实战Omniglot数据集识别(手写数字MNIST升级版)
目录
- 实战Omniglot数据集识别(手写数字MNIST升级版)
-
- 经典方法
- 简单方法
-
- 最简单——无脑全连接
- 简单卷积网络
- 添加STN与inception
- 改变loss函数
- 加深网络
- 小样本学习
-
- 度量学习(metric learning)
- 数据增强(data augmentation)
- 元学习(meta learning)
- 语义的方法(semantic)
- 升级方法尝试
-
- 数据增强
- 原型网络
- 总结
最近模式识别老师布置了一个大作业:手写字符识别 这里用到的数据集是Omniglot,如下:
 这个数据集可谓是手写数字识别的爸爸呀,手写数字识别作为识别领域最简单的任务(大概吧),Omniglot相比它的难点就在于:Omniglot具有1623个类别,但每个类别只有20张图片。 今天正好周末,我们就来打(虐)发(待)一下时(电)间(脑)吧。
这个数据集可谓是手写数字识别的爸爸呀,手写数字识别作为识别领域最简单的任务(大概吧),Omniglot相比它的难点就在于:Omniglot具有1623个类别,但每个类别只有20张图片。 今天正好周末,我们就来打(虐)发(待)一下时(电)间(脑)吧。
经典方法
在做什么任务之前,我们都应该想想经典方法可不可以实现。 用于分类,我们可以使用SVM或者朴素贝叶斯分类等。 我尝试了SVM,速度真是惨不忍睹,之后我尝试了朴素贝叶斯分类法,准确率大概是0.13左右。
简单方法
最简单——无脑全连接
我们先从最简单的方法开始,直接把图片展成一个向量,然后送入全连接。 网络结构如下:
") 每一层均使用batchnorm,ReLU激活,并使用DropOut,概率为0.5。 这方法简单但准确率并不高,甚至和朴素贝叶斯分类方法准确率不相上下,训练过程如下:
每一层均使用batchnorm,ReLU激活,并使用DropOut,概率为0.5。 这方法简单但准确率并不高,甚至和朴素贝叶斯分类方法准确率不相上下,训练过程如下:
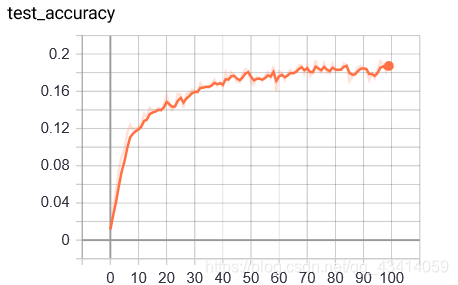 测试集准确率在0.18左右浮动,就连训练集准确率也没有突破0.2。 并不想浪费时间在调整这样的无脑网络上,所以我没有继续想办法优化,仅作为一个尝试,接下来开始卷积网络。
测试集准确率在0.18左右浮动,就连训练集准确率也没有突破0.2。 并不想浪费时间在调整这样的无脑网络上,所以我没有继续想办法优化,仅作为一个尝试,接下来开始卷积网络。
简单卷积网络
首先作为尝试,我先选择简单的卷积网络进行试验,设计网络结构如下:
(括号里表示in_channel,out_channel,kernal_size,stride)
Conv2d(1,64,3,2)
Conv2d(64,128,3,2)
Conv2d(128,256,3,1)
Conv2d(256,512,3,1)
View(1,512*3*3)
Full_connect(512*3*3,2048)
Full_connect(2048,1623)
层间均用ReLU激活,全连接中添加batchnorm层(由于通过尝试发现卷积层间添加batchnorm时会导致准确率降低,所以在这里不添加) 训练设置weight_decay为1e-4,初始学习率为1e-4,并以0.9指数每两轮衰减一次。训练结果如下:
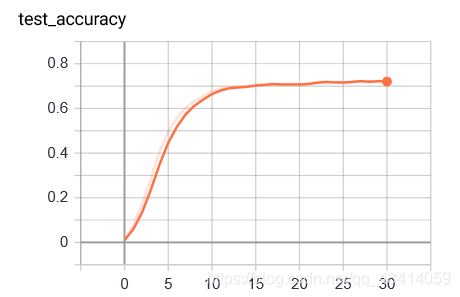 测试准确率收敛到了0.72,也算好了很多了。同时也可以看出这个数据集确实没有MNIST那么简单。 但在训练时可以发现,过拟合现象很严重,训练集预测准确率可以达到0.99。通过设置weight_dacay,添加DropOut,也没有很大的改善。看来只是按照普通的方法进行卷积还是有缺陷。
测试准确率收敛到了0.72,也算好了很多了。同时也可以看出这个数据集确实没有MNIST那么简单。 但在训练时可以发现,过拟合现象很严重,训练集预测准确率可以达到0.99。通过设置weight_dacay,添加DropOut,也没有很大的改善。看来只是按照普通的方法进行卷积还是有缺陷。
