关于2维的SLAM我们主要讲解两个算法,基本都源于<probabilistic robotics>。第一是基于滤波的扩展卡尔曼滤波SLAM,第二是基于图优化SLAM。前者现在基本上已经没有实际使用了,实际的应用3d的SLAM也基本是基于后者的。但扩展卡尔曼滤波SLAM还是很经典,值得学习。
从名字可以看出,扩展卡尔曼滤波(Extended Kalman Filter,以后我们就简写为EKF了)SLAM是基于扩展卡尔曼滤波算法的。而EKF又是基于卡尔曼滤波(Kalman Filter,我们简写维KF)的。所以自然要了解EKF-SLAM我们就先得了解EKF,KF。首先必须强调的是卡尔曼滤波应用范围很广,不单单是SLAM,虽然我们这儿就针对SLAM讲解。
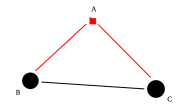
卡尔曼滤波是用来做什么的呢?回顾我们在第一讲的基本原理部分的Question1中发出的灵魂提问,通过速度传感器和时间我们能算出|BC|1,通过先知道|AC|,|AB|等我们能算出|BC|2,这两个值由于传感器的不准确和我们对小车匀速运动这个假设不准确而不同,并且都有别于真实值。所以最终我们应该相信哪一个?最简单的想法两种方法算出的|BC|求和再除以2,这样我们两种方法所得到的值都使用了。用式子表达就是|BC| = a * |BC|1 + b * |BC|2 ,此时取a = b = 0.5
但这样真的好吗?假如小车对|AB|,|AC|的测量非常不准确,最终使误差达到了0.1m,而通过另一种方法由于速度传感器比较准确,我们得到误差0.01m,很明显这时候我们更宁愿相信|BC|1而不是|BC|2。让最终的结果取|BC|1,|BC|2各占一半显然不好,应该让|BC|1占个0.9,让|BC|2占个0.1更好。具体这个a,b,即我们俗称的权重该怎么取值,就是卡尔曼滤波要解决的问题了。
卡尔曼滤波
在了解卡尔曼滤波之前,我们必须要了解两个东西,过程模型(process model)和测量模型(observation model)。用数学表达式写来如下。
了解卡尔曼滤波的同学自不必说,不了解状态空间或者状态空间的同学估计要崩了,之前还讲的那么浅显易懂的内容,现在突然就冒出来一大堆莫名其妙的公式,什么鬼???
其实这两个式子描述了两个很简单的东西,下面我细细道来。
第一个式子中,k是每一个时刻的代号,那么k-1就是上个时刻的代号。Xk-1就表示上一个时刻的状态,其中X表示的就是小车或者机器人状态,比如位置,方向等。Fk被称为状态转移矩阵(State Transition Matrix)。它连接上一时刻的状态和当前时刻的状态。我们来举个栗子。如果有小车作一个一维的直线运动,从位置A运动到位置B,我们估计它做匀速直线运动,它的状态包含速度和位置(状态是人为定的,如果你感兴趣我们可以把加速度什么的也包含进去,不过这儿没必要了),它在k-1时刻的状态记为Xk-1=(pk-1,vk-1)。由于小车做匀速直线运动我们知道他下一时刻的位置和速度可以估计为
写成矩阵形式,就是
那么一目了然状态转移矩阵就是那个方阵了。
有的同学可能要问了,状态转移矩阵后面还有两个东西呢Bkuk,外加wk。其中uk是控制输入(control input),Bk是输入控制模型(control input model)。比如我们想控制小车的速度而在k-1时刻人为增加了1倍的当前速度,对位置不做改变,那么我们完整的状态预测公式就改写为
既然Bkuk属于人为的控制,那么我们可以选择让他们全部为0,即不添加任何人为的控制干预,让状态任其发展,这也是很常见的。wk就是噪音了,我们假设小车是匀速直线运动,但是我们知道没有绝对的匀速直线运动,于是我们对估计的值加上了噪音来表示实际的位置和我们完美的匀速直线运动可能有差别。这个噪音通常建模为符合是均值为0的正态分布噪音。如果我们加上噪音,那么我们完整的过程模型就写为
其中
var1 , var2为正态分布的方差。这样一个有人为输入的,有噪音的匀速直线运动小车模型就建立好了。
回到(1)式中的第二个式子,被称为观察模型,这个就更简单了。其中Hk被称为观察模型矩阵,它表示我们测量量和我们需要的状态之间的关系。比如我们现在有速度传感器可以测小车的位置,但是没有速度传感器可以测小车的速度,那么我们的观察模型就应该如下写。
和式(1)中的每个量对应起来,显而易见H=[1 0],vk=v1。由于测量肯定也是不会完全准确的,所以我们对位置的测量结果在真实位置的基础之上也加了一个噪音,同样这个噪音我们建模为均值为0,方差维var3的高斯分布。即
