由上面一篇文章我们已经知道了,如果我们从真实数据分布里面取n个样本,根据给定样本我们可以列出其出现概率的表达式,那么生成这N个样本数据的似然(likelihood)就是
那么下面我们来看看GAN的推导。
在极大似然估计中,我们假定要求的事物有一个固定的模型,写作![]() ,但这个模型十分复杂,我们无法完全彻底的去刻画它,只能列一个带有参数的式子,然后用模型抽样出来的样本去估计出这个参数到底最有可能是什么。
,但这个模型十分复杂,我们无法完全彻底的去刻画它,只能列一个带有参数的式子,然后用模型抽样出来的样本去估计出这个参数到底最有可能是什么。
打个比方,有一个箱子,里面有一百多亿个球,球的颜色分别是红橙黄绿蓝靛紫七种,那么问从里面拿一个球出来是红色的概率。
面对这样一个问题。如果“一百多”后面没有跟着个“亿”,我们可以直接把不同颜色的球数出来,这样概率就有了。但有个”亿”要去数就比较要命了。因此我们知道这个系统肯定是存在着一个固定分布的参数,但不知道这个参数是个什么鬼,就只能把分布模型写成P d a t a ( x ),然后用别的方式来想办法逼近这个模型。我们从模型中抽出m个样本,记为{ x 1 , x 2 , … , x m } ,然后用这些样本来估计我们模型的参数,列式如下(这里式子用李宏毅教授视频写法,和之前的有些许差异,但所表述东西是一样的):

这里这样凑是很巧妙的!!!因为要把公式凑成K L 散度的样子。至于是怎么想到的这件事情。。。我也不知道,依稀记得初中参加奥数班的时候,老师在空间中取一个点,然后做了快十条辅助线来求解几何问题,那个时候我就觉得智商不够用了。。。
将上面式子整理如下:
中间最大值变最小值的步骤其实就相当于在公式前面乘一个负号,那么最大值自然就变成最小值。
好了,公式推到这里我们知道了,如果要去做一个模型的极大似然估计,那么相当于求真实模型和拟合模型之间的K L KLKL散度取最小值时的θ \thetaθ取值。
当然进一步想,假设这里求的不是K L KLKL散度,而是另外的一种距离,应该也是差不多的。
到了这一步,相信明眼人早已经看出来了,上面的推理不过就是对极大似然估计的式子做进一步的推导,其实还是跟GAN没什么关系。但那是基础,只能先推一推,然后再抛出一个问题:假设我们连带参数的式子都列不出来呢?
比如图像的生成问题。或许你现在还没意识到这个问题的难度,那么请你用一道公式写出世界上所有美女在图像中的表达式,那道公式就是:“我以后的女朋友”。恩,说远了,其
实那道公式是,列不出来。
一脸懵逼了吧,哈哈,说实在的,本人以前做图像处理的时候遇到这种问题都是充满绝望的。
依照李教授视频的说法,有人尝试用高斯混合模型来做这件事情,但是效果很悲剧,就是因为高斯混合模型的复杂度和图像的复杂度比起来还是太小儿科了。可以做个简单的比较,曾经很流行的一个说法形容围棋的复杂度,说它的可能性比天上的星体还要多。而围棋也就19*19的361个交叉点,每个交叉点3种可能。图像哪怕是200 * 200的灰度图,每个点都有256种可能,这个数量级远非围棋可比!那么围棋用传统方法都解决不好的,图像怎么可能解决的好呢?
