参考图书: web3.0与Semantic Web编程(中文版) Web 3.0与Semantic Web编程 英文版 随书代码下载
一、程序环境准备——为以数据为中心的语义Web程序设计做好准备
1.1 什么是语义Web?
语义就是意思、含义。了解了数据的含义之后就能够更加有效地利用底层数据。语义Web就是一个数据网,这些数据以多种方式进行描述,相互链接形成上下文(语义关系),同时这种上下文(语义关系)遵从规定的语法和语言构造。 语义Web的概念是从万维网的概念发展而来的,下表对语义网和万维网之间的区别进行了比较:
| 特性 | 万维网(WWW) | 语义Web |
|---|---|---|
| 基本组件 Fundamental component | 非结构化的内容 Unstructured content | 形式化的陈述 Formal statements |
| 主要用户 Primary audience | 人类用户 Humans | 应用程序 Applications |
| 链接 Links | 标识位置 Indicate location | 标识位置和含义 Indicate location and meaning |
| 主要词汇 Primary vocabulary | 格式编排指令 Formatting instructions | 语义和逻辑 Semantics and logic |
| 逻辑 Logic | 非格式化/非标准 Informal/nonstandard | 描述逻辑 Description logic |
语义Web最初源于显性表达知识的思想。Tim Berners-Lee、James Hendler和Ora Lassila在文章The Semantic Web: A New Form of Web Content That is Meaningful to Computers Will Unleash a Revolution of New Possibilities 中预言了语义Web的一些特征:
- machine readability 计算机可读
- easy information integration 便捷的信息集成
- information inference 支持信息推理
- unique naming 命名唯一性
- rich representation 丰富的表示方法
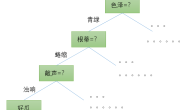
语义Web的发展可以从图论和描述逻辑两个学科的角度来回顾——换句话说,语义Web是这两个学科发展的一个汇聚节点的产物。语义网的层次结构图如下:
语义Web程序设计简介")
1.2 一个语义Web应用程序包含的组件
语义Web程序包含的组件如下图所示:
语义Web程序设计简介") 总的来说,陈述、URI、语言、本体、实例数据组成了语义Web,形成了相互关联的语义信息。语义Web工具创建、操作、询问和推理充实了语义Web。
总的来说,陈述、URI、语言、本体、实例数据组成了语义Web,形成了相互关联的语义信息。语义Web工具创建、操作、询问和推理充实了语义Web。
- 陈述(Statement):语义Web的基础,包含多个由主语、谓语、宾语构成的三元组。
- URI(Uniform Resource Identifier):统一资源标识符,为陈述中所包含的术语提供了一个在整个Internet上的唯一的名称。
- 语言(Language):用于表达一个陈述,并为各种语义Web工具提供指令。
- 本体(Ontology):定义抽象的概念、关系和约束,构成了一个信息领域模型。
- 实例数据(Instance Data):相当于本体的实例化,包含与具体实例相关的信息。例如在本体中定义了“人”这个概念,“喵木木”就是“人”这一概念的实例;在本体中定义了“学习网站”这一概念,“古月居”就是“学习网站”概念的一个具体的实例。
- 建造工具(Construction tools):用于语义Web程序的构建和演化。
- 询问工具(Interrogation tools):用于语义Web上的资源探查。
- 推理机(Reasoners):为语义Web添加推理功能。
- 规则引擎(Rules engines):能支持超出描述逻辑演绎能力的推理功能,可以扩展语义Web上的功能。
- 语义框架(Semantic frameworks):语义框架将上面列举的各种工具(建造工具、询问工具、推理机、规则引擎)打包到一起,形成一个集成单元。
1.3 语义Web程序的四个目标
语义Web程序设计简介") 语义Web程序主要用于实现四个目标——
语义Web程序主要用于实现四个目标——
- Web data–centric(建立以Web数据为中心的数据管理)
- Semantic data(为数据添加语义)
- Data integration/sharing(实现数据的集成和共享)
- Dynamic data(支持对数据的动态变化)
1.4 一些语义Web项目
语义Wiki 这个项目的官网有些页面和文件是有中文的。可以参考这个教程:mediawiki和semantic mediawiki的一些东西 Twine项目 参考文章: Case Study: Twine FOAF(Friend of a Friend)项目 FOAF项目通过一个模型来建立人们之间的关联,这个模型包含社交过程中需要的一些信息,如姓名、邮件地址、爱好等等。下图是FOAF项目定义的一些类和属性,可以通过这些类和属性来描述人与人之间的社交、合作等关系。
语义Web程序设计简介") DBpedia DBpedia是从维基百科中抽取出来的结构化的数据库。与之对应的,复旦大学从百度百科中抽取出了中文通用百科知识图谱(CN-DBpedia)。
DBpedia DBpedia是从维基百科中抽取出来的结构化的数据库。与之对应的,复旦大学从百度百科中抽取出了中文通用百科知识图谱(CN-DBpedia)。
二、第一个语义Web程序:Hello, Semantic Web
2.1 建立语义Web开发环境
语义Web的大多数工具和程序都是基于Java进行开发的。
| 工具类型 | 具体工具 |
|---|---|
| 编译和执行工具 | Java SDK |
| 代码编译工具 | Eclipse IDE |
| 本体编辑工具 | Protégé |
| 语义Web程序设计框架 | Jena (下载链接) |
| 本体推理机 | Pellet 1.5.2,使用Jena自带的推理机也可以 |
这些工具之间的关系如下所示:
语义Web程序设计简介") 关于的Protégé教程可以看这个:Protégé基本教程【Protégé5.5.0版本】
关于的Protégé教程可以看这个:Protégé基本教程【Protégé5.5.0版本】
2.2 开始第一个语义Web程序
准备工作 打开Eclipse,创建一个新的Java项目(File-New-Java Project)。输入项目名称,并选择项目的保存位置(如果不修改项目的保存位置,直接使用默认文件夹即可。)注意,项目的名称默认是以小写字母开头的(当然大写字母也可以)。