有了式(2),我们相当于就对小车每时每刻的速度位置以及传感器会给出的值成功建模,理论上说这就是我们对一个系统状态所需要了解的一切了。上面两个式子,是对真实系统的模拟,如果我们想利用代码中估计系统的状态,我们就得想办法解决那不可预测的高斯噪音。这就需要卡尔曼滤波的帮助。
现在我先把注明的卡尔曼滤波公式从wiki搬过来。KF一般分为两个大步,第一步叫Predict预测,第二步叫Update更新。(一些小bb:每一步的名字我还是用英文打出来,因为学术上大家应该更多接触英文。解释时会翻译回中文。本来可以直接对wiki写好的公式截图的,但是为了方便文章文字内容插入的数学符号和整段公式的一致,我还是自己一个一个用latex打出来了。太麻烦了…感觉以后回因为不想打公式而放弃哈哈哈)
咱么一个一个来讲解。
第一个公式State Prediction状态预测。会根据上一时刻估计到的状态和运动模型来估计当前时刻的状态。
和前面一样,k是每一个时刻的代号,那么k-1就是上个时刻的代号。 就表示上一个时刻估计到的状态,其中X表示的就是小车或者机器人状态,比如位置,方向等。X头上的这个”∧”符号表示我们的状态是估计值,每一个X头上都有这个帽子符号,因为我们任何时候的状态都是估计值不是真实值。X的下标是两个k-1,表示这个X是上一时刻”最终”得到的状态。我们可以看到除了在第一步获得的
外我们还会在State Updation那一步获得一个
。也就是说每一次使用卡尔曼滤波我们会更新状态两次,其中
就会作为当前时刻估计的“最终状态”被下一时刻作为
使用。为了区分这两次更新,我们把State Prediction这一步更新的状态记为
。后面的例子会让大家更明了。
其实细致看来,这个式子和我们公式一中的过程模型基本一样,只是没有了噪音。是的,在这一步我们假设系统完全符合我们预设的模型在运动。而我们对噪音的处理方法体现在下一个式子Error Covariance Prediction误差协方差预测。
第二个式子Error Covariance Prediction误差协方差预测。
如果不了解协方差是什么的同学可以随意百度/google一下。误差协方差P是用来对状态估计准确度的一种测量。我们可以看到这一步更新的误差协方差矩阵的下标是k|k-1,同时在Error Covariance Updation那一步我们又更新了P,其下标是k|k。我们可以先简单地记忆为,由于误差协方差矩阵是对状态X准确度的测量,那么它就要和我们的状态的下标的更新一一对应。
这个式子中Pk-1|k-1是上一步在Error Covariance Updation处更新的协方差矩阵,Qk是被称为过程噪音协方差矩阵(process noise covariance),它体现我们对模型准确度的一种估计。比如我们对小车匀速直线运动这个模型不是百分之百的自信,考虑到各种环境因素我们觉得式(2)中的位置估计的公式我们要加个0.1的方差来描述它的不确定程度,而速度估计的公式我们要加个0.01的方差来描述它的不确定程度,这时候我们就应该把Qk写为下面的样子。
当我们这样写下时,意味着我们认为某一时刻估计位置
的估计是符合均值为实际位置
,方差为0.1的正态分布,估计速度
符合均值为实际速度为
,方差为0.01的正态分布即
和前面讲的噪音符合高斯分布联系起来想一下原因…很感兴趣的可以参考<Estimiation with Applications to Tracking & Navigation>第一章的1.14以及之前的一些内容。的非对角线元素如果不为0意味着我们估计的状态之间还有关联。我在使用中通常只设置对角线元素,如果发现结果很不好才考虑设置非对角线元素。
你写入中的方差要和实际的模型的方差类似(当然一样更好),这样卡尔曼滤波才会有好的效果,比如上面如果我们以为
而实际的模型方差应该是1,那么我们最后得到的状态估计结果可能就会很不好。那么问题来了,我怎么知道
里该填写多少呢?或者换句话说,我怎么知道我的模型有多准确呢?大多数情况下的答案是你不能知道。
很多人会根据卡尔曼滤波输出的表现去调整里的值,或者根据利用一些算法去帮助我们找到合适的值。这一门专门的学问了,被称为卡尔曼滤波参数整定。我的第一篇论文<Weak in the NEES?: Auto-tuning Kalman Filterswith Bayesian Optimization>即是讲述这个内容的,第二篇论文还没出炉,不过是关于第一篇的应用引深。作为新手,我们给你举例子时通常给出了
的值,但是你需要记住的是实际上要确认
的值不是那么容易的。
最后说一下为什么公式长这个样子呢?