是的,要用传统方法在图像上解决问题一般限制比较多,最大的问题就是这里的这道模型公式真的很难列出来,除非你人为去加了很多限制,但这样做出来的模型泛化性又很差。而神经网络则不然,简单的讲,假设神经网络够复杂且训练的好,它可以拟合世间所有能拟合的东西,注意,是所有!因此有大神就想,要不就用神经网络来表述图像的模型好啦,于是GAN神经网络中的G GG(Gernerator)网络就诞生了,平地一声雷,逻辑图如下:
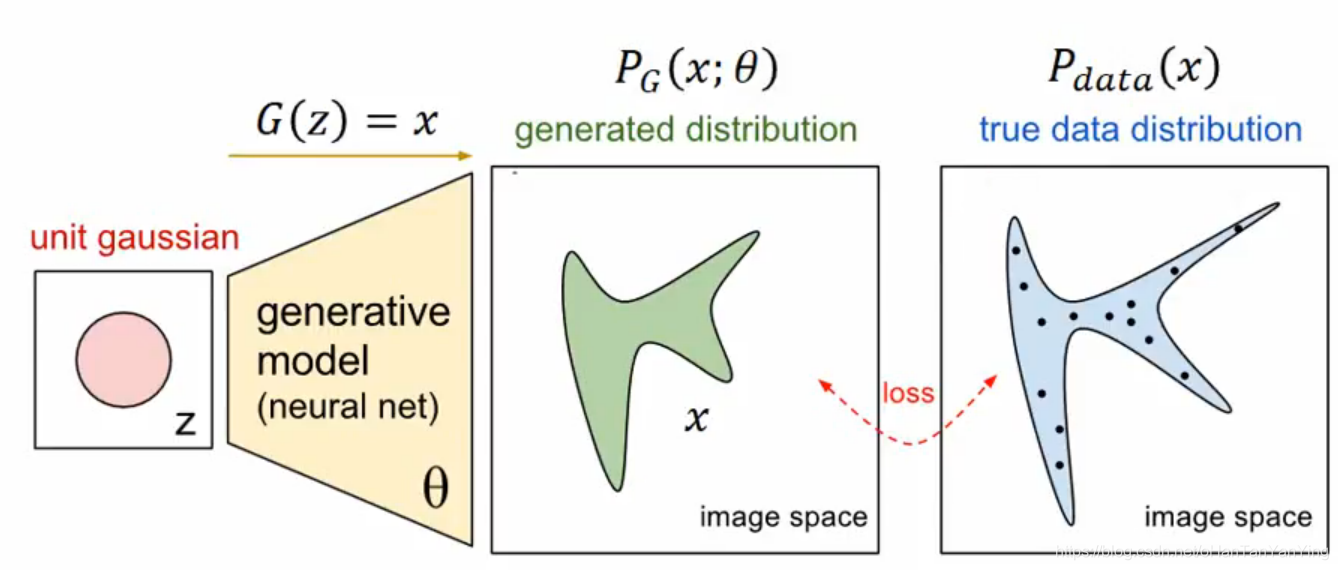
看到这个图,相信很多人一开始也跟我一样是崩溃的。没事,崩溃是我们这一行的常态嘛。首先我们要搞清楚我们要用G GG来做什么,前面我们讲对于图像来说,哪怕你手头上有一类图像(比如说美女图片啥的),你也很难去刻画出美女的公式是什么,而G GG正是来帮我们列式的。我们让它去看遍天下所有美女的图片,不断通过与真实图像进行分布差距对比来优化自己学到的规律,最终学到炉火纯青,基本上可以做到手中无片,心中有片的最高境界,可能它看到远山娥黛,便画出了王语嫣,看到绝世出尘,便画出了小龙女(李若彤版)。总之你要什么它就来什么。
那么对于一个神经网络,它学的是什么呢?自然是里面的权重嘛,我们可以把它写作θ \thetaθ。
一般来讲我们人如果要去学习美女图片的规律,首先会真的去看各种美女图片然后总结规律。但对于科学推理它不是这个样子的,我们要假定美女图片是一种图片的分布形式,然后列一道式子让其输出符合这个分布,那么这个式子就是美女图片的模型。这里的式子是G GG定义的,而因为它一开始的参数是随机的,基本不可能刚刚好就符合输出是美女这一分布。因此我们要让它批量的输出一堆的图片,然后算这些图片的分布P G ( x ; θ ) 和实际的分布P d a t a ( x ) 之间到底差了多少,以此来调整参数θ \thetaθ。也就是你不给它看美女的图片,而是让它直接画,然后每次都把它画的东西撕了,骂它画的是什么屎,然后告诉他美女并不是长这样的,回去慢慢悟。经过千锤百炼,沧海桑田,它终于有一天总结出了美女的规律,功成之日仰天长啸,哈哈哈哈哈。
那么,前面的z 又是个什么鬼?它是一个分布函数,我们每次从这个函数中取出一个样本扔进去神经网络,然后让他输出一个样本。假设我们遍历完整个z 的样本空间输出了全部对应的x,而对应的x xx的分布又跟真实数据的分布一样,那么我们的美女生成器就做成了!
