上一篇文章我们强力推导了GAN的数学公式,它就是:
 在我们训练D 网络的时候,我们要让V 最大化,当我们训练G 网络的时候我们要让V最小化,就是这么简单。因此哪怕数学推导那篇五六千字的博客不想看,实做也可以做。 实做上比较大的一个问题是我们实际上不能获取到全部真实图像样本和全部拟合图像样本。因此上面这道公式在实做上是搞不成的。 我们采取的方法是抽样。也就是从P data(x)中抽出m mm个样本,写作{x 1,x 2,…,x m},再从P G(x)中抽出m 个样本,写作{ x1, x2,…, xm},然后我们认为这m mm个样本的分布和总体的分布就差不多了。那么上面的公式就变成下面这个样子:
在我们训练D 网络的时候,我们要让V 最大化,当我们训练G 网络的时候我们要让V最小化,就是这么简单。因此哪怕数学推导那篇五六千字的博客不想看,实做也可以做。 实做上比较大的一个问题是我们实际上不能获取到全部真实图像样本和全部拟合图像样本。因此上面这道公式在实做上是搞不成的。 我们采取的方法是抽样。也就是从P data(x)中抽出m mm个样本,写作{x 1,x 2,…,x m},再从P G(x)中抽出m 个样本,写作{ x1, x2,…, xm},然后我们认为这m mm个样本的分布和总体的分布就差不多了。那么上面的公式就变成下面这个样子:
 当然可能有人会说,这样不就存在着误差吗? 是的,但这个误差会随着样本的增多和样本分布的合理化而减小,因此我们在选样本的时候还是要注意样本的数量和分布的合理性。不要搞10张样本就拿来训练,起码是“万”级别的,且如果你想生成的是猫的图像,不要选几万张“白”猫,因为那样生成网络和判别网络均会认为猫就是白色的,没有别的颜色。 OK,分析完误差之后我们假定样本是十分给力的,那么我们就能根据面这道公式来做计算。 首先看到D DD网络,我们要做的是最大化上面这个 V~,先来看看logx长什么样。
当然可能有人会说,这样不就存在着误差吗? 是的,但这个误差会随着样本的增多和样本分布的合理化而减小,因此我们在选样本的时候还是要注意样本的数量和分布的合理性。不要搞10张样本就拿来训练,起码是“万”级别的,且如果你想生成的是猫的图像,不要选几万张“白”猫,因为那样生成网络和判别网络均会认为猫就是白色的,没有别的颜色。 OK,分析完误差之后我们假定样本是十分给力的,那么我们就能根据面这道公式来做计算。 首先看到D DD网络,我们要做的是最大化上面这个 V~,先来看看logx长什么样。
 可以看出它是一个单调递增的函数,因此要V~取得最大值,其实就是要
可以看出它是一个单调递增的函数,因此要V~取得最大值,其实就是要
![]() 分别取得最大值。也就是要D(x i)取得最大值,1−D( x~i)取得最大值。因此,我们只需要在输入真实样本的时候尽量让D 网络输出1,而输入拟合样本的时候让网络尽量输出0就搞定了。 这里有个非常神奇的地方,就是我们要求的这道式子跟二分类问题的交叉熵损失函数居然长的是一样的。我们先看看二分类问题的交叉熵损失函数长什么样:
分别取得最大值。也就是要D(x i)取得最大值,1−D( x~i)取得最大值。因此,我们只需要在输入真实样本的时候尽量让D 网络输出1,而输入拟合样本的时候让网络尽量输出0就搞定了。 这里有个非常神奇的地方,就是我们要求的这道式子跟二分类问题的交叉熵损失函数居然长的是一样的。我们先看看二分类问题的交叉熵损失函数长什么样:
 这里因为是二分问题,因此p(x i)在正样本中等于1,在负样本中等于0,这个时候上面的式子变成:
这里因为是二分问题,因此p(x i)在正样本中等于1,在负样本中等于0,这个时候上面的式子变成:
 这道式子忽略掉常数项刚刚好是V 取反。而我们本来求D 网络就是求V 取最大值的情况,一旦给V 取反,则变成求最小值,直接等于损失函数的目标!真是不要太方便! 那么具体流程是什么呢? 1.从P data ( x )中抽出m 个样本,写作{ x 1 , x 2 , … , x m },再从P G ( x ) 中抽出m 个样本(也就是让G网络生成m 个样本),写作{ x ~ 1 , x ~ 2 , … , x ~ m } 2.用二分问题的交叉熵损失函数作为损失函数,然后用样本对网络进行训练,完事,就是这么简单。 再来看看G网络,我们从前面已经知道G 网络的目标是最小化:
这道式子忽略掉常数项刚刚好是V 取反。而我们本来求D 网络就是求V 取最大值的情况,一旦给V 取反,则变成求最小值,直接等于损失函数的目标!真是不要太方便! 那么具体流程是什么呢? 1.从P data ( x )中抽出m 个样本,写作{ x 1 , x 2 , … , x m },再从P G ( x ) 中抽出m 个样本(也就是让G网络生成m 个样本),写作{ x ~ 1 , x ~ 2 , … , x ~ m } 2.用二分问题的交叉熵损失函数作为损失函数,然后用样本对网络进行训练,完事,就是这么简单。 再来看看G网络,我们从前面已经知道G 网络的目标是最小化:
