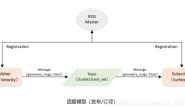
- ROS中的图像数据。
- 摄像头标定。
- ROS+Opencv应用实例(人脸识别、物体跟踪)。
- 二维码识别。
- 扩展内容:物体识别与机器学习。
启动摄像头:没有安装的话参照下面命令安装一下:
sudo apt-get install ros-kinetic-usb-cam
安装完成之后就可以启动摄像头了:
roslaunch usb_cam usb_cam-test.launch
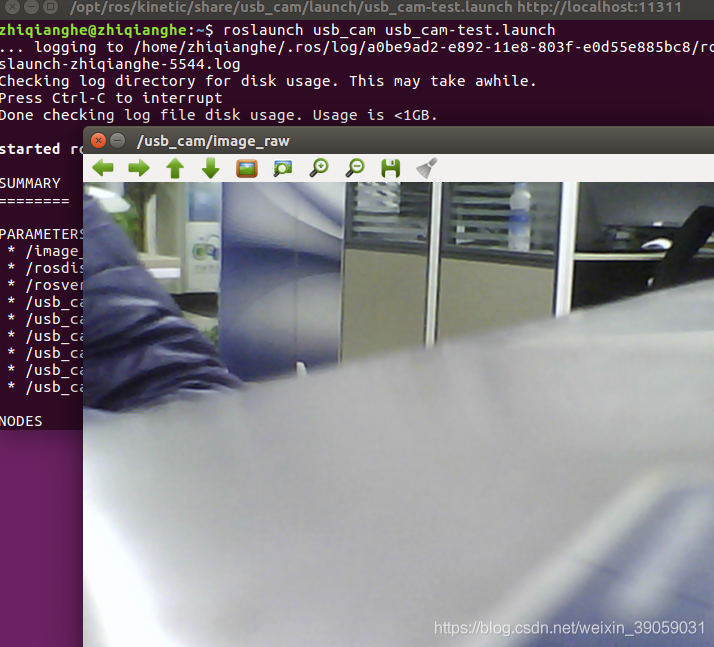 我们接下来看一下这个摄像头的驱动到底发布了哪些数据:
我们接下来看一下这个摄像头的驱动到底发布了哪些数据:
 我们刚才的摄像头就是usb_cam/image_raw这个话题,我们接下来看一下它发布的消息的具体类型:
我们刚才的摄像头就是usb_cam/image_raw这个话题,我们接下来看一下它发布的消息的具体类型:
机器视觉-摄像头标定-ROS+OpenCv-人脸识别-物体跟踪-二维码识别") 第一行是这个话题消息的类型,从第一行可以看到,是sensor_msg这样一个类型。那这样一种图像消息里面的成员变量有哪些呢?通过以下命令我们可以打印出这样的一个消息类型里面的具体成员变量。
第一行是这个话题消息的类型,从第一行可以看到,是sensor_msg这样一个类型。那这样一种图像消息里面的成员变量有哪些呢?通过以下命令我们可以打印出这样的一个消息类型里面的具体成员变量。
机器视觉-摄像头标定-ROS+OpenCv-人脸识别-物体跟踪-二维码识别") 里面的具体的成员变量的解释如下:
里面的具体的成员变量的解释如下:
- Header:很多话题消息里面都包含的。里面有三个内容:消息头,包含消息序号,时间戳和绑定坐标系。消息的序号表示我们这个消息发布是排第几位的,并不需要我们手动去标定,每次发布消息的时候会自动地去累加; 绑定坐标系表示的是我们是针对哪一个坐标系去发布的。header有时候也不需要去配置。
- height:图像的纵向分辨率
- width:图像的横向分辨率
- encoding:图像的编码格式,包含RGB、YUV等常用格式,都是原始图像的编码格式,不涉及图像压缩编码;
- is_bigendian: 图像数据的大小端存储模式;
- step:一行图像数据的字节数量,作为数据的步长参数;
- data:存储图像数据的数组,大小为step×height个字节。
在ros里面提供了我们另外一种压缩图像的类型,
机器视觉-摄像头标定-ROS+OpenCv-人脸识别-物体跟踪-二维码识别")
- format:图像的压缩编码格式(jpeg、png、bmp)。
- data:存储图像数据数组。
原教学视频里面还说了深度摄像头的相关知识,我这里没有深度摄像头,所以有需要的可以自己去看源视频,在我的github里面可以找到视频的相关信息。
