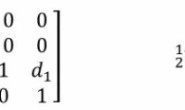
上期回顾:
RT-Thread智能车目标识别系统连载教程——手写体识别模型 (1)
RT-Thread智能车目标识别系统连载教程——训练卷积神经网络模型(2)
这一部分会介绍模型训练好之后要如何使用,也就是模型的推断过程 (Inference)
3.1 Python 导入模型并运行
我们先用 python 加载模型,看看用刚刚训练好的模型能不能进行很好的预测,下面的代码就是导入了刚刚训练完保存的 mnist.onnx 模型。
import onnxruntime as rt
sess = rt.InferenceSession("mnist.onnx")
为了运行模型,我们需要先得到模型的输出和输入层,输出层上一部分提到了,应当是 softmax:
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[0].name
接下来就是用测试集对模型进行预测了:
res = np.array(sess.run([output_name], {input_name: X_test}))
我们可以看看模型的测试集是个什么数字,然后看看模型计算得到了什么结果:
plt.imshow(X_test[0].reshape((28, 28)), cmap='gray')
print(res[0][0])
")
可以看到模型最后一层 softmax 输出了 10 个数字,其中第 7 个数字 0.99688894 (下标从 0 开始) 明显远大于其他的数,这说明这张图片里的数字是 7 的概率是 99% 以上,这张图片也确实就是 7。
这样看来,刚刚训练得到的模型还是可以正常预测的,当然,并不能保证有 100% 的正确率,如果大家感兴趣也可以改变一下上面代码里 X_test[0] 的序号,看看其他的测试集预测效果怎么样。
到这里为止,我们就不需要在 Anaconda 的 Jupyter Notebook 里写任何 Python 代码了,完整的代码可以在这里看到。查看完整项目请在外部浏览器打开以下链接:
https://github.com/wuhanstudio/onnx-backend/blob/master/examples/model/mnist-keras.ipynb
3.2 Google Protobuf
3.2.1 Protobuf 简介
")
之前我们提到,模型训练的目的就是为了得到变量的权值,只不过是纯数字罢了,但是我们也不能就这样把这些数字一个一个地写入文件,因为在要保存的模型文件里,不光要保存权值,也要告诉之后用这个模型的人,模型结构是怎么样的,所以需要合理地设计保存文件的格式。不同的机器学习框架都有自己的模型保存格式,例如 Keras 的模型格式是 h5,而 Tensorflow 和 onnx 的保存格式就是 protobuf。
那么到底什么是 protobuf? 为什么 protobuf 这么受欢迎?
其实 protobuf 使用起来非常简单方便,就是自己先定义一个数据保存格式,然后用 protoc 自动生成各个语言的解析代码,现在支持 C, C++, C#, Java, Javascript, Objective-C, PHP, Python, Ruby。
举个例子,我们创建这么个文件 amessage.proto
syntax = "proto3";
message AMessage {
int32 a=1;
int32 b=2;
}
那么我们就定义了一种二进制的数据存储格式,里面包含 2 个数字,其中 a = 1,代表 id 为 1 的数据是个 int32 类型,它的名字是 a,并不是代表 a 这个变量数值是 1,同样的道理,id 为 2 的数据是个 int32 类型,它的名字是 b。这里 id 是不能重复的。
所以使用 protobuf 需要先定义一个数据格式,然后自动生成 编码 和 解码 的代码,供不同语言使用,因为能自动生成代码,所以 protobuf 简单好用,非常受欢迎,建议大家使用 protov3。
3.2.2 RT-Thread 使用 Protobuf
在 RT-Thread 也是有 protobuf 的库的,可以帮助我们用 C 语言解析和保存 protobuf 文件,毕竟我们之后要解析的 onnx 模型就是 protobuf 协议保存的。
protobuf 软件包地址: http://packages.rt-thread.org/itemDetail.html?package=protobuf-c
虽然在文章的开头已经假定大家熟练使用 RT-Thread 软件包了,还是提醒一下 menuconfig 之前记得 pkgs –upgrade 一下才能看到最新的软件包。
可以看到这个软件包下有 2 个例程,一个直接创建一个 protobuf 格式的数据,然后直接解码;另一个例程则是先把数据编码保存到文件,再从二进制文件读取数据并解码。
")
关于 protobuf 这里就不做更多的介绍了,因为 onnx 的模型格式已经定义好了,我们只需要直接拿来用就可以了。
3.3 onnx 模型解析
现在我们已经有了 RT-Thread 支持的 protobuf 软件包,下一步就是弄清楚 onnx 模型的格式到底是怎么定义的了,关于 onnx 数据格式的完整定义可以在这里看到。
onnx 数据格式定义: https://github.com/onnx/onnx/blob/master/onnx/onnx.proto3
为了帮助我们更加直观的看到模型结构,这里推荐一个工具 protobuf editor:https://sourceforge.net/projects/protobufeditor/,可以很方便地解析 protobuf 文件。
软件下载下来后,按照下面的流程就可以解析之前我们生产的 mnist.onnx 文件了,图上面提到的 onnx.proto3 文件之前提到过可以在 这里:https://github.com/onnx/onnx/blob/master/onnx/onnx.proto3 下载。
")
然后我们就可以在弹出来的界面看到之前训练生成的模型里到底有哪些数据了。
")
可以看到里面有模型的版本信息、模型结构、模型权值、模型输入和模型输出,这也就是我们需要的信息了。
")
3.4 RT-Thread 导入模型并运行
在介绍了神经网络的基本理论,如何用 Python 训练 MNIST 手写体识别模型,以及 onnx 模型的 protobuf 文件格式后,终于到了最后一步,从 stm32 上加载这个模型并运行了。
")