这里这样解释是OK的,但有点不清楚。首先是为什么用z zz而不用x xx,我们知道当神经网络的参数固定住,你扔一个东西它必然会对应一个输出。假设x xx的可能空间比z zz大,那么这个网络不就无法完全拟合整个x xx空间了吗?是的,但我们本来也没有想拟合整个x xx空间,我们需要拟合的是x xx空间下美女这个子集,而只要z zz的复杂度足够,那么经过神经网络之后出来的x xx应该就可以非常近似于这个子集。当然我们这么做,主要也是不想输入太复杂。
如果上面关于z zz的解释你完全看不懂,那么除了回去看数学之外,你还能这样理解。这里的z zz就是前面的“远山娥黛”、“绝世出尘”、“风华绝代”、“沉鱼落雁”、“闭月羞花”、“明
眸善睐”等等等等,突然想去看一遍《洛神赋》哇槽。
推到这里我们就把逻辑图推完了,嘴角上扬,发出得意的奸笑。然后下一秒就僵硬了,因为这个看似天衣无缝的推导有个致命的问题,就是,算不了。。。

长这样,这个公式的x xx是样本给的,z zz是一个随机分布,整体的意思是说我们对z zz进行积分,积分里面是z zz出现的可能性乘以z zz经过神经网络生出来的这个东西的分布与样本的比较结果(相同为1不同为0)。为什么是这样的?
因为我们前面说过,我们要用z zz来映射到x xx,假设映射关系已经确定,那么z 出现的可能性就直接对应于x分布的可能性,当然也可能出现多个z 对应一个x的映射。 I [ G ( z )= x ]就是我们判定z 映射到x 的标准。
但这公式算不了。因为这样我们给定一个样本,要做的是遍历整个z zz空间来找到映射关系,而G GG网络又是个很复杂的东西,基本上无法算出来(再说,我们之所以用G GG
网络也就看中了它的复杂性)。因此推到这里就推死了!原因就是算不出来。
那么能不能通过一个神经网络来拟合P G ( x ; θ )呢?可以应该是可以的,但问题是拟合出来的P G ( x ; θ ) 哪怕比这货P G ( x ) = ∫ z P prior ( z ) I [ G ( z ) = x ] d z 简单一点,但也是个很复杂的神经网络啊!这样后面拿它去算K L KLKL散度也没得算。因此进一步,能不能直接用神经网络来帮忙评估各个分布之间的距离呢?