摄像头标定
摄像头这种精密仪器对光学器件的要求较高,由于摄像头内部与外部的一些原因,生成的物体图像往往会发生畸变,为避免数据源造成的误差,需要针对摄像头的参数进行标定。 为了保证我们图像的质量,在采集图像之前,我们需要对摄像头做标定。 安装标定功能包:
sudo apt-get install ros-kinetic-camera-calibration
启动摄像头,robot_vision这个包在第五讲的源代码包里面有。
roslaunch robot_vision usb_cam.launch
启动成功之后没有摄像头的界面,因为包里面是没有去打开摄像头的:
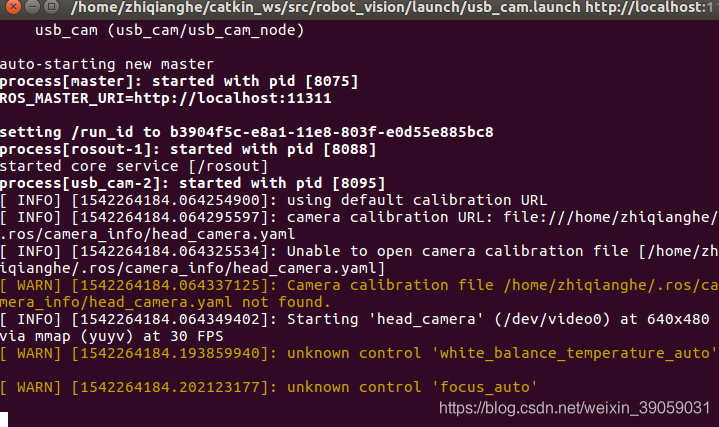 启动标定包:
启动标定包:
rosrun camera_calibration cameracalibrator.py --size 8x6 --square 0.024 image:=/usb_cam/image_raw camera:=/usb_cam
以上程序就会启动我们标定功能包的一个标定程序。
 然后我们打开在功能包里面的doc文件,就可以看到这样一个黑白相见的图片,然后我们做旋转等等操作,移动几遍,标定好了之后如下图所示:
然后我们打开在功能包里面的doc文件,就可以看到这样一个黑白相见的图片,然后我们做旋转等等操作,移动几遍,标定好了之后如下图所示:
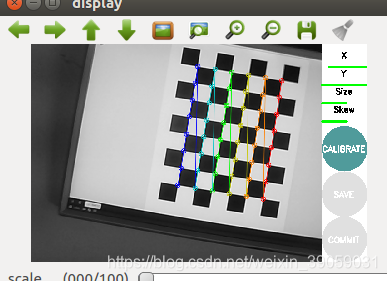 标定成功之后会显示灰绿色的这个按钮颜色。之后我们再点击这个绿色的按钮,然后图形将该会卡住,在后台做一些计算,运行一会之后就能看到如下效果:
标定成功之后会显示灰绿色的这个按钮颜色。之后我们再点击这个绿色的按钮,然后图形将该会卡住,在后台做一些计算,运行一会之后就能看到如下效果:
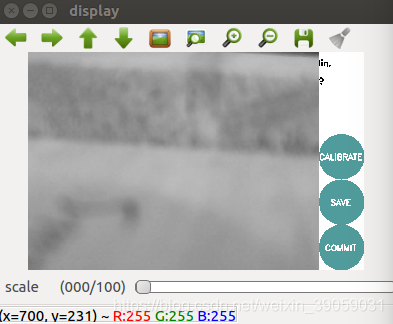 我们接着点击save按钮。之后在终端里面会告诉我们标定的数据存放在哪个路径下面:
我们接着点击save按钮。之后在终端里面会告诉我们标定的数据存放在哪个路径下面:
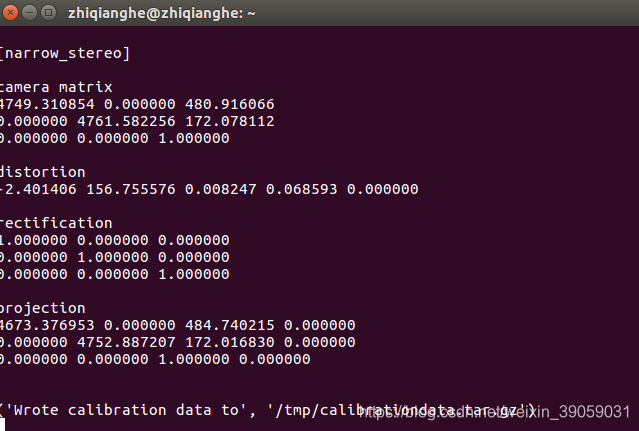 到此,标定就已经结束了。 rosrun camera_calibration cameracalibrator.py –size 8×6 –square 0.024 image:=/usb_cam/image_raw camera:=/usb_cam
到此,标定就已经结束了。 rosrun camera_calibration cameracalibrator.py –size 8×6 –square 0.024 image:=/usb_cam/image_raw camera:=/usb_cam