 因为在训练G 网络的时候,D 网络是不变的,因此上面式子左边的一项是不变的,相当于一个常数。而对于最小化问题来说,常数是不影响结果的,因此我们其实是在最小化:
因为在训练G 网络的时候,D 网络是不变的,因此上面式子左边的一项是不变的,相当于一个常数。而对于最小化问题来说,常数是不影响结果的,因此我们其实是在最小化:
 按理说按照上面所述已经可以开始写代码了。但实际上还有个操作上的问题,这个问题出在log(1−x)这个函数上,它长这样:
按理说按照上面所述已经可以开始写代码了。但实际上还有个操作上的问题,这个问题出在log(1−x)这个函数上,它长这样:
 可以看到当x 接近1的时候该函数相当的陡峭,而在0附近它却不是很陡(其实对log(1−x)求下导就可以知道它的导数的绝对值是逐步增大的,也就是它渐渐变陡)。这有什么问题呢? 问题就在于一开始的时候因为G 网络的参数是接近随机的,基本上骗不过D 网络,因此D ( x ~ i ) D 这个东西在一开始的时候总会输出接近0的数。而从上面我们知道,如果越接近0,那么l o g ( 1 − x ) 这个损失函数就越平。而在训练后期,D ( x ~ i ) 会慢慢增加(最理想是0.5),这个时候log(1−x)损失函数却越变越陡。这跟我们需要的是完全相反的!我们希望的是一开始训练快速收缩到最优解附近,然后慢慢调整找到最优解,而它反过来。因此虽然理论上那么列式是完全合理的,但实际上用这么一个损失函数会使得训练比较崩溃,十分的反直觉。因此为了解决这个问题,GAN用的损失函数并不是log(1−x),而是−log(x):
可以看到当x 接近1的时候该函数相当的陡峭,而在0附近它却不是很陡(其实对log(1−x)求下导就可以知道它的导数的绝对值是逐步增大的,也就是它渐渐变陡)。这有什么问题呢? 问题就在于一开始的时候因为G 网络的参数是接近随机的,基本上骗不过D 网络,因此D ( x ~ i ) D 这个东西在一开始的时候总会输出接近0的数。而从上面我们知道,如果越接近0,那么l o g ( 1 − x ) 这个损失函数就越平。而在训练后期,D ( x ~ i ) 会慢慢增加(最理想是0.5),这个时候log(1−x)损失函数却越变越陡。这跟我们需要的是完全相反的!我们希望的是一开始训练快速收缩到最优解附近,然后慢慢调整找到最优解,而它反过来。因此虽然理论上那么列式是完全合理的,但实际上用这么一个损失函数会使得训练比较崩溃,十分的反直觉。因此为了解决这个问题,GAN用的损失函数并不是log(1−x),而是−log(x):
 这个损失函数就牛逼了,单调性和log(1−x)一样,且陡峭程度变化完全符合我们的要求。因此我们真正训练G 网络的时候用的是它。但这么改有个问题,就是我们本来G 网络训练的是一个J SS距离,现在训练的却不知道是个啥,只知道它大致等价于JS距离。不过这个问题好像也不是很要紧,总之我们训练的是这个式子:
这个损失函数就牛逼了,单调性和log(1−x)一样,且陡峭程度变化完全符合我们的要求。因此我们真正训练G 网络的时候用的是它。但这么改有个问题,就是我们本来G 网络训练的是一个J SS距离,现在训练的却不知道是个啥,只知道它大致等价于JS距离。不过这个问题好像也不是很要紧,总之我们训练的是这个式子:
 看到这个式子再联系上面的D 网络,聪明的你可能发现它长得和二分类问题的交叉熵损失函数输入正样本的情况又是一模一样的(除了个没多大所谓的常数项)。这在我们实际操作中简直不要太方便!具体流程是: 1.从z zz中抽出m 个样本,写作{ z ~ 1 , z ~ 2 , … , z ~ m } 2.用二分问题的交叉熵损失函数作为损失函数,然后用样本对网络进行训练,大功告成! 那么具体的训练过程大概总结下是这个样子的,先定住G 网络训练几次D 网络,再定住D 网络训练一次G 网络,循环往复就行了。为什么是几次和一次呢? 首先,因为我们希望D 网络这把尺子准一点,最好每次都找到全局最优解,这样能更好的指导G GG网络。 其次,我们希望G 网络每次不要更新太多,具体可见下图:
看到这个式子再联系上面的D 网络,聪明的你可能发现它长得和二分类问题的交叉熵损失函数输入正样本的情况又是一模一样的(除了个没多大所谓的常数项)。这在我们实际操作中简直不要太方便!具体流程是: 1.从z zz中抽出m 个样本,写作{ z ~ 1 , z ~ 2 , … , z ~ m } 2.用二分问题的交叉熵损失函数作为损失函数,然后用样本对网络进行训练,大功告成! 那么具体的训练过程大概总结下是这个样子的,先定住G 网络训练几次D 网络,再定住D 网络训练一次G 网络,循环往复就行了。为什么是几次和一次呢? 首先,因为我们希望D 网络这把尺子准一点,最好每次都找到全局最优解,这样能更好的指导G GG网络。 其次,我们希望G 网络每次不要更新太多,具体可见下图:
 如果更新太多,G 网络的形状可能会从左边变到右边,这样D 网络的最大值点会到处飘,比较难训练。 下面放上实现代码,非常简单。主要参考的《深度学习框架PyTorch:入门与实践》这本书的代码,本人把其他复杂的东西删掉了,就剩下最简单的实现部分,这样看起来清楚点。 model.py
如果更新太多,G 网络的形状可能会从左边变到右边,这样D 网络的最大值点会到处飘,比较难训练。 下面放上实现代码,非常简单。主要参考的《深度学习框架PyTorch:入门与实践》这本书的代码,本人把其他复杂的东西删掉了,就剩下最简单的实现部分,这样看起来清楚点。 model.py
# coding:utf-8
from torch import nn
class NetG(nn.Module):
"""
生成器定义
"""
def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器feature map数
self.main = nn.Sequential(
# 输入是一个nz维度的噪声,我们可以认为它是一个1*1*nz的feature map
nn.ConvTranspose2d(opt.nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 上一步的输出形状:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 上一步的输出形状: (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 上一步的输出形状: (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的输出形状:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh() # 输出范围 -1~1 故而采用Tanh
# 输出形状:3 x 96 x 96
)
def forward(self, input):
return self.main(input)
class NetD(nn.Module):
"""
判别器定义
"""
def __init__(self, opt):
super(NetD, self).__init__()
ndf = opt.ndf
self.main = nn.Sequential(
# 输入 3 x 96 x 96
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() # 输出一个数(概率)
)
def forward(self, input):
return self.main(input).view(-1)
# coding:utf-8
import os
import torch as t
import torchvision as tv
import tqdm
from model import NetG, NetD
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = 4 # 多进程加载数据所用的进程数
image_size = 96 # 图片尺寸
batch_size = 256 #一次训练样本数
max_epoch = 200 #最大训练次数
lr1 = 2e-4 # 生成器的学习率
lr2 = 2e-4 # 判别器的学习率
beta1 = 0.5 # Adam优化器的beta1参数
gpu = True # 是否使用GPU
nz = 100 # 噪声维度
ngf = 64 # 生成器feature map数
ndf = 64 # 判别器feature map数
save_path = 'imgs/' # 生成图片保存路径
d_every = 1 # 每1个batch训练一次判别器
g_every = 5 # 每5个batch训练一次生成器
save_every = 1 # 每1个epoch保存一次模型
#netd_path = 'checkpoints/netd.pth'
#netg_path = 'checkpoints/netg.pth'
netd_path = None