的物理意义是什么?为什么这么算就可以更新误差协方差?…….哪来这么多问题!先记住!
:扩展卡尔曼滤波SLAM理论部分a")
问题多.jpeg
如果你的运动模型能写为式(2)那种矩阵形式,代码应用时套这个公式就可以了,还有什么比直接套公式更爽的事呢。如果你想要知道为什么这么写,可以去搜索一下卡尔曼滤波推导过程,又是一小波坑等你填我是不想帮你填了,又是一大堆公式23333。我推荐的是先看看类似于我这种暴力教程加代码,应用一下,再去了解原理,会理解更深。
第三个式子,在update里,计算Kalman Gain(卡尔曼增益)。
卡尔曼增益的作用,就是分配模型预测的状态和传感器测量的状态之间的权重。公式中被称为观测模型矩阵,起到连接观测量和状态之间的关系。接着用我们上面一维小车的例子,如果我们现在有一个传感器可以直接测量小车位置,那么我们会得到公式1观察模型中的
。
即前面提到的观察模型矩阵。需要隆重介绍的是观察噪音协方差矩阵
,这个矩阵和
的性质是一样的,不过代表的是对测量的值的不准确度的估计。如果我们知道位置误差的方差大概是0.1,那么此时
和
有个很不同的一点,
的值开始你基本全靠猜…但是
你却可以有所了解,往往在购买一个稍微好一点的传感器时,它会标注这个传感器会在什么条件时产生标准差为多少的噪音,标准差的平方就可以放进
里。传感器自身提供的参数不一定准确或者适应你的环境,但是你至少有一个初值,可以在这个值周围调整参数。
如果你想要知道为什么卡尔曼增益是这样求,也得去看看卡尔曼滤波的推导过程了。在讲完第四个式子后,我们来聊一个很直观的东西,来让你觉得这个这个卡尔曼增益还”蛮有道理”的。
第四个式子,状态更新。这一步的目的很明了,根据获得的卡尔曼增益和测量值对状态进一步更新,由
到
。
其中是传感器的测量值,这是不用估计的,传感器显示多少就是多少。大家回顾式一可以发现测量模型为
。而
是我们预估的测量值,认为真实状态就为
的完美情况。如果测量值很不准确,则代表其方差很大,这会反映在我们的噪音协方差矩阵
比较大上,在求卡尔曼增益部分,咱们可以把求逆换个写法
在分母部分,它越大,卡尔曼增益就会越小,那么
就会乘以一个比较小的值,直白点理解就是我们趋于不相信测量部分,因为它权重比较小。反之
小,测量部分权重则大,我们会比较相信测量部分。
这儿可能有些同学会犯迷糊,上面这些变量都是矩阵,什么叫矩阵比较大/比较小呢?这其实是对矩阵求范数,不了解的同学可以去百度一下,不过我们这儿不了解那个东西也没关系。我们大可以想象如果所有的矩阵都是单个数字的特殊情况,能非常直观了解卡尔曼增益这个权重怎么工作的。
上面我们的推论是噪音协方差矩阵比较大,我们就会得到卡尔曼增益比较小,从而偏向于不相信测量部分。那么如果我们的过程协方差矩阵比较大,我们就应该偏向于相信测量部分,那么此时我们的卡尔曼增益应该比较大才对,我们试一下能不能由已经存在的公式得出这个结论。
这儿我们假设所有矩阵都是一维(一个数)的情况进行一些暴力操作,这时候矩阵转置没有效果
这时候我们把求
的式子带入,我们可以得到
这就很明显了,越大,
越小,从而
越大,我们会偏向于相信测量部分。这完全符合我们对于权重的直观理解,即如果传感器的误差大,我们应该分配少一些的权重给传感器的测量,如果我们对运动模型的估计误差大,我们就应该分配多一些的权重给传感器的测量。尽管我们是在一维的情况下得到这些结论,但这对高维是完全适用的。
更新完状态后,我们就进入第五个式子,更新误差协方差矩阵,用于作为下一次迭代的
。这个式子没有啥好聊的了,大家写代码的时候照着它来即可。
我们介绍完了卡尔曼滤波的一到五式,我想最重要需要了解的信息就是,它是基于我们假设的过程噪音(表现中)和测量噪音(表现
