目前机器人行业最火的ROS,人工智能/机器学习方面相对较火的tensorflow,两者结合肯定是让机器人锦上添花,功能更加丰富完善。 正好在GitHub上看到了tensorflow的ROS功能包,验证功能包可行性之后,给大家分享一下。 先看一下效果: TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,效果非常好,不得不承认谷歌太强了。
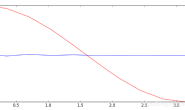
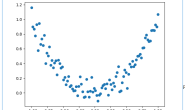
 而且可以看到,准确率还是非常高的。 版本要求:Ubuntu16.04+ROS Kinetic
而且可以看到,准确率还是非常高的。 版本要求:Ubuntu16.04+ROS Kinetic
步骤:
(1) 安装ROS kinetic kame (2) 安装相机依赖
sudo apt-get install ros-kinetic-usb_cam ros-kinetic-openni2-launch
(3) 安装tensorflow 安装tensorflow坑很多,这里不再说,不同电脑情况不太一样 (4) clone功能包
cd ~/catkin_ws/src
git clone https://github.com/Kukanani/vision_msgs.git
git clone https://github.com/osrf/tensorflow_object_detector.git
然后编译 (5) 插上相机进行测试
roslaunch tensorflow_object_detector usb_cam_detector.launch
 看一下最关键的源码,代码很短,主要是基于模型库的匹配,有兴趣可以深入阅读:
看一下最关键的源码,代码很短,主要是基于模型库的匹配,有兴趣可以深入阅读:
#!/usr/bin/env python
import os
import sys
import cv2
import numpy as np
try:
import tensorflow as tf
except ImportError:
print("unable to import TensorFlow. Is it installed?")
print(" sudo apt install python-pip")
print(" sudo pip install tensorflow")
sys.exit(1)
# ROS related imports
import rospy
from std_msgs.msg import String , Header
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
from vision_msgs.msg import Detection2D, Detection2DArray, ObjectHypothesisWithPose
# Object detection module imports
import object_detection
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
# SET FRACTION OF GPU YOU WANT TO USE HERE
GPU_FRACTION = 0.4
######### Set model here ############
MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
# By default models are stored in data/models/
MODEL_PATH = os.path.join(os.path.dirname(sys.path[0]),'data','models' , MODEL_NAME)
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_PATH + '/frozen_inference_graph.pb'
######### Set the label map file here ###########
LABEL_NAME = 'mscoco_label_map.pbtxt'
# By default label maps are stored in data/labels/
PATH_TO_LABELS = os.path.join(os.path.dirname(sys.path[0]),'data','labels', LABEL_NAME)
######### Set the number of classes here #########
NUM_CLASSES = 90
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
## Loading label map
# Label maps map indices to category names, so that when our convolution network predicts `5`,
# we know that this corresponds to `airplane`. Here we use internal utility functions,
# but anything that returns a dictionary mapping integers to appropriate string labels would be fine
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Setting the GPU options to use fraction of gpu that has been set
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = GPU_FRACTION
# Detection
class Detector:
def __init__(self):
self.image_pub = rospy.Publisher("debug_image",Image, queue_size=1)
self.object_pub = rospy.Publisher("objects", Detection2DArray, queue_size=1)
self.bridge = CvBridge()
self.image_sub = rospy.Subscriber("image", Image, self.image_cb, queue_size=1, buff_size=2**24)
self.sess = tf.Session(graph=detection_graph,config=config)
def image_cb(self, data):
objArray = Detection2DArray()
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
except CvBridgeError as e:
print(e)
image=cv2.cvtColor(cv_image,cv2.COLOR_BGR2RGB)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = np.asarray(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
(boxes, scores, classes, num_detections) = self.sess.run([boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
objects=vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=2)
objArray.detections =[]
objArray.header=data.header
object_count=1
for i in range(len(objects)):
object_count+=1
objArray.detections.append(self.object_predict(objects[i],data.header,image_np,cv_image))
self.object_pub.publish(objArray)
img=cv2.cvtColor(image_np, cv2.COLOR_BGR2RGB)
image_out = Image()
try:
image_out = self.bridge.cv2_to_imgmsg(img,"bgr8")
except CvBridgeError as e:
print(e)
image_out.header = data.header
self.image_pub.publish(image_out)
def object_predict(self,object_data, header, image_np,image):
image_height,image_width,channels = image.shape
obj=Detection2D()
obj_hypothesis= ObjectHypothesisWithPose()
object_id=object_data[0]
object_score=object_data[1]
dimensions=object_data[2]
obj.header=header
obj_hypothesis.id = object_id
obj_hypothesis.score = object_score
obj.results.append(obj_hypothesis)
obj.bbox.size_y = int((dimensions[2]-dimensions[0])*image_height)
obj.bbox.size_x = int((dimensions[3]-dimensions[1] )*image_width)
obj.bbox.center.x = int((dimensions[1] + dimensions [3])*image_height/2)
obj.bbox.center.y = int((dimensions[0] + dimensions[2])*image_width/2)
return obj
def main(args):
rospy.init_node('detector_node')
obj=Detector()
try:
rospy.spin()
except KeyboardInterrupt:
print("ShutDown")
cv2.destroyAllWindows()
if __name__=='__main__':
main(sys.argv)