添加STN与inception
数据集中的图片每一个字符可能不是正的,这时候就需要网络具有旋转不变性。考虑到这一点,我在网络输入图片的时候添加了STN模块。同时我们识别时也需要从不同尺度看这张图片,然后通过特征融合得到不同尺度的特征,所以我添加了inception的思路。
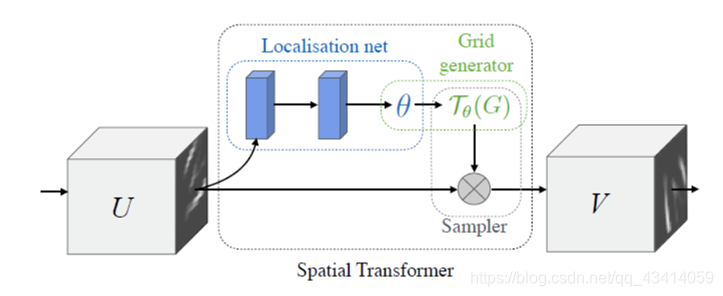 图为STN模块,具体细节可自行查找。 我使用具体网络结构如下:
图为STN模块,具体细节可自行查找。 我使用具体网络结构如下:
输入先通过STN模块调整方向,然后分为两路:
第一路:小卷积核
Conv2d(1, 16, kernel_size=3, padding=1)
Conv2d(16, 32, kernel_size=3, padding=1)
第二路:大卷积核
Conv2d(1, 16, kernel_size=7, padding=3)
Conv2d(16, 32, kernel_size=7, padding=3)
将两路的特征堆叠连接,送入如下卷积层
Conv2d(64, 128, kernel_size=3, padding=1)
Conv2d(128, 256, kernel_size=3, padding=1)
Conv2d(256, 512, kernel_size=3)
Conv2d(512, 1024, kernel_size=3)
Conv2d(1024, 2048, kernel_size=3)
这时特征已经缩减为一个向量,直接送入如下全连接层:
Full_connect(2048, 2048)
Full_connect(2048, 1623)
各层均用ReLU激活,全连接层用DropOut防止过拟合 训练设置weight_decay为1e-4,初始学习率为1e-4,并以0.9指数每两轮衰减一次。训练结果如下:
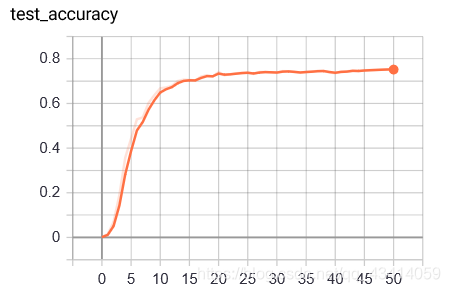 可见测试集准确率上升至0.75左右,上升不是很明显。
可见测试集准确率上升至0.75左右,上升不是很明显。
改变loss函数
目前目标识别领域常用的loss函数除了交叉熵损失,还有focal loss,该损失是交叉熵的拓展,往往比交叉熵有更好的效果。通常无用的易分反例样本会使得模型的整体学习方向跑偏,导致无效学习,所以该损失通过调整权重降低这些样本的影响,如下:
")
") 在γ \gammaγ等于0时,该损失退化为交叉熵。 使用该损失函数,同时使用之前最简单的卷积结构,训练设置weight_decay为1e-4,初始学习率为1e-4,并以0.9指数每两轮衰减一次,γ \gammaγ取2。训练结果如下:
在γ \gammaγ等于0时,该损失退化为交叉熵。 使用该损失函数,同时使用之前最简单的卷积结构,训练设置weight_decay为1e-4,初始学习率为1e-4,并以0.9指数每两轮衰减一次,γ \gammaγ取2。训练结果如下:
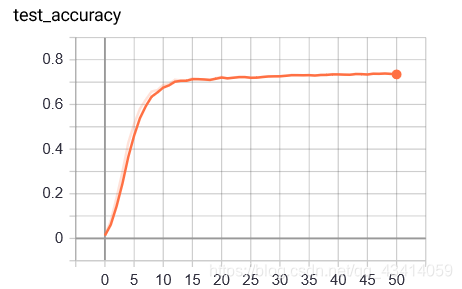 可见准确率也上升至了0.75左右。
可见准确率也上升至了0.75左右。
加深网络
看来这并不是简单的任务,我们通过更深的网络进行尝试: 直接使用未进行预训练的ResNet50的结构,将输出全连接的最后输出通道改为1,维度改为1623,训练结果如下:
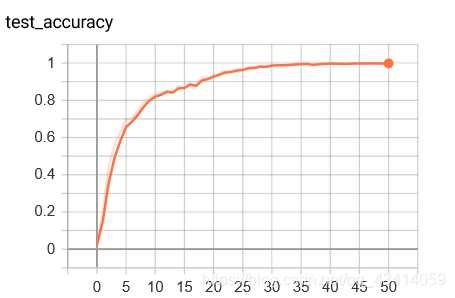 可见效果良好,可以达到0.99准确率,但是收敛慢,训练慢(毕竟太深了)。在1080ti上跑50个epoch用了半小时。
可见效果良好,可以达到0.99准确率,但是收敛慢,训练慢(毕竟太深了)。在1080ti上跑50个epoch用了半小时。
小样本学习