中)为我们的运动模型获得的状态和传感器测量得到的状态分配一个权重。
接下来我们根据上面的一维小车运动的例子来写一写它的卡尔曼滤波的C++(伪)代码大概是什么样子。并不是完整的代码,只是给大家一个直观的理解。假设我们使用Eigen库来进行矩阵操作
Eigen::MatrixXd P = Eigen::MatrixXd::Zero(2);//initial error covariance
Eigen::VectorXd x(2) = Eigen::VectorXd::Zero(2);//initial state
Eigen::VectorXd u(2) = Eigen::VectorXd::Zero(2);; //control input
Eigen::VectorXd z(1);//measurement
//Initialize Q,R,F,H
Eigen::MatrixXd Q(2,2),R(1,1),F(2,2),H(1,2),B(2,2);
Q(0,0) = 0.1;
Q(0,1) = 0;
Q(1,0) = 0;
Q(1,1) = 0.01;
R(1,1) = 0.1;
H(0,0) = 1.0;
H(0,1) = 0.0;
F(0,0) = 1.0;
F(0,1) = 0.1;
F(1,0) = 0;
F(1,1) = 1.0;
B(0,0) = 0;
B(0,1) = 0;
B(1,0) = 0;
B(1,1) = 1;
//Implement Kalman Filter
for(;;){
u(0) = 0;
u(1) = x(1);
z = GetCurrentMeasurement();
//Predict
x = F*x + B*v;
P = F*P*F.transpose() + Q;
//Update
K = P*H.transpose()*(H*P*H.transpose()+R).inverse();
x = x + K*(z - H*x);
P = (Eigen::MatrixXd::Identity(2)-K*H)*P;
}
程序非常简短,下面简要说明一下。程序变量的名字和前面文章讲解卡尔曼滤波时的名字一一对应,比如误差协方差矩阵名字叫P,这儿连下标k|k-1都不用了,因为在for循环里更新的时候后一时刻的状态就在计算时把前一时刻状态替换了。
首先初始化误差协方差矩阵P为2乘2的零矩阵。误差协方差矩阵对应我们当前状态的方差,把它设置为0代表我们对当前的状态值有绝对的把握。
我们的初始状态x随后设置为2乘1的0向量,代表初始位置和速度都是0。现实情况中,即使初始的状态我们可能也没有把握,此时误差协方差矩阵也就不一定是0了,而是根据现实情况瞎猜一下hhhh。
随后初始化控制输入向量和测量量z。
Q,R,H,F和我们之前说的过程噪音协方差矩阵,测量噪音协方差矩阵,观察模型矩阵,状态转移矩阵一一对应,请自行回看前面他们如何定义并赋值的。这里注意一下F(0,1)在原文中是,我们假设传感器每0.1s获得一次数据,这儿就设置为0.1了。
初始化完成之后进入for循环进行状态更新,由于我们假设控制输入为,所以先把时刻k-1的速度赋值给
。每一时刻传感器的测量量不同,我们假设有个
GetCurrentMeasurement()函数能帮助我们获得传感器当前数值。
然后就进入卡尔曼滤波的标准五步即是predict和update。我们前面的公式只有五步,代码没有冗余也就只有五步。请自行回看和公式变量一一对应。
尽管新手看卡尔曼滤波的公式可能觉得莫名其妙很困难,但是代码如果和公式变量对应上后实施起来却非常简单,只有五行,你写不了上当写不了吃亏,只有五行!
