeepMind | AlphaGO打败李世石 |
| 2018 | OpenAI | OpenAI Five: Dota2 5v5战胜人类顶级战队 |
| 2018 | 阿里巴巴 | 虚拟淘宝 |
| 2018 | Google Brain | Qt-Opt机械臂抓取 |
| 2019 | Google Brain | TossingBot机械臂抓抛系统 |
| 2019 | OpenAI | 机械手学会单手旋转魔方 |
目前,深度强化学习的研究正在火热期,从一开始的游戏应用,到现在机械臂、机器人、自动驾驶、推荐系统、金融领域等全方位的应用,深度强化学习技术正展示出它独有的魅力。在国内腾讯AI实验室、字节跳动AI实验室、网易伏羲实验室等都招聘强化学习做游戏训练工作,淘宝、京东、美团等招聘强化学习做推荐系统等。 在最新的研究中,强化学习技术也和元学习(Meta Learning)、模仿学习(Imitation Learning)等结合起来,发挥更大的作用,也是一个令人激动的研究领域。 对于学生来说,要做的可以分为两方面: 1)研读论文。深度强化学习领域目前还是一个较新的领域,在应用到具体的项目上时,要求我们对强化学习算法也需精准的掌握,而算法主要来自论文; 2)编程实践。将强化学习算法的理论转换成能够工作的代码,中间还有很长的路要走。对于算法的训练,可以使用自己熟悉的编程语言从头开始写起,对于将强化学习应用到具体的项目上来说,也可以使用已有的强化学习算法库,比如ray、RLLib、Stable Baselines、Spinning Up、ptan等,他们都包含很多强化学习算法,而且经过验证,可以减少很多的算法编程工作。其中ray还是分布式计算框架,可以加速强化学习的训练。
好了,以上就是本节的分享内容,主要介绍了深度强化学习的研究现状。 后面的内容,我们将从头开始一步一步编程实现两个例子: 1)Flappy Bird游戏。将当前屏幕的像素信息输入给深度强化学习算法,通过不断尝试与学习,将像素信息映射到小鸟的动作,使之能持续的完成游戏。这个游戏大家可以下载到手机上看一下能得多少分,后面我们将通过算法得到无限多分; 2)倒立摆。通过这个例子,可以对比深度强化学习方法相比于常规控制方法的优点和缺点。 来学习一下什么是深度强化学习? 为什么使用深度强化学习? 怎样让深度强化学习算法工作?等几个问题。 
 注:图1-图8分别出自: 1:论文Playing Atari with Deep Reinforcement Learning https://arxiv.org/abs/1312.5602 2:Human-level control through deep reinforcement learning https://www.nature.com/articles/nature14236 3:What does AlphaGo vs Lee Sedol tell us about the interaction between humans and intelligent systems? https://medium.com/point-nine-news/what-does-alphago-vs-8dadec65aaf 4:OpenAI Five https://openai.com/blog/openai-five/ 5:QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation https://arxiv.org/abs/1806.10293 6:Solving Rubik’s Cube with a Robot Hand https://openai.com/blog/solving-rubiks-cube/ 7:TossingBot: Learning to Throw Arbitrary Objects with Residual Physics https://tossingbot.cs.princeton.edu/ 8:Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning https://arxiv.org/abs/1805.10000
注:图1-图8分别出自: 1:论文Playing Atari with Deep Reinforcement Learning https://arxiv.org/abs/1312.5602 2:Human-level control through deep reinforcement learning https://www.nature.com/articles/nature14236 3:What does AlphaGo vs Lee Sedol tell us about the interaction between humans and intelligent systems? https://medium.com/point-nine-news/what-does-alphago-vs-8dadec65aaf 4:OpenAI Five https://openai.com/blog/openai-five/ 5:QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation https://arxiv.org/abs/1806.10293 6:Solving Rubik’s Cube with a Robot Hand https://openai.com/blog/solving-rubiks-cube/ 7:TossingBot: Learning to Throw Arbitrary Objects with Residual Physics https://tossingbot.cs.princeton.edu/ 8:Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning https://arxiv.org/abs/1805.10000