在开始之前,先送上本篇文章的彩蛋——我竟然在pybullet里放烟花!!! 声明:彩蛋与文章主要内容无关,纯粹图个开心。
")
一、前言
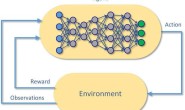
在进行机械臂抓取的时候,需要获得相机坐标系与世界坐标系的转换关系,也就是需要进行相机标定。而在pybullet中,这项工作少有资料,不过还是有三个思路可供选择: 1)在使用getCameraImage()函数的时候,已经指定了相机的一些参数,所以应该可以直接使用这些参数来计算,只需要找到公式即可; 2)在pybullet_data文件夹中,有提供标定板,所以理论上是可以进行标定操作的,感兴趣的小伙伴可以尝试做一下; 3)在仿真中,我们不仅可以获取相机中的坐标,还可以人为指定世界坐标系中的坐标,所以理论上这种模式是非常适合使用深度学习进行训练的:相机中的坐标作为输入,模型预测世界坐标系的坐标,编程指定的世界坐标系中的坐标作为标签。这样就可以构成完整的训练资料。 因为我的研究方向是深度强化学习,所以自然倾向于第三种方法,如果有小伙伴使用其他方法操作成功,也麻烦告知我一下,或者写个技术博客,一同学习。 下面我们就具体来实现这个深度学习训练模型。(假设抓取的是小的四方体) 下文会用到很多pybullet提供的函数,文中不会解释函数的用法,所有的用法都可以从pybullet的文档中查看,文档地址:pybullet quickstart guide
二、获取世界坐标系坐标数据
首先需要准备的是可供训练的数据:即相机坐标系坐标数据和世界坐标系坐标数据。世界坐标系的坐标在获取数据阶段,我们需要编程指定,是为了获取对应的相机坐标系的坐标数据。 指定世界坐标系坐标是非常简单的,我们只需要让四方体沿着x和y方向遍历移动,就可以获得很多的坐标数据。在这里,我们模拟抓取时候的场景,将四方体放在一个托盘中,如图所示:
") 代码就非常简单了。首先将托盘加载到环境中来,并且更改以下外表颜色。为什么要更改外表颜色呢?这个地方留个悬念,来不及解释了,到目的地再解释。然后定义好托盘的中心位置和到边缘的距离。
代码就非常简单了。首先将托盘加载到环境中来,并且更改以下外表颜色。为什么要更改外表颜色呢?这个地方留个悬念,来不及解释了,到目的地再解释。然后定义好托盘的中心位置和到边缘的距离。
TRAY_CENTER_X_POSITION=0.7 #为什么x中心在0.7呢,为什么不是0?因为抓取的时候机械臂在0
TRAY_CENTER_Y_POSITION=0.0
TRAY_CENTER_Z_POSITION=0.0
HALF_LENGTH=0.2
trayUid=p.loadURDF("tray/traybox.urdf", [TRAY_CENTER_X_POSITION, 0, 0])
p.changeVisualShape(trayUid,-1,rgbaColor=[0.1,0.1,0.1,1])
至于小伙伴会说,托盘中心位置好确定,那到边缘的距离怎么确定呢? 1)直接去看urdf的源码,看一下是怎样定义尺寸的。但是托盘的urdf中定义的是斜面上的尺寸,不是底面的尺寸,而我们的小四方体是放置在底面的,所以不是很直观; 2)又来一些骚操作,pybullet有一个很好用的函数addUserDebugLine(),这个函数可以添加一些线条,添加到你想要的位置。所以思路就是我们让这个线条竖直放置,然后让线条和托盘的边缘重合,看一下当前的坐标,就可以获得托盘底面的长度了。代码如下:
# The following code's function is to determine the edge of the box
# So now the box's size is 0.4x0.4 (m)
p.addUserDebugLine([0.7,0,0],[0.7,0,1])
p.addUserDebugLine([0.7+0.2,0,0],[0.7+0.2,0,1],[0,0,0])
p.addUserDebugLine([0.7,0.2,0],[0.7,0.2,1],[1,0,0])
如果对函数的参数困惑,函数的说明如下图:
") 修改参数的数值试几次,就可以确定托盘底面的尺寸大概是0.4×0.4(m),这也就是上面
修改参数的数值试几次,就可以确定托盘底面的尺寸大概是0.4×0.4(m),这也就是上面HALF_LENGTH=0.2这条代码的由来。 然后我们就让小四方体在托盘底部沿着x和y方向(也就是平面)遍历:
camera_coor_list,real_coor_list=[],[] #coordination in camera and real
for i in arange(TRAY_CENTER_X_POSITION-HALF_LENGTH,TRAY_CENTER_X_POSITION+HALF_LENGTH,0.01):
for j in arange(TRAY_CENTER_Y_POSITION-HALF_LENGTH,TRAY_CENTER_Y_POSITION+HALF_LENGTH,0.01):
cube_small_Uid=p.loadURDF("cube_small.urdf", [i, j ,0])
real_coor_list.append((i,j)) #add coordination to list
camera_coor_list.append(recognize_rectangle_center_point())
p.removeBody(cube_small_Uid)
这段代码有几个值得注意的地方: 1)小四方体每次移动的距离是0.01m; 2) camera_coor_list.append(recognize_rectangle_center_point())这句的作用是将相机坐标系的坐标添加到camera_coor_list中,后面我们再说; 3)p.removeBody(cube_small_Uid)作用是删除当前位置的小四方体,否则添加过的物体是不会消失的,这样造成的效果就是下面这样,不过也确实很有趣呢!