当然虽然实际情况会复杂不少,但是这几行核心的代码不会有大的改变。
请大家好好研读上面的公式,例子和伪码,如果还是完全没Get到点,去看看其他网上教程吧。讲卡尔曼滤波的很多,如果还是没Get到点,我也不管了(手动滑稽),因为接下来就要进入扩展卡尔曼滤波了。
扩展卡尔曼滤波
扩展卡尔曼滤波是卡尔曼滤波的进阶版,差别不大。扩展卡尔曼滤波针对的是非线性系统。非线性系统更符合现实生活中我们遇到的实例。我们前面讲的一维小车的运动模型,它的状态预测能写成矩阵形式
或者说简写为
就单论表达式,非线性模型的状态预测或者更新,是无法分离出单独的状态并写成矩阵形式的。什么意思呢,假设小车不是匀速运动,由于某种不可描述的神秘原因,它当前时刻的速度,是上一时刻的速度的正弦值加上一个控制输入。我们可以把上面的式子改写为
咦,这不还是矩阵形式吗?确实是矩阵形式,但如果画个图的话,和
的关系不能再由一个直线表示出来了,而是一条和三角函数相关的曲线,因此我们称它是非线性的。对于非线性的公式,我们再写成矩阵形式没有意义,因为
不再是状态转移矩阵了。状态转移矩阵需要把之前状态转移到当前状态
,而上面这个矩阵把
转移到了当前状态。定义都不符合,更不能拿来使用了。因此对于非线性运动模型,我们也不挣扎着要写成矩阵形式了,写成一个抽象的函数就完事儿了。
对应到卡尔曼滤波中,我们的状态预测(state prediction)公式就应该抽象写为
不见了,因为我们目前不知道他们是什么样子。那么问题来了,无论如何,卡尔曼滤波的是需要状态转移矩阵来进行状态估计的。现在我们没有咋办?估计一个呗。扩展卡尔曼滤波通过状态转移式对状态的雅各比矩阵来获得状态转移矩阵。即
对于我们刚才非线性运动的一维运动的小车,卡尔曼滤波中的状态预测公式完全展开就应该写为
正如我们刚才提到的,对于非线性的运动写成矩阵形式没有太大意义,所以我们写回一般形式
对7式按着6式求雅各比矩阵,6式中的即
,
即
,
即7式的上式,
即7式的下式。求完导数我们可得雅各比矩阵
这么一来用于扩展卡尔曼滤波这一步的
便有了。此步的
和线性卡尔曼滤波器没有差别。
类似地,如果观察(测量)模型是线性的,则可以简写为,在我们一维小车的例子中,它是
我们直接观察就看出。如果观察模型不是线性的,我们用估计
同样的方法估计
,即非线性情况下我们的观察模型应记为
那么
我就不再强行举个非线性测量模型的例子了,免得看懵。为什么这样的雅各比矩阵可以作为状态转移矩阵和测量矩阵的估计呢?又到了让同学们自己去看的时间了(其实是看过太久自己给忘了)。我们需要记住的是,这种估计方式把卡尔曼滤波的“完美性质”给毁了,卡尔曼滤波被称为最优的无偏滤波器,但是扩展卡尔曼滤波以及其他形式的用来解决非线性模型的卡尔曼滤波比如UKF(unscented kalman filter)等,都不会再满足最优和无偏这两个性质,这两个性质的意思大家也自己去查。UKF的估值相较于EKF还是能更接近真实值,两个针对卡尔曼滤波在非线性模型中的应用都很广,UKF是因为估值更准确,EKF是因为实施和理论都更简单,更多人懂。
综上,扩展卡尔曼滤波和卡尔曼滤波非常类似,同样有五步,我们把它写为
其中来源于6式,
来源于8式。
总结
至此我们非常简要地解释了卡尔曼滤波和扩展卡尔曼滤波。我没有把卡尔曼的推导详细地解释一遍,那样也太累了,那是专门讲解卡尔曼滤波或者状态估计的书籍的任务,我还是着重于怎样应用,无论程序再怎么fancy,应用就是那五步公式为核心。这一讲连图片都没有,大家可能会看地比较懵,你可以私下找我讨论或者翻阅相关书籍。尽管我已经尽量简短地提及理论部分了,但是我们下一讲还得是理论。因为有了扩展卡尔曼滤波的基础,我们得把它如何应用于SLAM的详细阐述出来,下下讲才会进入程序。