语义Web程序设计简介") 右键-Properties-Java Build Path-Add External Jars,将Jena包全部导入项目中。(需要注意的是,要将apache jena下lib和lib-src文件下的所有包都导入项目中。) 导入需要的jena包
右键-Properties-Java Build Path-Add External Jars,将Jena包全部导入项目中。(需要注意的是,要将apache jena下lib和lib-src文件下的所有包都导入项目中。) 导入需要的jena包
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import org.apache.jena.query.Query;
import org.apache.jena.query.QueryExecution;
import org.apache.jena.query.QueryExecutionFactory;
import org.apache.jena.query.QueryFactory;
import org.apache.jena.query.QuerySolution;
import org.apache.jena.query.ResultSet;
import org.apache.jena.rdf.model.*;
import org.apache.jena.reasoner.Reasoner;
import org.apache.jena.reasoner.ReasonerRegistry;
import org.apache.jena.reasoner.ValidityReport;
import org.apache.jena.reasoner.rulesys.GenericRuleReasoner;
import org.apache.jena.reasoner.rulesys.Rule;
import org.apache.jena.util.FileManager;
需要说明的是,调用的包书上的是com.hp.hpl.*,这个主要是下载的jena包的来源或者版本不一样。我下载的是jena包通过org.apache.*来调用。在后面的程序中,会通过具体的案例来介绍这些包的作用。 本体文件速览:
语义Web程序设计简介") 载入模型
载入模型
public class helloSemanticWeb {
static String defaultNameSpace = "http://org.semwebprogramming/chapter2/people#";
private Model _friends = null;
public static void main(String[] args) throws IOException {
helloSemanticWeb hello = new helloSemanticWeb();
//Load my FOAF friends
System.out.println("Load my FOAF Friends");
hello.populateFOAFFriends();
}
private void populateFOAFFriends(){
_friends = ModelFactory.createOntologyModel();
InputStream inFoafInstance = FileManager.get().open("Ontologies/FOAFFriends.rdf");
_friends.read(inFoafInstance,defaultNameSpace);
//inFoafInstance.close();
}
}
我们首先通过populateFOAFFriends()方法载入模型。首先,ModelFactory.createOntologyModel()用于创建一个本体模型,并通过文件读入流读入本体文件。 接下来向语义Web打招呼吧! 接下来,我们通过mySelf()方法来向语义Web打招呼。
private void mySelf(Model model){
//Hello to Me - focused search
runQuery(" select DISTINCT ?name where{ people:me foaf:name ?name }", model); //add the query string
}
可以看到,向语义Web(即实体”me”)打招呼,我们首先要找到实体”me”的名字,是通过一个SPARQL语句来完成(关于SPARQL的介绍可以看SPARQL——语义网的查询语言)。SPARQL语句通过runQuery方法来实现。
private void runQuery(String queryRequest, Model model){
StringBuffer queryStr = new StringBuffer();
// Establish Prefixes
//Set default Name space first
queryStr.append("PREFIX people" + ": <" + defaultNameSpace + "> ");
queryStr.append("PREFIX rdfs" + ": <" + "http://www.w3.org/2000/01/rdf-schema#" + "> ");
queryStr.append("PREFIX rdf" + ": <" + "http://www.w3.org/1999/02/22-rdf-syntax-ns#" + "> ");
queryStr.append("PREFIX foaf" + ": <" + "http://xmlns.com/foaf/0.1/" + "> ");
//Now add query
queryStr.append(queryRequest);
Query query = QueryFactory.create(queryStr.toString());
QueryExecution qexec = QueryExecutionFactory.create(query, model);
try {
ResultSet response = qexec.execSelect();
while( response.hasNext()){
QuerySolution soln = response.nextSolution();
RDFNode name = soln.get("?name");
if( name != null ){
System.out.println( "Hello to " + name.toString() );
}
else
System.out.println("No Friends found!");
}
} finally { qexec.close();}