RT-Thread 加载模型: https://github.com/wuhanstudio/onnx-backend
直接在上电脑上体验: https://github.com/wuhanstudio/onnx-parser
首先,我们需要在 env 里通过 menuconfig 选中软件包:
RT-Thread online packages → IoT - internet of things → onnx-backend
这里忍不住再提醒大家一下,记得先在 env 里:
pkgs --upgrade
")
可以看到这里一共有三个例程,下面就对这三个例程分别介绍,在看下面的源码解析之前也可以直接下载代码到板子上体验一下,不过记得打开文件系统,并且复制模型到 SD 卡里面,如果希望得到相同的输出,请使用 examples/mnist-sm.onnx 这个模型。
3.4.1 纯手动构建模型和参数
第一个例程是纯手动构建模型和参数,这样可以帮助我们理解模型结构和参数的位置,后面自动加载权值和模型结构就显得很自然简单了。
既然是纯手动构建模型,我们肯定得先知道模型长什么样子,这里再推荐另外一个 onnx 模型可视化根据 netron,下面的图就是 netron 根据我们之前训练生成的 mnist.onnx 模型生成的,非常漂亮:
")
")
")
")
可以看到我们的模型大致是这么个流程,中间重复的层我就没有写 2 次了,但是我们手动建模的时候自然是要加进去的。
Conv2D -> Relu -> Maxpool -> Dense ->Softmax")
那么,接下来就要手动构建上面这个模型了。
模型的权值可以在 mnist.h 这个头文件里看到,其实这里面的权值就是我从 Protocol Buffer Editor 里面复制过来的,大家训练好的模型权值不一定和我完全一样。
static const float W3[] = {-0.3233681, -0.4261553, -0.6519891, 0.79061985, -0.2210753, 0.037107922, 0.3984157, 0.22128074, 0.7975414, 0.2549885, 0.3076058, 0.62500215, -0.58958095, 0.20375429, -0.06477713, -1.566038, -0.37670124, -0.6443057};
static const float B3[] = {-0.829373, -0.14096421};
static const float W2[] = {0.0070440695, 0.23192555, 0.036849476, -0.14687373, -0.15593372, 0.0044246824, 0.27322513, -0.027562773, 0.23404223, -0.6354651, -0.55645454, -0.77057034, 0.15603222, 0.71015775, 0.23954256, 1.8201442, -0.018377468, 1.5745461, 1.7230825, -0.59662616, 1.3997843, 0.33511618, 0.56846994, 0.3797911, 0.035079807, -0.18287429, -0.032232445, 0.006910181, -0.0026898328, -0.0057844054, 0.29354542, 0.13796881, 0.3558416, 0.0022847173, 0.0025906325, -0.022641085};
static const float B2[] = {-0.11655525, -0.0036503011};
static const float W1[] = {0.15791991, -0.22649878, 0.021204736, 0.025593571, 0.008755621, -0.775102, -0.41594088, -0.12580238, -0.3963741, 0.33545518, -0.631953, -0.028754484, -0.50668705, -0.3574023, -3.7807872, -0.8261617, 0.102246165, 0.571127, -0.6256297, 0.06698781, 0.55969477, 0.25374785, -3.075965, -0.6959133, 0.2531965, 0.31739804, -0.8664238, 0.12750633, 0.83136076, 0.2666574, -2.5865922, -0.572031, 0.29743987, 0.16238026, -0.99154145, 0.077973805, 0.8913329, 0.16854058, -2.5247803, -0.5639109, 0.41671264, -0.10801031, -1.0229865, 0.2062031, 0.39889312, -0.16026731, -1.9185526, -0.48375717, 0.057339806, -1.2573057, -0.23117211, 1.051854, -0.7981992, -1.6263007, -0.26003376, -0.07649365, -0.4646075, 0.755821, 0.13187818, 0.24743222, -1.5276812, 0.1636555, -0.075465426, -0.058517877, -0.33852127, 1.3052516, 0.14443535, 0.44080895, -0.31031442, 0.15416017, 0.0053661224, -0.03175326, -0.15991405, 0.66121936, 0.0832211, 0.2651985, -0.038445678, 0.18054117, -0.0073251156, 0.054193687, -0.014296916, 0.30657783, 0.006181963, 0.22319937, 0.030315898, 0.12695274, -0.028179673, 0.11189027, 0.035358384, 0.046855893, -0.026528472, 0.26450494, 0.069981076, 0.107152134, -0.030371506, 0.09524366, 0.24802336, -0.36496836, -0.102762334, 