参考资料:
一、SPARQL——基于语义网的查询
语义网信息查询需要一种将RDF作为基本语法的语言。SPARQL是SPARQL协议与RDF查询语言(SPARQL Protocol and RDF Query Language)的缩写,是W3C的推荐标准。关于SPARQL的介绍,可以看我的另外一篇笔记——SPARQL——语义网的查询语言。 用于SPARQL查询的Jena包主要是org.apache.jena.query。包中主要的类及其功能介绍如下:
| 类 | 主要功能 |
Query | 包含所有查询方法的类,通常通过QueryFactory方法来创建。 |
QueryFactory | 用于创建一个查询Query。 |
QueryExecution | 表示查询的一次执行。 |
QueryExecutionFactory | 用于存放一次查询得到的实例。 |
DatasetFactory | a place to make datasets. |
QuerySolution | 用于得到一次SELECT查询得到的一个实例(A single solution to the query.)。 |
ResultSet | 包含所有的查询结果。是一个迭代器(An iterator)。 |
ResultSetFormatter | 将结果集转换为各种形式;转换成json、文本或纯XML。 |
关于这些类更详细地用法可以参考官方文档——Apache Jena ARQ 3.17.0。在进行SPARQL查询时,一般的过程如下所示: queryString = "..."; Query query = QueryFactory.create(queryString); QueryExecution qexec = QueryExecutionFactory.create(query, model); ResultSet results = qexec.execSelect(); List<QuerySolution> queryList = ResultSetFormatter.toList(results); 首先,先要创建查询语句queryString。需要注意的是,在创建查询语句时,需要标注所有使用到的前缀(PREFIX)。因为在JAVA中进行多行编辑的时候不方便(且不美观),比较推荐的方法是将查询语句放在一个txt文件中,通过读取这个txt文件来建立查询语句。这样做的好处有两个:一是代码的编写比较美观,而是可以对查询语句有很好的管理(包括后期的修改等)。接着,通过建立QueryFactory.create(queryString)查询。然后,通过QueryExecutionFactory.create(query, model)将查询绑定到本体模型。并通过qexec.execSelect()得到查询结果。代码的最后一行List<QuerySolution> queryList = ResultSetFormatter.toList(results)主要是将迭代器中的结果转化成一个列表,方便后面的访问和操作。 接下来,就可以通过对列表的遍历,读取每一个查询结果。获取查询结果通过下面的代码来进行。 QuerySolution soln = queryList.get(i); obj = soln.get("obj"); 其中get("obj")中的字段为查询语句中的变量名。例如,查询语句为SELECT ?obj ?n ?value WHERE……,那么就可以通过get("obj")来得到查询结果的第一个变量。
二、语义网推理语言
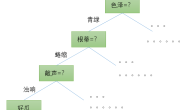
规则是表示知识的一种方式,它通常超过了OWL 1的表达能力。语义网上的规则是典型的条件语句,即“IF-THEN子句”。规则标记语言(Rule Markup Language)主要关注的是一种面向多种规则的基于XML的标记语言,SWRL(Semantic Web Rule Language)是基于语义网的规则语言之一,它采用一系列Horn子句来表示规则,具体的可以看SWRL的官方文档——SWRL: A Semantic Web Rule Language Combining OWL and RuleML。 Jena框架也支持自己的规则,即Jena规则。Jena规则和规则推理机绑定,对于任何Jena推理机来说,一个规则推理机绑定一个模型或者模式,通过bindSchema(schema)来实现。Jena推理机既支持正向推理,也支持反向推理,同时也支持两者的混合模式。一条Jena规则包含一个主体(或者称作前提,即if子句)项列表和一个头部(或者称作解困,即then子句)项列表。为了方便起见,每个规则都可以选用一个名称,而且混合规则可以选定一个处理方向。这些规则采用Jena专用格式进行描述,如下图所示。 查询、推理与语义网应用程序框架设计") 和SWRL一样,Jena规则同样提供了一种基本规则语法来扩展本体的能力。不同的是,Jena规则允许灵活地采用正向链接和反向链接及二者混合结合的方式。此外,规则项中还允许采用各种内置方法(built-in方法)来表达更复杂的逻辑,比如数学运算等。 在Jena中进行推理的代码块如下,相关的API和包是
和SWRL一样,Jena规则同样提供了一种基本规则语法来扩展本体的能力。不同的是,Jena规则允许灵活地采用正向链接和反向链接及二者混合结合的方式。此外,规则项中还允许采用各种内置方法(built-in方法)来表达更复杂的逻辑,比如数学运算等。 在Jena中进行推理的代码块如下,相关的API和包是reasoner。首先,从规则文件rulefile中读入规则,然后将规则绑定到推理机reasoner,并通过推理得到推理后的模型infmodel。 List rules = Rule.rulesFromURL(rulefile); Reasoner reasoner = new GenericRuleReasoner(rules); infmodel = ModelFactory.createInfModel(reasoner, _model);
三、设计语义网应用框架
查询、推理与语义网应用程序框架设计") 语义网程序的框架主要如上图的路径所示。这条路径主要包含两个部分——语义网数据开发和语义网数据管理。 总的来说,语义网数据开发生命周期按照下列步骤进行。
语义网程序的框架主要如上图的路径所示。这条路径主要包含两个部分——语义网数据开发和语义网数据管理。 总的来说,语义网数据开发生命周期按照下列步骤进行。
- 存储——在开发过程中,必须考虑语义网数据的存储。一般是内存或者数据库。
- 填充(或者叫实例化)。框架将从文件、网站、数据库中检索到的数据或者将直接构造得到的数据填充到存储中。
- 组合——将多个来源的数据进行组合,包括加、并、差、交等操作。
- 推理——框架将允许对语义网进行内部推理或者外部推理,以得到额外的信息。既可以为这些额外信息增加新的陈述,也可以使用已有的陈述来表示推理得到的结果。
- 询问——框架通过检索、导航或者查询来探查语义网数据。搜索采用简单匹配的方式进行,导航按照多种属性构成的路线进行,而查询需要形式化的查询语言。
- 导出——框架提供了以各种标准格式导出语义网数据的方法。
- 存储单元分配/关闭——框架将清除参考存储并且释放所有分配的计算资源。
语义网数据管理则涉及了四个方面:
- 信息——框架规定了语义网数据的规模、功能和特征。
- 事件——框架中经常会出现多种事件的并发,例如,通过向数据添加陈述来进行事件驱动的程序设计。
- 并发性——框架管理着多个线程,用户可以并发地对同意语义网数据进行操作。
- 定制——框架允许通过自定义的方式来满足用户的特殊需求,例如:对数据存储机制进行修改。