netg_path = None
opt = Config()
def train():
device=t.device('cuda') if opt.gpu else t.device('cpu')
# 读入数据格式转换
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size),#图像尺寸缩放
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))#先将数据归一化到(0,1),再用公式(x-mean)/std将每个元素分布到(-1,1)
])
dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms)
dataloader = t.utils.data.DataLoader(dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
# 网络初始化,如有预训练模型则读入
netg, netd = NetG(opt), NetD(opt)
map_location = lambda storage, loc: storage
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 定义优化器和损失函数
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss().to(device)
# 真图片label为1,假图片label为0
# noises为生成网络的输入
true_labels = t.ones(opt.batch_size).to(device)
fake_labels = t.zeros(opt.batch_size).to(device)
fix_noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)#产生正态分布的随机数,也就是G网络的z
noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.to(device)
if ii % opt.d_every == 0:
# 训练判别器
optimizer_d.zero_grad()#清空节点值
## 尽可能的把真图片判别为正确
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 尽可能把假图片判别为错误
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises).detach() # 根据噪声生成假图
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step()
if ii % opt.g_every == 0:
# 训练生成器
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output, true_labels)
error_g.backward()
optimizer_g.step()
if (epoch+1) % opt.save_every == 0:
# 保存模型、图片
fix_fake_imgs = netg(fix_noises)
tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True,range=(-1, 1))
t.save(netd.state_dict(), 'checkpoints/netd.pth')
t.save(netg.state_dict(), 'checkpoints/netg.pth')
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
if __name__ == '__main__':
train()
一开始训练得到的图如下的一坨:
 后面训练了一百多个轮次之后渐渐好了起来:
后面训练了一百多个轮次之后渐渐好了起来:

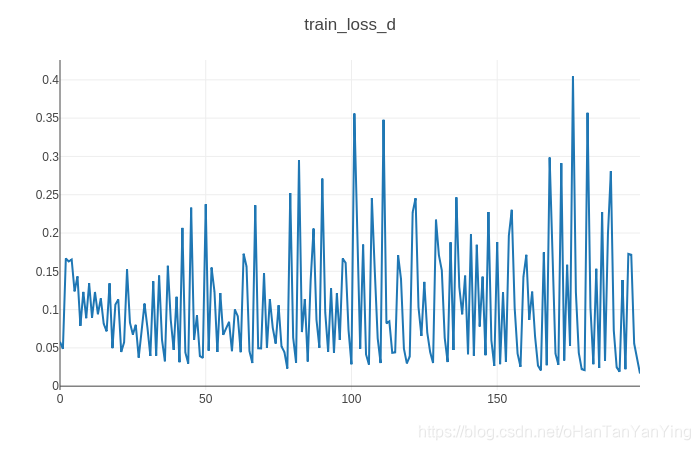
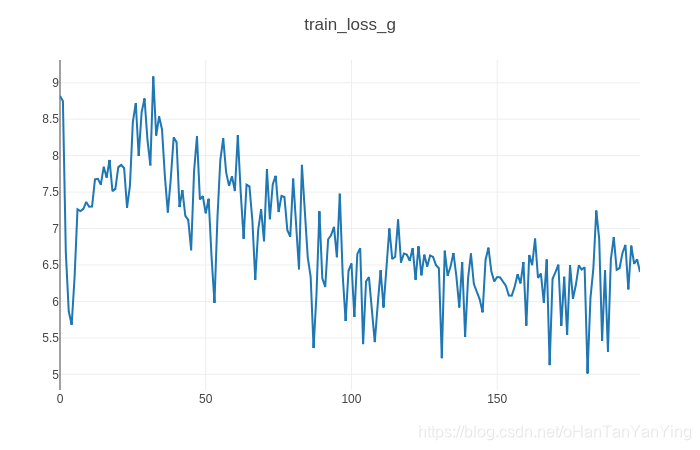 可以看到有些图片已经有模有样了,但有些还蛮崩坏的。这跟原生GAN的一些缺陷有关系,比如说D 网络容易过拟合,或者G 网络分布远远不足以覆盖目标子集,距离一直很大等等。这个在后面的改进版本逐步得到解决,会在以后研究到的时候跟大家分享。当然也可以直接去Bilibili看看李宏毅教授的视频,讲得非常给力!
