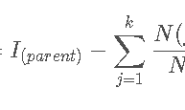一、什么是决策树
本章着重对算法部分进行讲解,原理部分不过多叙述,有兴趣的小伙伴可以自行查阅其他文献/文章 决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。 决策树学习通常包括3个步骤:特征选择、决策树的生成和剪枝。 决策树的生成:使用满足划分准则的特征不断的将数据集划分为纯度更高,不确定性更小的子集的过程。 特征选择:根据标准对特征进行选择,使得。整个决策子集的不确定性最小,常用的特征选择准则有:信息增益,信息增益比,基尼指数 剪枝:由于决策树算法很容易对训练集过拟合,从而导致泛化能力差,为了解决这个问题,我们需要对决策树进行剪枝,即类似于线性回归的正则化,来增加决策树的泛化能力。 (一)结构 我们先从决策树的结构开始说起
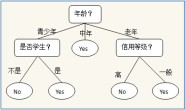
 从图可以看出,(通俗地讲)决策树是一个类似于流程图的树状结构:其中,每个黑色方块表示一个特征,每个方块之间的连接代表一个属性的输出,而每个树叶,即红色方块代表类或类分布。树的最顶层即最初的特征称为根结点。 以上图为例子,我们把是否出门这一决策过程简单归纳为图中的树状结构,要考虑的因素即为决策树当中的特征,出门和不出门对应两个分类即输出结果。 (二)决策的过程 从根节点开始,以某种量化标准去衡量每一分支的特征,并按照其值最终选择一个分支作为输出,直到到达叶子节点,将叶子节点对应的类别作为决策结果。 在决策树算法中,我们的关键一步就是每次选择一个特征,特征有多个,那么到底按照什么标准来选择哪一个特征。常用的特征选择准则有:信息增益,信息增益比,基尼指数。以信息增益为例,如果选择一个特征后,信息增益最大,那么我们就选取这个特征。 具体原理以及公式这里就不展开,大家可以查看下列文章 决策时算法介绍 决策树–信息增益,信息增益比,Geni指数的理解
从图可以看出,(通俗地讲)决策树是一个类似于流程图的树状结构:其中,每个黑色方块表示一个特征,每个方块之间的连接代表一个属性的输出,而每个树叶,即红色方块代表类或类分布。树的最顶层即最初的特征称为根结点。 以上图为例子,我们把是否出门这一决策过程简单归纳为图中的树状结构,要考虑的因素即为决策树当中的特征,出门和不出门对应两个分类即输出结果。 (二)决策的过程 从根节点开始,以某种量化标准去衡量每一分支的特征,并按照其值最终选择一个分支作为输出,直到到达叶子节点,将叶子节点对应的类别作为决策结果。 在决策树算法中,我们的关键一步就是每次选择一个特征,特征有多个,那么到底按照什么标准来选择哪一个特征。常用的特征选择准则有:信息增益,信息增益比,基尼指数。以信息增益为例,如果选择一个特征后,信息增益最大,那么我们就选取这个特征。 具体原理以及公式这里就不展开,大家可以查看下列文章 决策时算法介绍 决策树–信息增益,信息增益比,Geni指数的理解
二、代码
代码是基于Python机器学习的库:scikit-learn进行编写的。 scikit-learn的官方文档 安装 安装scikit-learn之前需要先安装numpy, SciPy和matplotlib,
1 pip install numpy scipy matplotlib
2 pip install -U scikit-learn
安装完成后就可以正式敲代码了,我们以下面一张图为例子。
 整理数据 我们把数据先输入到excel 保存为csv格式文件方便读取.
整理数据 我们把数据先输入到excel 保存为csv格式文件方便读取.

代码
1、读取文件 导入相关库
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing,tree
from sklearn.externals.six import StringIO
打开csv文件读取数据,并且打印头部
data = open(r'example.csv', 'r')
reader = csv.reader(data)
header = next(reader)
print(header)
print(type(header))
example.csv’是文件名,‘r’中的r表示“读”模式。 open()返回了一个文件对象data, reader(data)只传入了第一个参数,另外两个参数采用缺省值,即以excel风格读入。返回一个对象reader,当调用方法next()时,会返回一个string列表。 上面程序的效果是读取csv文件中的文本内容并打印出第一行,效果如下:
['RID', 'age', 'income', 'student', 'credit_rating', 'Class:if_buy']
<class 'list'>
2、预处理 sklearn决策树算法要求输入数据是类似下面这种格式的,因此我们还需要对数据进行转化,前面大部分代码都是在进行数据的预处理,这在机器学习甚至在深度学习中都是非常重要的一步。
 2.1 特征值预处理 先将读取到的数据分别存放到特征列表和标签列表当中,其中特征表的结构为[{},……{}],每个元素为一个特征字典
2.1 特征值预处理 先将读取到的数据分别存放到特征列表和标签列表当中,其中特征表的结构为[{},……{}],每个元素为一个特征字典
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1, len(row)-1):
rowDict[header[i]] = row[i]
featureList.append(rowDict)
print(featureList)
[{'age': 'youth', 'income': 'high', 'student': 'n', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'n', 'credit_rating': 'excellent'}, {'age': 'middle_age', 'income': 'high', 'student': 'n', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'n', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'y', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'y', 'credit_rating': 'excellent'}, {'age': 'middle_age', 'income': 'low', 'student': 'y', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'n', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'y', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'y', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'y', 'credit_rating': 'excellent'}, {'age': 'middle_age', 'income': 'medium', 'student': 'n', 'credit_rating': 'excellent'}, {'age': 'middle_age', 'income': 'high', 'student': 'y', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'n', 'credit_rating': 'excellent'}]
1
我们之所以要将特征数据保存成列表字典的结构,就是为了使用以下函数自动生成sklean所需要的数据结构,这里我们用到的类是DictVectorizer 。DictVectorizer的处理对象是符号化(非数字化)的但是具有一定结构的特征数据,如字典等,将符号转成数字0/1表示
1 vec = DictVectorizer()
2 dummyX = vec.fit_transform(featureList).toarray()
3 print(vec.get_feature_names())
4 print(str(dummyX))
输出结果
['age=middle_age', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=n', 'student=y']
[[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
2.2 标签值预处理 sklearn自带的preprocessing可以对标签进行处理,我们直接调用就行
1 lb = preprocessing.LabelBinarizer()
2 dummyY = lb.fit_transform(labelList)
效果
[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
决策树生成 数据处理完后我们就可以开始利用决策树学习,调用DecisionTreeClassifier()函数,
 可以看到,该函数默认的特征选择方法是基于基尼系数的,对于这个例子我们用信息熵。 其余参数的调节可以参考文档
可以看到,该函数默认的特征选择方法是基于基尼系数的,对于这个例子我们用信息熵。 其余参数的调节可以参考文档
1 clf = tree.DecisionTreeClassifier(criterion='entropy')
2 clf = clf.fit(dummyX, dummyY)
我们可以将模型保存成dot文件,详情看下图,
1 with open('result.dot', 'w') as file:
2 file = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=file)
 这种方式还不太直观,我们可以用Graphviz转化dot文件至pdf可视化决策树。 在命令行,注意是命令行,在文件目录下 输入以下代码 就可得到pdf格式的树状图
这种方式还不太直观,我们可以用Graphviz转化dot文件至pdf可视化决策树。 在命令行,注意是命令行,在文件目录下 输入以下代码 就可得到pdf格式的树状图
dot -T pdf result.dot -o output.pdf