上一篇文章我们简单介绍了信息熵的概念,知道了信息熵可以表达数据的信息量大小,是信息处理一个非常重要的概念。
")
注意,我们前面在说明的时候log 是以2为底的,但是一般情况下在神经网络中,默认以e 为底,这样算出来的香农信息量虽然不是最小的可用于完整表示事件的比特数,但对于信息熵的含义来说是区别不大的。其实只要这个底数是大于1的,都能用来表达信息熵的大小。
本篇我们来看看机器学习中比较重要的一个概念—相对熵。相对熵,又被称为KL散度或信息散度,是两个概率分布间差异的非对称性度量 。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗 。
看完上面的解释,我相信你跟我开始看的时候一模一样,一脸懵逼。下面我们直接看公式,然后慢慢理解:")
上面的p ( x i )为真实事件的概率分布,q ( x i )为理论拟合出来的该事件的概率分布。
因此该公式的字面上含义就是真实事件的信息熵与理论拟合的事件的香农信息量与真实事件的概率的乘积的差的累加。比较难懂的是− ∑ i = 1 N p ( x i ) log q ( x i ) 这玩意,到底是什么鬼。经过我看了又看,我发现好像很难做出含义解释,估计这东西是前人凑出来的好用的东西(以后有新的理解会更新上来)。那么退而求其次看看它有什么用吧。
假设理论拟合出来的事件概率分布跟真实的一模一样,那么这玩意就等于真实事件的信息熵,这一点显而易见。
假设拟合的不是特别好,那么这个玩意会比真实事件的信息熵大(稍后证明)。
也就是在理论拟合出来的事件概率分布跟真实的一模一样的时候,相对熵等于0。而拟合出来不太一样的时候,相对熵大于0。这个性质很关键,因为它正是深度学习梯度下降法需要的特性。假设神经网络拟合完美了,那么它就不再梯度下降,而不完美则因为它大于0而继续下降。
但它有不好的地方,就是它是不对称的。举个例子,比如随机变量X ∼ P X \sim PX∼P取值为1,2,3时的概率分别为[0.1,0.4,0.5],随机变量Y ∼ Q Y \sim QY∼Q取值为1,2,3时的概率分别为[0.4,0.2,0.4],则:")
也就是用P 来拟合Q 和用Q 来拟合P 的相对熵居然不一样,而他们的距离是一样的。这也就是说,相对熵的大小并不跟距离有一一对应的关系。这点蛮头疼的,因为一般我们希望距离越远下降越快,而相对熵取哪个为参考在同等距离情况下下降的速度都不一样,这就非常尴尬了。
推导到这相信很多人会想,既然如此,那为什么现在还是很多人用相对熵衍生出来的交叉熵作为损失函数来训练神经网络而不直接用距离相关的均方差呢?
以下面的例子稍作解释:
假设神经网络的最后一层激活函数为s i g m o i d sigmoidsigmoid,它长这样:
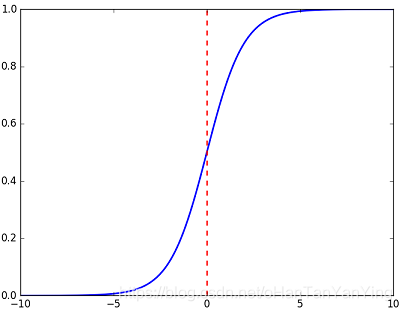
可以看到它的两头异常的平,也就是说在那些地方的导数接近于0。而反向传播是需要求导的,用了均方差损失函数之后求导结果包含y ( y − 1 ) (可参考这篇文章),这在y y接近于0或者1的时候都趋于0,会导致梯度消失,网络训练不下去。但如果用相对熵衍生出来的交叉熵作为损失函数则没有这个问题。详细的分析可见这篇文章。因此虽然相对熵的距离特性不是特别好,但总归好过直接梯度消失玩不下去,因此很多用s i g m o i d sigmoidsigmoid作为激活函数的神经网络还是选择了用相对熵衍生出来的交叉熵作为损失函数。
当然如果你选用的不是s i g m o i d sigmoidsigmoid激活函数,则不需要考虑这些,这个是外话了。
")