}
在runQuery方法中,首先先建立查询语句。程序的5-8行首先先建立查询语句的命名空间,接着加入需要查询的语句(即程序的第11行)。通过QueryFactory将查询语句转换成语义web中的查询。与查询有关的类主要在org.apache.jena.query包中,可以看官网的介绍。【详细的介绍会在后面的文章中给出,等写完了我再来更新这里的链接。】 我们同样可以利用查询语句,向语义Web中的其他朋友问好(方法myFriends()):
private void myFriends(Model model){
//Hello to just my friends - navigation
runQuery(" select DISTINCT ?myname ?name where{ people:me foaf:knows ?friend. ?friend foaf:name ?name } ", model); //add the query string
}
输出: Say Hello to my FOAF Friends Hello to I. M. Ontology Hello to Ican Reason Hello to Makea Statement 扩大我们的社交网络——认识新朋友! 我们现在已经完成和老朋友打招呼的任务了,如果我们认识了新的朋友,我们应该怎样把ta加入到我们的语义Web中呢——populateNewFriends()方法:
private void populateNewFriends() throws IOException {
InputStream inFoafInstance = FileManager.get().open("Ontologies/additionalFriends.owl");
_friends.read(inFoafInstance,defaultNameSpace);
inFoafInstance.close();
}
首先,我们先建立一个实例文件additionalFriends.owl,文件中是新认识的三个朋友Sem Web、Web O. Data和Mr.Owl。 然而,当我们再次向语义网中的朋友们打招呼(方法myFriends())时,我们发现并不能访问到新加入的朋友。这是因为我们认识的老朋友的本体和新朋友的本体的框架不同(也就是存在本体的异构问题),老朋友的框架是用FOAF来描述的,新朋友的框架是用People来描述的:
语义Web程序设计简介") FOAF本体子集和People本体的图示如下:
FOAF本体子集和People本体的图示如下:
语义Web程序设计简介") 因此,我们需要对本体进行对齐(Ontology Alignment)。我们首先创建一个新的模型来保存新老朋友的本体:
因此,我们需要对本体进行对齐(Ontology Alignment)。我们首先创建一个新的模型来保存新老朋友的本体:
private Model schema = null;
.
.
.
// Add the ontologies
System.out.println("\nAdd the new Ontologies");
hello.populateFOAFSchema();
hello.populateNewFriendsSchema();
.
.
.
private void populateFOAFSchema() throws IOException{
InputStream inFoaf = FileManager.get().open("Ontologies/foaf.rdf");
InputStream inFoaf2 = FileManager.get().open("Ontologies/foaf.rdf");
schema = ModelFactory.createOntologyModel();
//schema.read("http://xmlns.com/foaf/spec/index.rdf");
//_friends.read("http://xmlns.com/foaf/spec/index.rdf");
// Use local copy for demos without network connection
schema.read(inFoaf, defaultNameSpace);
_friends.read(inFoaf2, defaultNameSpace);
inFoaf.close();
inFoaf2.close();
}
private void populateNewFriendsSchema() throws IOException {
InputStream inFoafInstance = FileManager.get().open("Ontologies/additionalFriendsSchema.owl");
_friends.read(inFoafInstance,defaultNameSpace);
inFoafInstance.close();
}
接下来,我们建立本体对齐规则——addAlignment()方法。
private void addAlignment(){
// State that :individual is equivalentClass of foaf:Person
Resource resource = schema.createResource(defaultNameSpace + "Individual");
Property prop = schema.createProperty("http://www.w3.org/2002/07/owl#equivalentClass");
Resource obj = schema.createResource("http://xmlns.com/foaf/0.1/Person");
schema.add(resource,prop,obj);
//State that :hasName is an equivalentProperty of foaf:name
resource = schema.createResource(defaultNameSpace + "hasName");
//prop = schema.createProperty("http://www.w3.org/2000/01/rdf-schema#subPropertyOf");
prop = schema.createProperty("http://www.w3.org/2002/07/owl#equivalentProperty");
obj = schema.createResource("http://xmlns.com/foaf/0.1/name");
schema.add(resource,prop,obj);
//State that :hasFriend is a subproperty of foaf:knows