D (Discriminator)网络就这么诞生了。这个D 网络干的事情就是输入一个x 来自真实样本或者拟合样本,然后分析它们来自哪里,并输出一个标量。这个标量你可以训练它为一个判定标准,就是如果是真实样本就输出接近1的数,拟合样本就输出接近0的数这样子。这样我们的判别器也就有了,把判别器对于真实样本和拟合样本的所有判别做比较处理,则我们G 网络需要的分布距离也就有了。
上面说了那么多,其实实际上,GAN论文告诉我们只要让G GG和D DD各自来解下面这道式子就完事了(牛逼的人从来就是这样,不啰嗦,人狠话不多)。

右边的max D V ( G , D ) )假定G GG已经是确定的,那么就变成arg max D V ( D ) 。V 这个函数算的是P d a t a ( x ) 和 P G 之间的距离。那么我们这个时候就是要训练D 网络来最大化这个距离,因为只有这样我们的判别器才是给力的。然后一旦我们的判别器非常给力了,那么我们只要定住它,训练G 来使得arg min G V ( G )这道公式最小就可以了。因为这道公式最小说明我们通过神经网络实现了类似于极大似然法,找到了网络的最优解θ ∗ 。
现在剩下的最后一个问题就是V 这个算P d a t a ( x ) 和 P G 之间距离的函数到底长什么样了。原生GAN的论文告诉我们V VV长这样:
看到这里我满脑子的“哇槽”,为什么啊!这为什么就是P d a t a ( x ) 和 P G 之间的距离啊???
想到头发白了之后终于明白了。假设我们训练出来的这个D网络输出的是样本是真样本的概率,那么公式第一项我们肯定希望这个D ( x ) D ( x )D(x)越接近于1越好,而第二项希望它越接近于0越好,这样整个V VV取得最大值(注意这里两项的x xx不是同一个,李教授的视频这样写感觉不如原论文区分开来清楚),如果是一个真的无敌的神经网络上面这个区分它是做的到的(当然随着拟合越来越好要区分则越来越难,如果有拟合的数据和实际的数据重叠了,则无法取得理想的最大值)。反之,如果网络判断能力越差,则这个式子越小。因此它就是一个衡量P d a t a ( x ) 和 P G 之间的距离的公式。另外这里最妙的还在于后面,我们对公式做展开。
这里我们假设D ( x ) 是无敌的,对于每个积分中的积分的x 都能找到一个D ( x ) 使得积分里面的式子最大,那么最后积分出来的值肯定就是最大的。所以我们现在如果要求使得上面这个式子最大的D ( x ),就相当于求使得下面这个式子最大的D ( x ) 
这里的计算就极其简单了(李教授表示小学生都会算),就是求导然后让式子等于0,求出这个时候D ( x ) 是多少就行。最后求出来:
可以看出D ∗ ( x ) 是大于0小于1的数,符合我们刚刚对D ( x ) 的定义。
这样我们这道神话般的公式:
的右边部分就有了。我们把D ∗ ( x ) 往公式V 代入:
上面的2 log 1 /2 是把两项分子的1/ 2 拿出来的结果,因为log \loglog里面相乘就等于外面相加,然后对P d a t a ( x ) 或P G ( x )的整个空间进行积分结果都等于1。推导比较简单,就不写了。
推到这一步基本上没什么难度,当看到J S ( P data ( x ) ∥ P G ( x ) ) 这一项出来的时候差点跪了下去,牛逼啊哇槽!因为这一项告诉我们,如果D ∗ ( x ) 取得最大值,那么V 这个公式将直接变成衡量P data ( x ) 和P G ( x ) 之间差距的公式。这个时候只要我们求出对应的G 的最小值就搞定了,巧得不要不要的。
还有更牛逼的,假设G ∗ = arg min G max D V ( G , D ) 这倒公式的D定住了,我们可以把max D V ( G , D ) 写成L ( G ) ,它牛逼在哪?牛逼在于L ( G ) 直接就是我们G 网络的损失函数,我们要让L ( G )取得最小值,不就是我们神经网络的目标吗!?完美!每每看到这里就不禁感慨大自然的神奇,数学的伟大和人类的渺小啥的。。。
到此我们就把全部数学推导过程全部做完了,感觉真是一把老泪掉下来,不知不觉写了五千多字,应该是写过的最长的一篇博客了。到此你可能已经明白了数学怎么来的了,但其实还有另外一半,那就是实际该怎么实现,下篇文章将讨论这个问题。