- size:标定棋盘格的内部角点个数,这里使用的棋盘一共有六行,内部8个角点;
- square:这个参数对应每个棋盘的边长,单位是米;
- image和camera:设置摄像头发布的图像话题。
 我们找到刚刚产生的文件,将其解压缩,如下图所示:
我们找到刚刚产生的文件,将其解压缩,如下图所示:
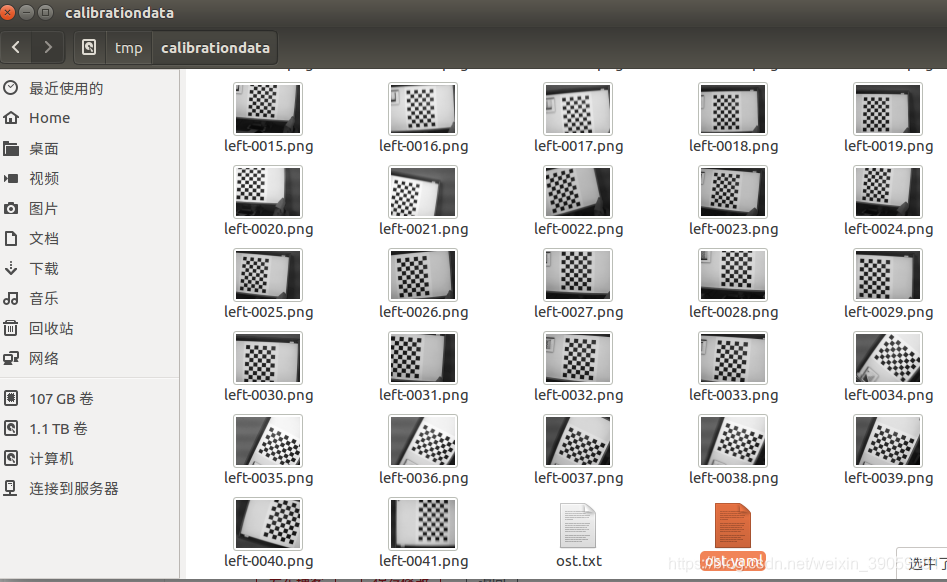 然后里面有用的文件是 ost.yaml。然后放入我们的功能包,并将其重命名就可以了:
然后里面有用的文件是 ost.yaml。然后放入我们的功能包,并将其重命名就可以了:
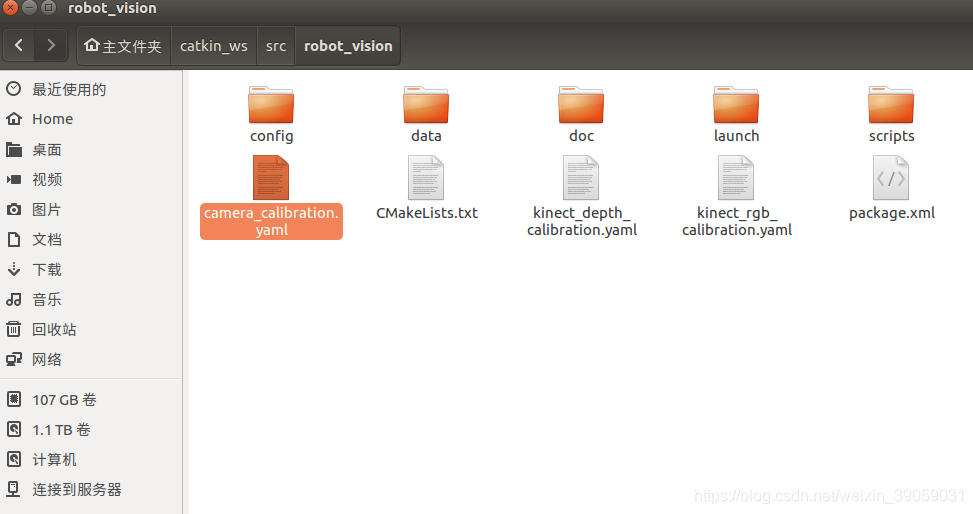 Kinetic标定:
Kinetic标定:
 之后的操作都类似,具体可以参考原视频。
之后的操作都类似,具体可以参考原视频。
Opencv
Open Source Computer Vision Library 在ROS当中完成Opencv的安装:
sudo apt-get install ros-kinetic-vision-opencv libopencv-dev python-opencv
ROS与Opencv之间的数据连接是通过CvBridge来实现的。ROS Image Message与OpenCv Ipllmage之间连接的一个桥。 接下来我们测试一下:
roslaunch robot_vision usb_cam.launch
这个命令运行完之后是没有结果输出的,我们之后再启动节点:
rosrun robot_vision cv_bridge_test.py
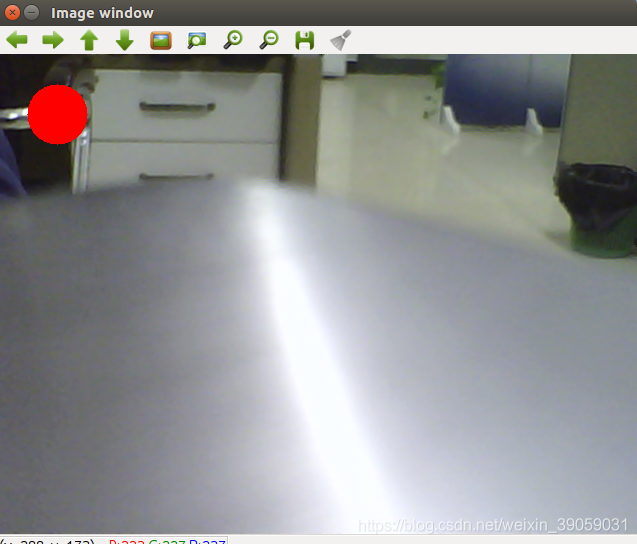 再打开ROS测试:
再打开ROS测试:
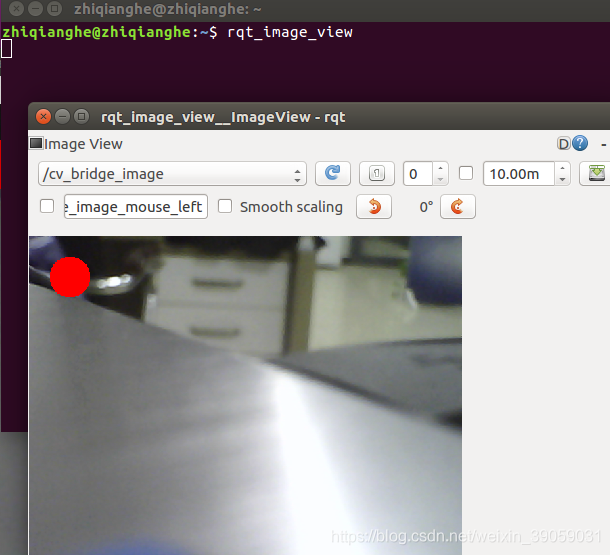 显示成功之后表示测试没有问题。 第一张图片显示的是opencv的图像,是经过opencv的接口,与ros没有关系。而第二张图片是通过ros当中订阅话题来显示的。首先是在ros当中启动了一个节点,那么发布的消息也是ros消息的这种类型,然后通过bridge转接到了opencv系统,然后在opencv里面完成一些处理,像在左上角画出一个圈,并且把处理的图片通过opencv显示出来,再通过bridge发回到ros系统里面,ros再订阅这个话题就可以了。 我们可以看一下 刚刚的命令-《 rosrun robot_vision cv_bridge_test.py 》启动的这个节点:
显示成功之后表示测试没有问题。 第一张图片显示的是opencv的图像,是经过opencv的接口,与ros没有关系。而第二张图片是通过ros当中订阅话题来显示的。首先是在ros当中启动了一个节点,那么发布的消息也是ros消息的这种类型,然后通过bridge转接到了opencv系统,然后在opencv里面完成一些处理,像在左上角画出一个圈,并且把处理的图片通过opencv显示出来,再通过bridge发回到ros系统里面,ros再订阅这个话题就可以了。 我们可以看一下 刚刚的命令-《 rosrun robot_vision cv_bridge_test.py 》启动的这个节点:
 我们首先看一下main函数:
我们首先看一下main函数:
if __name__ == '__main__':
try:
# 初始化ros节点
rospy.init_node("cv_bridge_test")
rospy.loginfo("Starting cv_bridge_test node")
image_converter()
rospy.spin()
except KeyboardInterrupt:
print "Shutting down cv_bridge_test node."
cv2.destroyAllWindows()
在main函数里面,第一行我们初始化这个节点,第二行输出这个节点的日志信息,第三行调用图像转换函数,第四行通过spin等待回调函数。 之后看一下image_converter类函数。
class image_converter:
def __init__(self):
# 创建cv_bridge,声明图像的发布者和订阅者
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
self.bridge = CvBridge()
self.image_sub = rospy.Subscriber("/usb_cam/image_raw", Image, self.callback)
def callback(self,data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
except CvBridgeError as e:
print e
# 在opencv的显示窗口中绘制一个圆,作为标记
(rows,cols,channels) = cv_image.shape
if cols > 60 and rows > 60 :
cv2.circle(cv_image, (60, 60), 30, (0,0,255), -1)
# 显示Opencv格式的图像
cv2.imshow("Image window", cv_image)
cv2.waitKey(3)
# 再将opencv格式额数据转换成ros image格式的数据发布
try:
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
except CvBridgeError as e:
print e