0.49609017, 0.04002767, 0.020934932, -0.054773595, 0.05412083, -0.071876526, -1.5381132, -0.2356421, 1.5890793, -0.023087852, -0.24933836, 0.018771818, 0.08040064, 0.051946845, 0.6141782, 0.15780787, 0.12887044, -0.8691056, 1.3761537, 0.43058, 0.13476849, -0.14973496, 0.4542634, 0.13077497, 0.23117822, 0.003657386, 0.42742714, 0.23396699, 0.09209521, -0.060258932, 0.4642852, 0.10395402, 0.25047097, -0.05326261, 0.21466804, 0.11694269, 0.22402634, 0.12639907, 0.23495848, 0.12770525, 0.3324459, 0.0140223345, 0.106348366, 0.10877733, 0.30522102, 0.31412345, -0.07164018, 0.13483422, 0.45414954, 0.054698735, 0.07451815, 0.097312905, 0.27480683, 0.4866108, -0.43636885, -0.13586079, 0.5724732, 0.13595985, -0.0074526076, 0.11859829, 0.24481037, -0.37537888, -0.46877658, -0.5648533, 0.86578417, 0.3407381, -0.17214134, 0.040683553, 0.3630519, 0.089548275, -0.4989473, 0.47688767, 0.021731026, 0.2856471, 0.6174715, 0.7059148, -0.30635756, -0.5705427, -0.20692639, 0.041900065, 0.23040071, -0.1790487, -0.023751246, 0.14114629, 0.02345284, -0.64177734, -0.069909826, -0.08587972, 0.16460821, -0.53466517, -0.10163383, -0.13119817, 0.14908728, -0.63503706, -0.098961875, -0.23248474, 0.15406314, -0.48586813, -0.1904713, -0.20466608, 0.10629631, -0.5291871, -0.17358926, -0.36273107, 0.12225631, -0.38659447, -0.24787207, -0.25225234, 0.102635615, -0.14507034, -0.10110793, 0.043757595, -0.17158166, -0.031343404, -0.30139172, -0.09401665, 0.06986169, -0.54915506, 0.66843456, 0.14574362, -0.737502, 0.7700305, -0.4125441, 0.10115133, 0.05281194, 0.25467375, 0.22757779, -0.030224197, -0.0832025, -0.66385627, 0.51225215, -0.121023245, -0.3340579, -0.07505331, -0.09820366, -0.016041134, -0.03187605, -0.43589246, 0.094394326, -0.04983066, -0.0777906, -0.12822862, -0.089667186, -0.07014707, -0.010794195, -0.29095307, -0.01319235, -0.039757702, -0.023403417, -0.15530063, -0.052093383, -0.1477549, -0.07557954, -0.2686017, -0.035220042, -0.095615104, -0.015471024, -0.03906604, 0.024237331, -0.19604297, -0.19998372, -0.20302829, -0.04267139, -0.18774728, -0.045169186, -0.010131819, 0.14829905, -0.117015064, -0.4180649, -0.20680964, -0.024034742, -0.15787442, -0.055698488, -0.09037726, 0.40253848, -0.35745984, -0.786149, -0.0799551, 0.16205557, -0.14461482, -0.2749642, 0.2683253, 0.6881363, -0.064145364, 0.11361358, 0.59981894, 1.2947721, -1.2500908, 0.6082035, 0.12344158, 0.15808935, -0.17505693, 0.03425684, 0.39107767, 0.23190938, -0.7568858, 0.20042256, 0.079169095, 0.014275463, -0.12135842, 0.008516737, 0.26897284, 0.05706199, -0.52615446, 0.12489152, 0.08065737, -0.038548164, -0.08894516, 7.250979E-4, 0.28635752, -0.010820533, -0.39301336, 0.11144395, 0.06563818, -0.033744805, -0.07450528, -0.027328406, 0.3002447, 0.0029921278, -0.47954947, -0.04527057, -0.010289918, 0.039380465, -0.09236952, -0.1924659, 0.15401903, 