resource = schema.createResource(defaultNameSpace + "hasFriend");
prop = schema.createProperty("http://www.w3.org/2000/01/rdf-schema#subPropertyOf");
obj = schema.createResource("http://xmlns.com/foaf/0.1/knows");
schema.add(resource,prop,obj);
//State that sem web is the same person as Semantic Web
resource = schema.createResource("http://org.semwebprogramming/chapter2/people#me");
prop = schema.createProperty("http://www.w3.org/2002/07/owl#sameAs");
obj = schema.createResource("http://org.semwebprogramming/chapter2/people#Individual_5");
schema.add(resource,prop,obj);
}
这段程序主要是增加了三个陈述,形成本体对齐规则:
语义Web程序设计简介") 之后,我们还需要运行推理机(方法
之后,我们还需要运行推理机(方法bindReasoner()),完成本体的对齐:
private void bindReasoner(){
Reasoner reasoner = ReasonerRegistry.getOWLReasoner();
reasoner = reasoner.bindSchema(schema);
inferredFriends = ModelFactory.createInfModel(reasoner, _friends);
}
推理之后的模型保存在inferredFriends模型中,通过在inferredFriends模型上运行相应的SPARQL语句,我们就能和语义网中的所有朋友打招呼啦! 然而,我们会发现,通过这种方法进行对齐之后得到的本体里面,当我们再次运行hello.mySelf()(及向自己打招呼时),返回了两个结果。这是因为本体对名字的数量没有限制,在本体对齐之后,实体“me”就拥有了两个名字——Semantic Web和Sem Web,这就需要我们在建立本体框架的时候,就要对类似的逻辑和约束进行声明。 只希望联系有email地址的朋友 我们首先通过一个约束,建立一个朋友的子集。接着,我们向这个子集中的朋友问好:
public void setRestriction(Model model) throws IOException{
// Load restriction - if entered in model with reasoner, reasoner sets entailments
InputStream inResInstance = FileManager.get().open("Ontologies/restriction.owl");
model.read(inResInstance,defaultNameSpace);
inResInstance.close();
}
public void myEmailFriends(Model model){
//just get all my email friends only - ones with email
runQuery(" select DISTINCT ?name where{ ?sub rdf:type <http://org.semwebprogramming/chapter2/people#EmailPerson> . ?sub foaf:name ?name } ", model); //add the query string
}
利用Jena规则完成更复杂的信息发送! 为了更精准地发送消息,我们希望仅仅和拥有gmail.com邮箱地址的朋友打招呼——这超出了本体OWL语言的描述能力。因此,我们可以采用Jena规则来完成。每一种规则引擎都由自己对应的规则语言,jena规则的语法可以看官网的介绍。
private void runJenaRule(Model model){
String rules = "[emailChange: (?person <http://xmlns.com/foaf/0.1/mbox> ?email), strConcat(?email, ?lit), regex( ?lit, '(.*@gmail.com)') -> (?person <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://org.semwebprogramming/chapter2/people#GmailPerson>)]";
Reasoner ruleReasoner = new GenericRuleReasoner(Rule.parseRules(rules));
ruleReasoner = ruleReasoner.bindSchema(schema);
inferredFriends = ModelFactory.createInfModel(ruleReasoner, model);
}
public void myGmailFriends(Model model){
runQuery(" select DISTINCT ?name where{ ?sub rdf:type people:GmailPerson. ?sub foaf:name ?name } ", model); //add the query string
}
输出: Say hello to my gmail friends only Hello to Makea Statement Hello to I. M. Ontology
三、小结——语义Web版Hello World之旅小结
| Hello之旅 | 相关技术 | 备注 |
|---|---|---|
| 向语义网问好 | 查找一个节点的信息(SPARQL) | 添加FOAF实例 |
| 向语义网中的朋友问好 | 查找一系列节点的信息(SPARQL) | |
| 向语义网中的新老朋友问好 | 添加新的朋友 | 新的朋友没有在语义上对准,所以没有得到问候 |
| 试着向所有朋友问好 | 加入FOAF本体和People本体,添加对齐规则,将推理机绑定到数据 | 新老朋友对准了,可以向所有的朋友问好了 |
| 仅仅向有email地址的朋友问好 | 基于某个约束创建一个类 | 生成一个朋友的子集 |
| 仅仅向有gmail邮箱地址的朋友问好 | 创建一条规则并绑定一个规则引擎 | 基于字符串匹配产生一个更为精炼的子集 |
| 向所有的朋友问好 | 使用和原先相同的查询 | 确保所有的数据和逻辑都完整无缺 |