在这个类的初始化里面,声明了一个发布者和一个订阅者。订阅者订阅的是usb摄像头发布的话题“”/usb_cam/image_raw“,后面还有一个callback函数。发布者发布的是最终经过opencv处理之后的图像,也就是我们之前在rqt工具里面看到的图像 ”cv_bridge_image“。之后还调用了一下CvBridge。self.bridge = CvBridge()。 订阅者接收到图像之后就调用回调函数callback: 在callback函数里面,我们将从ros中接收到的图片数据转换为opencv能够读取的格式。通过调用CvBridge函数就可以实现上述功能,最终的cv_image就是opencv能够去处理的格式。之后我们使用opencv函数里面的一些函数cv2.circle去绘制圆。然后将其显示出来。之后我们再通过bridge.cv2_to_imgmsg将其转换为ros系统的数据格式,再将其发布出去。 这里的话需要重点去知道两个函数: imgmsg_to_cv2():将ros图像消息转换成OpenCv图像数据; cv2_to_imgmsg():将OpenCv格式的图像数据转换成ros图像消息;
人脸检测
基于Haar特征的级联分类器检测算法主要步骤:
- 灰阶色彩转换
- 缩小摄像头图像
- 直方图均衡化
- 检测人脸
代码文件以及视频解释等相关文件在我github里面都可以去找到,这里不方便贴出来。分别在三个终端运行以下命令:
roslaunch robot_vision usb_cam.launch
roslaunch robot_vision face_detector.launch
rqt_image_view
显示结果:
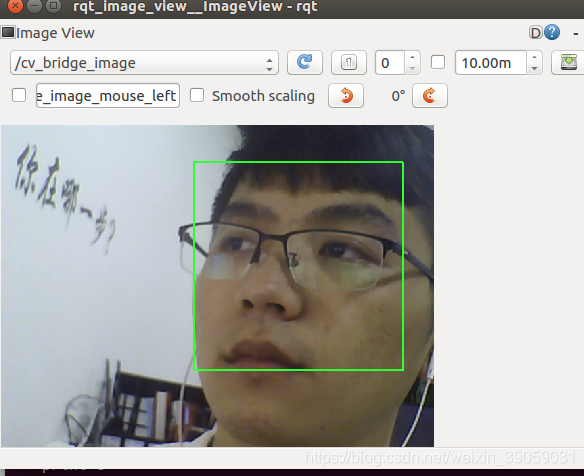 我们接下来看一下代码:
我们接下来看一下代码:
if __name__ == '__main__':
try:
# 初始化ros节点
rospy.init_node("face_detector")
faceDetector()
rospy.loginfo("Face detector is started..")
rospy.loginfo("Please subscribe the ROS image.")
rospy.spin()
except KeyboardInterrupt:
print "Shutting down face detector node."
cv2.destroyAllWindows()
我们首先需要初始化ros节点,之后调用人脸检测器,然后打印出日志信息,等待回调函数等等。
class faceDetector:
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 获取haar特征的级联表的XML文件,文件路径在launch文件中传入
cascade_1 = rospy.get_param("~cascade_1", "")