")
至此,世界坐标系的坐标数据就存到real_coor_list这个列表中了。
三、获取相机坐标系坐标数据
这是这部分要达到的目标:
")
") 相机坐标系坐标的获取稍微麻烦些,但是好在我们假设抓取的是规则的小四方体,对于识别四方体中心坐标还是很简单的。 首先呢,需要在pybullet中获取相机的图像,同时需要定义一些相机的参数:
相机坐标系坐标的获取稍微麻烦些,但是好在我们假设抓取的是规则的小四方体,对于识别四方体中心坐标还是很简单的。 首先呢,需要在pybullet中获取相机的图像,同时需要定义一些相机的参数:
# some camera parameters
width = 720
height = 720
fov = 60
aspect = width / height
near = 0.02
far = 1
CAMERA_X_POSITIOH=TRAY_CENTER_X_POSITION
CAMERA_Z_POSITION=0.1
CAMERA_Y_POSITION=0
view_matrix = p.computeViewMatrix([0.7, 0, 0.6], [0.7, 0, 0], [1, 0, 0])
projection_matrix = p.computeProjectionMatrixFOV(fov, aspect, near, far)
images = p.getCameraImage(width,
height,
view_matrix,
projection_matrix,
shadow=True,
lightDirection=[CAMERA_X_POSITIOH,CAMERA_Y_POSITION,CAMERA_Z_POSITION],
renderer=p.ER_BULLET_HARDWARE_OPENGL)
这些参数的设置和获取图像的写法,可以借鉴pybullet的example。pybullet良心的地方在于,不仅文档即为全面,example也即为全面,我们来看一下文档和example的面目,实则业界良心了:
")
") 获取到图像后,我们需要确定四方体中心的坐标,这就请出大名鼎鼎的OpenCV出场了。原理就是使用OpenCV的
获取到图像后,我们需要确定四方体中心的坐标,这就请出大名鼎鼎的OpenCV出场了。原理就是使用OpenCV的findContours()函数确定轮廓,然后确定质心的坐标,因为是质量分布均匀的四方体(正方体),可以认为质心的坐标就是形心的坐标。 稍微停一下,还记得前面留了一个疑问吗?为什么要将托盘的颜色调成近乎黑色呢?答案就在这里啊,因为调成近乎黑色后,OpenCV的轮廓识别更加稳定和正确,如果使用托盘本来的样子,识别稳定性是不能保证的,可以实验看一下。 代码如下:
img_for_opencv=images[2]
gray = cv2.cvtColor(img_for_opencv, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(blurred, 60, 255, cv2.THRESH_BINARY)[1]
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
for c in cnts:
# compute the center of the contour
if cv2.contourArea(c) > 10:
M = cv2.moments(c)
cX=int(M["m10"]/M["m00"])
cY=int(M["m01"]/M["m00"])
# draw the contour and center of the shape on the image
cv2.drawContours(img_for_opencv, [c], -1, (0, 255, 0), 2)
cv2.circle(img_for_opencv, (cX, cY), 7, (255, 255, 255), -1)
print('cx,cy=',cX,cY)
cv2.putText(img_for_opencv, "center", (cX - 20, cY - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# show the image
cv2.imshow("Image", img_for_opencv)
cv2.waitKey(1)
四、整合代码
上面说了挺多的代码,只是讲了每个部分该怎么实现,那么怎么整合起来让其正常的工作呢?下面我们来一步步展开。 首先看一下代码结构:
")
src文件夹是顶层文件夹,train-coor-network是主文件夹,utils文件夹是一些可复用的组件。train-coor-network文件夹下的get_coor.py文件是上面所讲内容的代码,utils文件夹下的recognize_rectangle.py文件是识别四方体中心位置的代码,因为可复用,将其抽象后放到utils文件夹。 get_coor.py文件内容如下:
# -*- coding: utf-8 -*-
#!/usr/bin/env python3
# get_coor.py
"""
Created on Mon Jan 11 14:48:13 2021
@author: dell
"""
import sys
sys.path.append('../')
import pybullet as p
import pybullet_data as pd
from numpy import arange
import pickle
from utils.recognize_rectangle import recognize_rectangle_center_point
camera_coor_pickle='camera_coor_saved_file_copy'
real_coor_pickle='real_coor_saved_file_copy'
TRAY_CENTER_X_POSITION=0.7
TRAY_CENTER_Y_POSITION=0.0
TRAY_CENTER_Z_POSITION=0.0
HALF_LENGTH=0.2
p.connect(p.GUI)
p.setAdditionalSearchPath(pd.getDataPath())
p.resetDebugVisualizerCamera(cameraDistance=1.7,cameraYaw=0,\
cameraPitch=-40,cameraTargetPosition=[0,-0.35,0.7])
p.setGravity(0,0,-9.8)
trayUid=p.loadURDF("tray/traybox.urdf", [TRAY_CENTER_X_POSITION, 0, 0])
p.changeVisualShape(trayUid,-1,rgbaColor=[0.1,0.1,0.1,1])
camera_coor_list,real_coor_list=[],[] #coordination in camera and real
for i in arange(TRAY_CENTER_X_POSITION-HALF_LENGTH,TRAY_CENTER_X_POSITION+HALF_LENGTH,0.01):
for j in arange(TRAY_CENTER_Y_POSITION-HALF_LENGTH,TRAY_CENTER_Y_POSITION+HALF_LENGTH,0.01):
