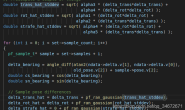
SLAM:同时定位和建图(Simultaneous Localization and Mapping)。 机器人从未知环境中的未知地点出发,在运动过程中通过重复观测到的地图特征(比如,墙角,柱子等)定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目的。 一般传感器:激光雷达,相机(单目,双目,RGBD,事件) SLAM框架: 传感器信息提取—前端视觉里程计—后端优化—建图 传感器信息提取—回环检测—后端优化(这两条线路之间形成一个闭环) 传感器信息提取:SLAM中传感器信息的提取和预处理,往往是多种传感器信息的融合。 前端视觉里程计(VO):通过估算相邻图像间的关系来推导相机的运动,以及局部地图的样子。 后端优化:接受不同时刻视觉里程计测量的相机位姿以及回环检测的信息,并对他们进行优化(往往是非线性优化),进而得到全局地图和轨迹。 回环检测:用于判断机器人是否到达先前预定的位置,解决位置估计随时间漂移的问题。 建图:根据估计的轨迹,建立相应要求的地图(栅格地图,拓扑地图,点云地图,网格地图)。 综上,机器人的定位与建图便完成了。 在地图构建的迭代步骤中,测得的距离和方向有可预知的一系列误差——通常由传感器有限的的精确度和外加的环境噪声所引起,那么附加到地图上的所有特征都将会含有相应的误差。随着时间的推移和运动的变化,定位和地图构建的误差累计增加,将会对地图本身和机器人的定位、导航等精度产生很大的扭曲。 SLAM定位: 机器人定位的方法可以分为非自主定位与自主定位两大类。 非自主定位是在定位的过程中机器人需要借助机器人本身以外的装置如:全球定位系统(GPS)、全局视觉系统等进行定位; 自主定位是机器人仅依靠机器人本身携带的传感器进行定位。由于在室内环境中,不能使用GPS,而安装其它的辅助定位系统比较麻烦。 因此机器人一般采用自主定位的方法。 按照初始位姿是否已知,可把机器人自主定位分为初始位姿已知的位姿跟踪(Pose tracking)和初始位姿未知的全局定位(Global localization)。 位姿跟踪是在已知机器人的初始位姿的条件下,在机器人的运动过程中通过将观测到的特征与地图中的特征进行匹配,求取它们之间的差别,进而更新机器人的位姿的机器人定位方法。位姿跟踪通常采用扩展卡尔曼滤波器(Extended Kalman Filter,EKF)来实现。该方法采用高斯分布来近似地表示机器人位姿的后验概率分布,其计算过程主要包括三步:首先是根据机器人的运模型预测机器人的位姿,然后将观测信息与地图进行匹配,最后根据预测后的机器人位姿以及匹配的特征计算机器人应该观测到的信息,并利用应该观测到的信息与实际观测到的信息之间的差距来更新机器人的位姿。 全局定位是在机器人的初始位姿不确定的条件下,利用局部的、不完全的观测信息估计机器人的当前位姿。能否解决最典型而又最富挑战性的“绑架恢复”问题在一定程度上反应了机器人全局定位方法的鲁棒性与可靠性。 实际情况是机器人在移动,周围物体(比如墙,各种路标等)是静止的。但是相对机器人而言,是墙在移动。我们通过特征点的匹配,得出墙移动后的位置(x2,y2,z2,alpha2,beta2,gama2),相机中两帧间的位置差(x2-x1,y2-y1,z2-z1,…)。于是,我们就可以得出机器人的位移,从而实现机器人的定位。 SLAM建图: 我们所谓的地图,即所有路标点的集合。一旦我们确定了路标点的位置,那就可以说我们完成了建图。 稠密建图: 单个图像中的像素,只能提供物体与相机成像平面的角度以及物体采集到的亮度,而无法提供物体的距离(Range)。而在稠密重建,我们需要知道每一个像素点(或大部分像素点)的距离,大致上有以下几种解决方案: 1.使用单目相机,利用移动相机之后进行三角化,测量像素的距离。 2.使用双目相机,利用左右目的视差计算像素的距离(多目原理相同)。 3.使用 RGB-D 相机直接获得像素距离。 使用 RGB-D 进行稠密重建往往是更常见的选择。而单目双目的好处,是在目前 RGB-D 还无法很好应用的室外、大场景场合中,仍能通过立体视觉估计深度信息。 点云地图(Point_Cloud Map) 1.在生成每帧点云时,去掉深度值太大或无效的点。 2.利用统计滤波器方法去除孤立点。 3.该滤波器统计每个点与它最近 N 个点的距离值的分布,去除距离均值过大的点。这样,我们保留了那些“粘在一起”的点,去掉了孤立的噪声点。 最后,利用体素滤波器(Voxel Filter)进行降采样。由于多个视角存在视野重叠,在重叠区域会存在大量的位置十分相近的点。这会无益地占用许多内存空间。体素滤波保证在某个一定大小的立方体(或称体素)内仅有一个点,相当于对三维空间进行了降采样,从而节省了很多存储空间。 建图和定位一样,过程中会产生误差,并且误差会逐渐积累。有许多技术能补偿这些误差,比如那些能再现某些特征过去的值的方法(也就是说,图像匹配法或者环路闭合检测法),或者对现有的地图进行处理——以融合该特征在不同时间的不同值。此外还有一些用于SLAM统计学的技术可起到作用,包括卡尔曼滤波、粒子滤波(实际上是一种蒙特卡罗方法)以及扫描匹配的数据范围。 本篇文章融合了好多博客,,,不能算原创,但是一个个引用太多了,,,所以,请允许我舔着脸投原创,,,