cascade_2 = rospy.get_param("~cascade_2", "")
# 使用级联表初始化haar特征检测器
self.cascade_1 = cv2.CascadeClassifier(cascade_1)
self.cascade_2 = cv2.CascadeClassifier(cascade_2)
# 设置级联表的参数,优化人脸识别,可以在launch文件中重新配置
self.haar_scaleFactor = rospy.get_param("~haar_scaleFactor", 1.2)
self.haar_minNeighbors = rospy.get_param("~haar_minNeighbors", 2)
self.haar_minSize = rospy.get_param("~haar_minSize", 40)
self.haar_maxSize = rospy.get_param("~haar_maxSize", 60)
self.color = (50, 255, 50)
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
grey_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 创建平衡直方图,减少光线影响
grey_image = cv2.equalizeHist(grey_image)
# 尝试检测人脸
faces_result = self.detect_face(grey_image)
# 在opencv的窗口中框出所有人脸区域
if len(faces_result)>0:
for face in faces_result:
x, y, w, h = face
cv2.rectangle(cv_image, (x, y), (x+w, y+h), self.color, 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
def detect_face(self, input_image):
# 首先匹配正面人脸的模型
if self.cascade_1:
faces = self.cascade_1.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
# 如果正面人脸匹配失败,那么就尝试匹配侧面人脸的模型
if len(faces) == 0 and self.cascade_2:
faces = self.cascade_2.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
return faces
def cleanup(self):
print "Shutting down vision node."