cube_small_Uid=p.loadURDF("cube_small.urdf", [i, j ,0])
real_coor_list.append((i,j)) #add coordination to list
# =============================================================================
# p.changeVisualShape(cube_small_Uid,-1,rgbaColor=[random.uniform(0,1), \
# random.uniform(0,1), \
# random.uniform(0,1), \
# 1])
# =============================================================================
camera_coor_list.append(recognize_rectangle_center_point())
p.removeBody(cube_small_Uid)
camera_coor_file=open(camera_coor_pickle,'wb')
real_coor_file=open(real_coor_pickle,'wb')
pickle.dump(camera_coor_list,camera_coor_file)
camera_coor_file.close()
pickle.dump(real_coor_list,real_coor_file)
real_coor_file.close()
# =============================================================================
# The following code's function is to determine the edge of the box
# So now the box's size is 0.4x0.4 (m)
# p.addUserDebugLine([0.7,0,0],[0.7,0,1])
# p.addUserDebugLine([0.7+0.2,0,0],[0.7+0.2,0,1],[0,0,0])
# p.addUserDebugLine([0.7,0.2,0],[0.7,0.2,1],[1,0,0])
# =============================================================================
while True:
p.stepSimulation()
So easy 哈,主要内容上面都已经说过。camera_coor_list.append(recognize_rectangle_center_point())这句代码调用utils中的recognize_rectangle.py文件实现获取相机中的坐标。我们看一下这个文件怎么写: recognize_rectangle.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# recognize_rectangle.py
"""
Created on Wed Jan 20 21:18:19 2021
@author: dell
"""
import pybullet as p
import cv2
import imutils
TRAY_CENTER_X_POSITION=0.7
TRAY_CENTER_Y_POSITION=0.0
TRAY_CENTER_Z_POSITION=0.0
HALF_LENGTH=0.2
# some camera parameters
width = 720
height = 720
fov = 60
aspect = width / height
near = 0.02
far = 1
CAMERA_X_POSITIOH=TRAY_CENTER_X_POSITION
CAMERA_Z_POSITION=0.1
CAMERA_Y_POSITION=0
view_matrix = p.computeViewMatrix([0.7, 0, 0.6], [0.7, 0, 0], [1, 0, 0])
projection_matrix = p.computeProjectionMatrixFOV(fov, aspect, near, far)
def recognize_rectangle_center_point():
images = p.getCameraImage(width,
height,
view_matrix,
projection_matrix,
shadow=True,
lightDirection=[CAMERA_X_POSITIOH,CAMERA_Y_POSITION,CAMERA_Z_POSITION],
renderer=p.ER_BULLET_HARDWARE_OPENGL)
img_for_opencv=images[2]
gray = cv2.cvtColor(img_for_opencv, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(blurred, 60, 255, cv2.THRESH_BINARY)[1]
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
for c in cnts:
# compute the center of the contour
if cv2.contourArea(c) > 10:
M = cv2.moments(c)
cX=int(M["m10"]/M["m00"])
cY=int(M["m01"]/M["m00"])
# draw the contour and center of the shape on the image
cv2.drawContours(img_for_opencv, [c], -1, (0, 255, 0), 2)
cv2.circle(img_for_opencv, (cX, cY), 7, (255, 255, 255), -1)
print('cx,cy=',cX,cY)
cv2.putText(img_for_opencv, "center", (cX - 20, cY - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# show the image
cv2.imshow("Image", img_for_opencv)
cv2.waitKey(1)
return (cX,cY)
也是so easy。OpenCV识别四方体确定坐标的代码可以看一下OpenCV的教程。此外,get_coor.py文件中还有部分代码是关于将数据保存到pickle文件中,这个不算重点,但是必须要有。关于python对数据的处理、存储的更多的知识,大家可以参考《利用python进行数据分析》这本书,关于pickle、CSV 、MessagePack、HDF5、Feather、Parquet 等不用存储格式之间的区别,可以参考这篇文章The Best Format to Save Pandas Data
五、总结
好了,这就是本篇的全部内容,主要就是获取数据,深度学习训练的内容我们留到下节讲,写了这些markdown模式已经卡的不要不要的了,写不动了。下节就是训练和推断了。
")