一顿乱试之后,我们该静下来想想为什么了,有没有方法能够花费较少的时间快速收敛且执行效率高呢? 其实,该任务属于小样本学习,即样本量非常少。目前,解决该难题的方法大致有如下四种: 1、度量学习(metric learning) 2、数据增强(data augmentation) 3、元学习(meta learning) 4、语义的方法(semantic) 我们一一来解释一下:
度量学习(metric learning)
即将待检测样本通过神经网络Embeding到另一个空间域内,在该空间中,每个样本为一个高维点,高维点之间距离越近代表这两个样本越可能是同一个类别。距离可以取各种距离,这也就是其名称“度量”之意。神经网络需要学习的也就是这样的一个映射,这里有一些有名的损失函数如triplet loss与reconstructive loss。
数据增强(data augmentation)
这个应该不用多说了吧,就是通过各种骚方法扩充数据集增加可识别率。
元学习(meta learning)
这应该也是目前的一个热点,包含面较为广泛,其根本用意就是我们常听到的“learning to learn”。他包含的方法有孪生网络、原型网络以及一些其他的方法。
语义的方法(semantic)
由于小样本学习困难的本质还是在于信息不够多,我们就想办法引入一些语义的信息来帮助分类。 下面,我们将运用数据增强以及原型网络来试一下下:
升级方法尝试
数据增强
由于对于字符,镜面翻转与随机旋转都不行,我采用了对每一个字符进行开闭运算的方法将数据集扩充了一倍,这里使用每类中35张图片作为训练集,5张图片作为测试集。使用上一节中最简单的卷积网络训练,使用focal loss,结果如下:
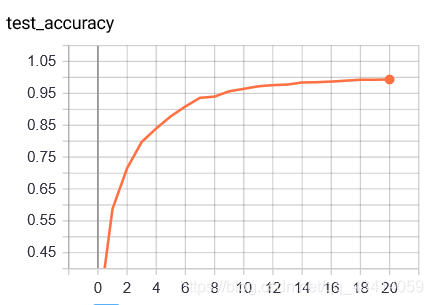 非常amazing啊,测试集准确率训练10个epoch时达到了0.9,18epoch时达到了0.99。收敛如此之快让我们领会到了数据的重要性。
非常amazing啊,测试集准确率训练10个epoch时达到了0.9,18epoch时达到了0.99。收敛如此之快让我们领会到了数据的重要性。
原型网络
原型网络为解决小样本学习的元学习方法中的一种,我这里运用了原型网络最初的论文:Prototypical Networks for Few-shot Learning中的方法,简要介绍一下:
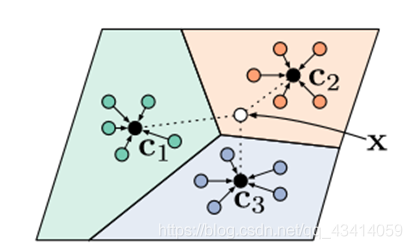 如图,神经网络学习一个空间Embeding,将数据映射到另一空间,然后求同一类别的均值,作为该类别的原型。如下:
如图,神经网络学习一个空间Embeding,将数据映射到另一空间,然后求同一类别的均值,作为该类别的原型。如下:
") 其中f即为该神经网络:
其中f即为该神经网络:
") 然后引入一个新的数据,判断其到每个原型的欧氏距离的softmax值,作为其属于该类别的概率:
然后引入一个新的数据,判断其到每个原型的欧氏距离的softmax值,作为其属于该类别的概率:
") 损失函数要做的就是最大化正确识别时的这个概率,如下:
损失函数要做的就是最大化正确识别时的这个概率,如下:
") 运用这样的方法,我使用的网络结构如下:
运用这样的方法,我使用的网络结构如下:
Conv2d(1,64,kernal_size=3,stride=2,padding=1),BatchNorm(),ReLU()
Conv2d(64,128,kernal_size=3,stride=2,padding=1),BatchNorm(),ReLU()
Conv2d(128,256,kernal_size=3,stride=2,padding=1),BatchNorm(),ReLU()
Conv2d(256,512,kernal_size=3,stride=2,padding=1),BatchNorm(),ReLU()
Flatten()然后进行训练,结果更加amazing: 一轮直接收敛: 每类10个做训练集,10个做测试集时,训练一轮后测试集准确率到达0.988,后面最高到达0.99. 每类2个做训练集,18个做测试集时,一轮训练后测试集准确率到达0.96,后面最高到达0.97。
总结
完成了老师布置的作业,终于能去快乐地玩耍了emm。