可以看到有些图片已经有模有样了,但有些还蛮崩坏的。这跟原生GAN的一些缺陷有关系,比如说D 网络容易过拟合,或者G 网络分布远远不足以覆盖目标子集,距离一直很大等等。这个在后面的改进版本逐步得到解决,会在以后研究到的时候跟大家分享。当然也可以直接去Bilibili看看李宏毅教授的视频,讲得非常给力!
# coding:utf-8
import os
import torch as t
import torchvision as tv
import tqdm
from model import NetG, NetD
import visdom
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = 4 # 多进程加载数据所用的进程数
image_size = 96 # 图片尺寸
batch_size = 256 #一次训练样本数
max_epoch = 200 #最大训练次数
lr1 = 2e-4 # 生成器的学习率
lr2 = 2e-4 # 判别器的学习率
beta1 = 0.5 # Adam优化器的beta1参数
gpu = True # 是否使用GPU
nz = 100 # 噪声维度
ngf = 64 # 生成器feature map数
ndf = 64 # 判别器feature map数
save_path = 'imgs/' # 生成图片保存路径
d_every = 1 # 每1个batch训练一次判别器
g_every = 5 # 每5个batch训练一次生成器
save_every = 1 # 每1个epoch保存一次模型
#netd_path = 'checkpoints/netd.pth'
#netg_path = 'checkpoints/netg.pth'
netd_path = None
netg_path = None
opt = Config()
def train():
device=t.device('cuda') if opt.gpu else t.device('cpu')
# 读入数据格式转换
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size),#图像尺寸缩放
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))#先将数据归一化到(0,1),再用公式(x-mean)/std将每个元素分布到(-1,1)
])
dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms)
dataloader = t.utils.data.DataLoader(dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
# 网络初始化,如有预训练模型则读入
netg, netd = NetG(opt), NetD(opt)
map_location = lambda storage, loc: storage
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 定义优化器和损失函数
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss().to(device)
# 真图片label为1,假图片label为0
# noises为生成网络的输入
true_labels = t.ones(opt.batch_size).to(device)
fake_labels = t.zeros(opt.batch_size).to(device)
fix_noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)#产生正态分布的随机数,也就是G网络的z
noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
#可视化
vis = visdom.Visdom()
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.to(device)
if ii % opt.d_every == 0:
# 训练判别器
optimizer_d.zero_grad()#清空节点值
## 尽可能的把真图片判别为正确
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 尽可能把假图片判别为错误
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises).detach() # 根据噪声生成假图
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step()
if ii % opt.g_every == 0:
# 训练生成器
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output, true_labels)
error_g.backward()
optimizer_g.step()
if (epoch+1) % opt.save_every == 0:
# 保存模型、图片
fix_fake_imgs = netg(fix_noises)
tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True,range=(-1, 1))
vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake')
t.save(netd.state_dict(), 'checkpoints/netd.pth')
t.save(netg.state_dict(), 'checkpoints/netg.pth')
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
if __name__ == '__main__':
train()