cv2.destroyAllWindows()
我们首先初始化一些参数,之后当我们接收到ros来的图像的话,我们调用回调函数,将图像转换成OpenCv的数据格式,在opencv里面创建灰度图像,创建平衡直方图,减少光线影响,之后检测人脸,这些操作都是通过调用函数来实现的,然后将人脸用一个方框框出来。
机器视觉-物体跟踪
通过第一帧与后面帧图像特征点的匹配,来实现物体跟踪,流程如下:
- 图像输入
- 特征点采样
- 两帧图像灰度值对比
- 特征点估计
- 特征点过滤
- 结果输出
代码文件以及视频解释等相关文件在我github里面都可以去找到,这里不方便贴出来。分别在三个终端运行以下命令:
roslaunch robot_vision usb_cam.launch
roslaunch robot_vision motion_detector.launch
rqt_image_view
这里效果太差,就不给予演示了。函数如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import rospy
import cv2
import numpy as np
from sensor_msgs.msg import Image, RegionOfInterest
from cv_bridge import CvBridge, CvBridgeError
class motionDetector:
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 设置参数:最小区域、阈值
self.minArea = rospy.get_param("~minArea", 500)
self.threshold = rospy.get_param("~threshold", 25)
self.firstFrame = None
self.text = "Unoccupied"
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# 使用两帧图像做比较,检测移动物体的区域
if self.firstFrame is None:
self.firstFrame = gray
return
frameDelta = cv2.absdiff(self.firstFrame, gray)
thresh = cv2.threshold(frameDelta, self.threshold, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
binary, cnts, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
# 如果检测到的区域小于设置值,则忽略
if cv2.contourArea(c) < self.minArea:
continue
# 在输出画面上框出识别到的物体
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (50, 255, 50), 2)
self.text = "Occupied"
# 在输出画面上打当前状态和时间戳信息
cv2.putText(frame, "Status: {}".format(self.text), (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(frame, "bgr8"))