0.21237805, -0.38984418, -0.37384143, -0.20648403, 0.29201767, -0.1299253, -0.36048025, -0.5544466, 0.45723814, -0.35266167, -0.94797707, -1.2481197, 0.88701195, 0.33620682, 0.0035414647, -0.22769359, 1.4563162, 0.54950374, 0.38396382, -0.41196275, 0.3758704, 0.17687413, 0.038129736, 0.16358295, 0.70515764, 0.055063568, 0.6445265, -0.2072113, 0.14618243, 0.10311305, 0.1971523, 0.174206, 0.36578146, -0.09782787, 0.5229244, -0.18459272, -0.0013945608, 0.08863555, 0.24184574, 0.15541393, 0.1722381, -0.10531331, 0.38215113, -0.30659106, -0.16298945, 0.11549875, 0.30750987, 0.1586183, -0.017728966, -0.050216004, 0.26232007, -1.2994286, -0.22700997, 0.108534105, 0.7447398, -0.39803517, 0.016863048, 0.10067235, -0.16355589, -0.64953077, -0.5674107, 0.017935256, 0.98968256, -1.395801, 0.44127485, 0.16644385, -0.19195901};
static const float B1[] = {1.2019119, -1.1770505, 2.1698284, -1.9615222};
static const float W[] = {0.55808353, 0.78707385, -0.040990848, -0.122510895, -0.41261443, -0.036044, 0.1691557, -0.14711425, -0.016407091, -0.28058195, 0.018765535, 0.062936015, 0.49562064, 0.33931744, -0.47547337, -0.1405672, -0.88271654, 0.18359914, 0.020887045, -0.13782434, -0.052250575, 0.67922074, -0.28022966, -0.31278887, 0.44416663, -0.26106882, -0.32219923, 1.0321393, -0.1444394, 0.5221766, 0.057590708, -0.96547794, -0.3051688, 0.16859075, -0.5320585, 0.42684716, -0.5434046, 0.014693736, 0.26795483, 0.15921915};
static const float B[] = {0.041442648, 1.461427, 0.07154641, -1.2774754, 0.80927604, -1.6933
接下来就是利用这些权值进行计算了,也就是把这些权值带入到理论部分介绍的各个运算里面,其中各个算子都可以在源代码的目录下看到,一个算子对应一个 c 文件:
conv2d.c maxpool.c softmax.c transpose.c
matmul.c add.c dense.c relu.c
这些算子的代码如果对应理论部分的公式,就很好理解了,这里就不再重复介绍每个算子对应的含义了,在 mnist.c 里也可以看到,其实就只是输入图像,经过各个算子的运算,加上一些内存的释放操作,最后就得到了 softmax 的输出,如果我把内存部分的操作隐藏掉:
// 1. Conv2D
float* W3_t = transpose(W3, shapeW3, dimW3, permW3_t);
conv2D(img[img_index], 28, 28, 1, W3, 2, 3, 3, 1, 1, 1, 1, B3, conv1, 28, 28);
// 2. Relu
relu(conv1, 28*28*2, relu1);
// 3. Maxpool
maxpool(relu1, 28, 28, 2, 2, 2, 0, 0, 2, 2, 14, 14, maxpool1);
// 4. Conv2D
float* W2_t = transpose(W2, shapeW2, dimW2, perm_t);
conv2D(maxpool1, 14, 14, 2, W2_t, 2, 3, 3, 1, 1, 1, 1, B2, conv2, 14, 14);
// 5. Relu
relu(conv2, 14*14*2, relu2);
// 6. Maxpool
maxpool(relu2, 14, 14, 2, 2, 2, 0, 0, 2, 2, 7, 7, maxpool2);
// Flatten NOT REQUIRED
// 7. Dense
float* W1_t = transpose(W1, shapeW1, dimW1, permW1_t);
dense(maxpool2, W1_t, 98, 4, B1, dense1);
// 8. Dense
float* W_t = transpose(W, shapeW, dimW, permW_t);
dense(dense1, W_t, 4, 10, B, dense2);
// 9. Softmax
softmax(dense2, 10, output);
可以看到,这些操作和前面图片里的模型是一一对应的,所以理解了理论部分模型为什么这么建立之后,再看代码就有一种恍然大悟的感觉,只不过相比 Python 而言, C 需要手动把权值和输入保存的数组里,并合理地管理内存的分配和释放。
如果我们把 mnist.c 编译上传到板子里,就可以看到成功地输出了预测结果:
msh />onnx_mnist 1