def cleanup(self):
print "Shutting down vision node."
cv2.destroyAllWindows()
if __name__ == '__main__':
try:
# 初始化ros节点
rospy.init_node("motion_detector")
rospy.loginfo("motion_detector node is started...")
rospy.loginfo("Please subscribe the ROS image.")
motionDetector()
rospy.spin()
except KeyboardInterrupt:
print "Shutting down motion detector node."
cv2.destroyAllWindows()
里面代码的意思跟之前的也都差不多。不同点在,这里主要是基于图像差异识别到运动的物体,最后标识,识别并结果发布。
二维码识别
安装以下功能包:
sudo apt-get install ros-kinetic-ar-track-alvar
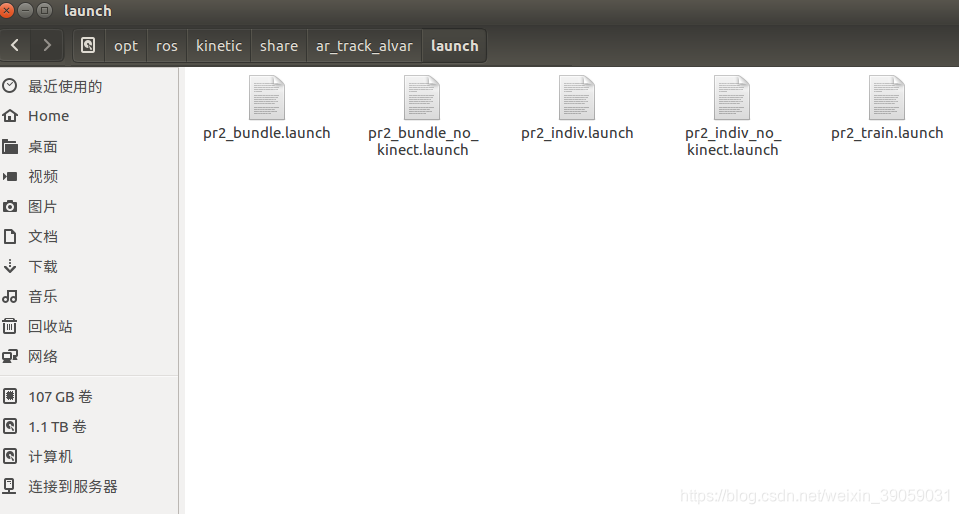 我们可以在以下目录中找到相应的安装的文件。这个功能包也有很多工具能够帮助我们去创建二维码。
我们可以在以下目录中找到相应的安装的文件。这个功能包也有很多工具能够帮助我们去创建二维码。
roscore rosrun ar_track_alvar createMarker
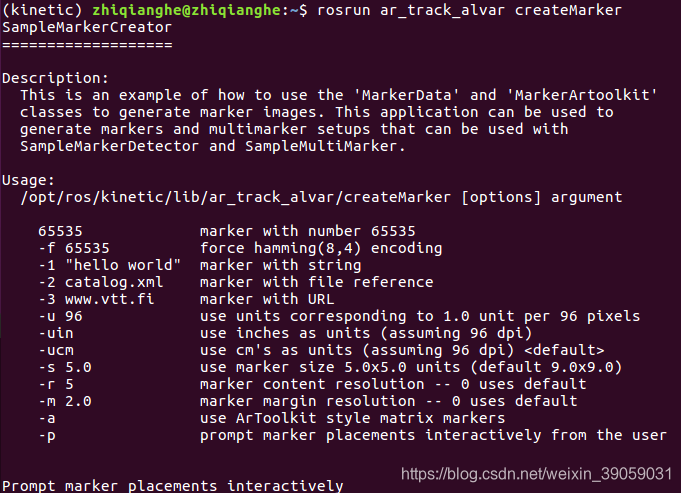 我们可以通过多种方式,像数字、文件、网址等等来创建二维码,还可以去定义我们二维码的大小什么的。接下来我们实现对它的识别:
我们可以通过多种方式,像数字、文件、网址等等来创建二维码,还可以去定义我们二维码的大小什么的。接下来我们实现对它的识别:
 上述命令分别是创建一个大小为5的数字0,大小为5的数字1,大小为5的数字2。 接下来我们去工作空间下看一下launch文件:
上述命令分别是创建一个大小为5的数字0,大小为5的数字1,大小为5的数字2。 接下来我们去工作空间下看一下launch文件:
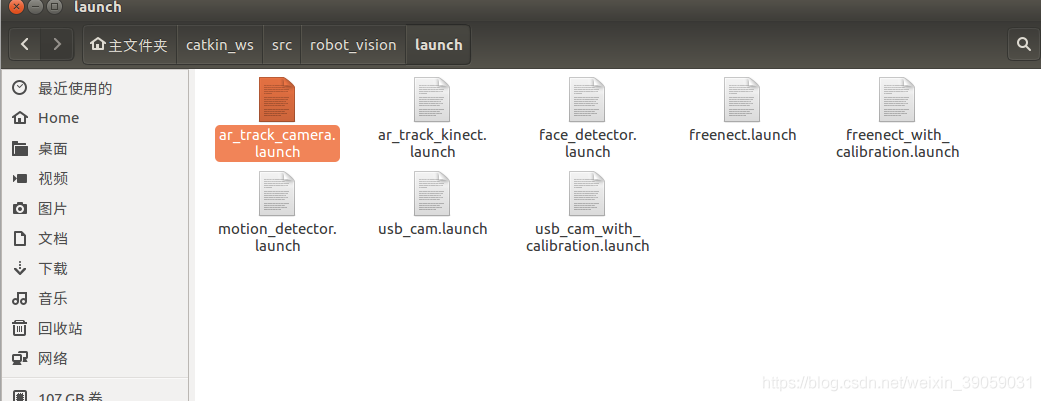
 核心部分是node节点,通过启动individualMarkersNoKinect节点去识别二维码。里面加一些参数,像什么二维码的尺寸等。
核心部分是node节点,通过启动individualMarkersNoKinect节点去识别二维码。里面加一些参数,像什么二维码的尺寸等。
roslaunch robot_vision usb_cam_with_calibration.launch roslaunch robot_vision ar_track_camera.launch
rostopic echo /ar_pose_marker查看二维码姿态
我的微信公众号名称:深度学习与先进智能决策 微信公众号ID:MultiAgenxt1024 公众号介绍:主要研究强化学习、计算机视觉、深度学习、机器学习等相关内容,分享学习过程中的学习笔记和心得!期待您的关注,欢迎一起学习交流进步!