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@ @@@@@@@@ @@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@ @@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@ @@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@ @@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@ @@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@ @@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@ @@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Predictions:
0.007383 0.000000 0.057510 0.570970 0.000000 0.105505 0.000000 0.000039 0.257576 0.001016
The number is 3
由于这个模型是完全手动构建的,所以内存消耗非常少,大约在 16KB 左右,下面的例子由于需要从文件系统加载模型,所以内存消耗会增大许多。
")
3.4.2 手动构建模型自动加载参数
之前我们是手动构建模型,并且从 Protocol Buffer Editor 里手动复制权值到 mnist.h 里面,这样非常辛苦,所以这个例子就是会根据当前计算的模型的名称,自动加载权值。
比如我们在 Protocol Buffer Editor 软件里可以看到:
")
如果我们想计算 “dense_5” 这一层模型,那么我们需要权值 W1,接下来就会根据 “W1” 这个名字取寻找对应的权值:
")
所以这个例程只是多了自动寻找权值这个功能,因此我们传入的参数只需要是模型各层的名字就可以了,如果去掉内存释放相关的代码,每一层的计算还是非常清晰的。
// 2. Conv2D
float* conv1 = conv2D_layer(model->graph, img[MNIST_TEST_IMAGE], shapeInput, shapeOutput, "conv2d_5");
// 3. Relu
float* relu1 = relu_layer(model->graph, conv1, shapeInput, shapeOutput, "Relu1");
// 4. Maxpool
float* maxpool1 = maxpool_layer(model->graph, relu1, shapeInput, shapeOutput, "max_pooling2d_5");
// 5. Conv2D
float* conv2 = conv2D_layer(model->graph, maxpool1, shapeInput, shapeOutput, "conv2d_6");
// 6. Relu
float* relu2 = relu_layer(model->graph, conv2, shapeInput, shapeOutput, "Relu");
// 7. Maxpool
float* maxpool2 = maxpool_layer(model->graph, relu2, shapeInput, shapeOutput, "max_pooling2d_6");
// 8. Transpose
// 9. Flatten
// 10. Dense
float* matmul1 = matmul_layer(model->graph, maxpool2, shapeInput, shapeOutput, "dense_5");
// 11. Add
float* dense1 = add_layer(model->graph, matmul1, shapeInput, shapeOutput, "Add1");
// 12. Dense
float* matmul2 = matmul_layer(model->graph, dense1, shapeInput, shapeOutput, "dense_6");
// 13. Add
float* dense2 = add_layer(model->graph, matmul2, shapeInput, shapeOutput, "Add");
// 14. Softmax
float* output = softmax_layer(model->graph, dense2, shapeInput, shapeOutput, "Softmax");")
3.4.3 自动构建模型并加载参数
这三个例程越往下是越简单的,可以看到最后一个例程几乎就这两行代码了,加载模型,然后运行模型
只需要指定模型的输入就可以了,毕竟后面模型各层的输入输出是完全可以自动计算出来的。
// 加载模型
Onnx__ModelProto* model = onnx_load_model(ONNX_MODEL_NAME);
// 计算模型
float* output = onnx_model_run(model, input, shapeInput);
这个例子使用 valgrind 测试发现大约需要 64KB 内存,所以大家记得检查一下自己的开发板内存够不够。
")
论文地址:
https://arxiv.org/abs/1801.06601
3.5 参考文献
- 完整 Jupyter Notebook 源码
https://github.com/wuhanstudio/onnx-backend/blob/master/examples/model/mnist-keras.ipynb
- protobuf editor 解析工具
https://sourceforge.net/projects/protobufeditor/
- onnx 模型可视化
https://github.com/lutzroeder/Netron
- NWHC 还是 NCWH
https://arxiv.org/abs/1801.06601
- RT-Thread Protobuf 软件包
https://github.com/wuhanstudio/protobuf-c
- RT-Thread Protobuf 软件包
https://github.com/wuhanstudio/rt-onnx-parser
- RT-Thread Protobuf 软件包
https://github.com/wuhanstudio/onnx-backend