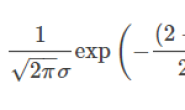前面两篇文章里首先介绍了贝叶斯滤波的理论框架,之后对机器人模型做了线性高斯假设,推出了卡尔曼滤波的迭代方程组。在这篇文章中,就将进一步介绍当机器人模型为非线性时该如何使用贝叶斯滤波。我们将介绍扩展卡尔曼滤波器以及无迹卡尔曼滤波器的由来。
《贝叶斯滤波与平滑》,作者:希莫·萨日伽,译者:程建华等。
英文原版:《Bayesian Filtering and Smoothing》
为了简便起见,下文中用英文缩写来代表各种滤波器。
贝叶斯滤波:Bayes Filter:BF
卡尔曼滤波:Kalman Filter:KF
扩展卡尔曼:Extend Kalman Filter:EKF
无迹卡尔曼:Unscent Kalman Filter:UKF
4 从BF到EKF
这一部分阐述的是在非线性模型下,如何用BF来滤波。
我们还是先回到老问题,要用BF滤波必须知道三个概率分布:
- 机器人动态模型的概率分布p(xk∣xk−1);
- 观测模型的概率分布p(yk∣xk);
- 0时刻机器人状态的先验分布p(x0)。
之前解释过了,高斯白噪声是很常用的,所以我们依然可以假设0时刻的机器人状态服从高斯分布。但是,在非线性模型的情况下怎么去求解机器人动态模型或是观测模型的概率分布呢?
4.1 非线性模型的定义
先验分布:
——从贝叶斯滤波到卡尔曼(下)")
动态模型:f(⋅) 是非线性系统函数,qk是系统噪声。
——从贝叶斯滤波到卡尔曼(下)")
观测模型:h(⋅)是非线性观测函数,rk是观测噪声。
——从贝叶斯滤波到卡尔曼(下)")
4.2 概率分布的高斯逼近
思考一个问题,我们假设有一随机变量x服从高斯分布,然而通过一个非线性函数g(⋅)后,x变换为了y,此时如何去估计随机变量y的概率分布呢?即:
——从贝叶斯滤波到卡尔曼(下)")
首先,明确一点,此时随机变量y的分布通常已经不再是高斯分布了。虽然它的分布可能是任意的,但是我们仍然可以用高斯分布去近似它,近似的手段有很多,泰勒展开是一种,无迹变换也是一种。本小节中主要介绍如何通过泰勒展开的方法,去实现对随机变量y分布的高斯逼近。
令x=m+δx,m是随机变量x的均值。假设非线性函数g(⋅)可微,那么根据泰勒级数展开公式,有:
——从贝叶斯滤波到卡尔曼(下)")
我们可以只取展开式的前两项来作为原函数g(⋅)的近似,此时:
——从贝叶斯滤波到卡尔曼(下)")
我们假设仍然用高斯分布去逼近随机变量y的分布,因此要想知道它的分布,我们还需要计算出y的均值向量以及协方差矩阵:
——从贝叶斯滤波到卡尔曼(下)")
所以用一阶泰勒展开近似非线性函数,再用高斯分布去逼近随机变量y的概率分布,得到的结果如下:
——从贝叶斯滤波到卡尔曼(下)")
至此,我们掌握了当y=g(x)时,如何推导随机变量y的概率分布。但是,4.1小节中的非线性模型在此基础上还添加了一个白噪声,也就是y=g(x)+q。这要怎么处理呢?
其实也很简单,此时的随机变量y服从下面分布:
——从贝叶斯滤波到卡尔曼(下)")
另外,在KF的推导过程中,我们曾用到过p(xk,xk−1∣y1:k−1)的大小,在EKF的推导中我们也仍然需要用到。求解这个概率分布,实际上对应就是求解这里的p(x,y)。
令 ![]() ,则按照上文中一样的推导方式,用高斯分布近似它,可以计算得到:
,则按照上文中一样的推导方式,用高斯分布近似它,可以计算得到:
——从贝叶斯滤波到卡尔曼(下)")
在这里介绍的只是利用泰勒级数一阶展开来近似原本的非线性函数,这主要是为了避免计算量过大。如果有更高的性能要求时,也可以保留二阶或者更高阶的项,去近似原函数。
4.3 EKF的导出
事实上,除了p(xk∣xk−1)与p(yk∣xk)的不同以外,EKF的推导与KF的推导是完全类似的。
参考KF的推导过程,我们可以发现推导过程中最主要的步骤是估计出p(xk,xk−1∣y1:k−1)以及p(xk,yk∣y1:k−1)这两个分布的大小,知道这两个分布以后基本上就能依据多元高斯分布的性质直接写出BF的预测和更新的迭代方程了。因此,这里只介绍如何用4.2小节的方法去估计出这两个分布,而后推导预测和更新的迭代方程就不再啰嗦了,完全可以由读者自行来写出。
因为:
——从贝叶斯滤波到卡尔曼(下)")
且k时刻状态的先验分布为:
——从贝叶斯滤波到卡尔曼(下)")
k时刻状态的预测分布为:
——从贝叶斯滤波到卡尔曼(下)")
所以:
——从贝叶斯滤波到卡尔曼(下)")
4.4 关于EKF的小结
相比于其他的非线性滤波方法,EKF的优点是非常的简单,因此在工程应用中非常常见。但是它的缺点也不少,首先,EKF是在局部(上一时刻的状态均值处)对模型进行了线性化,并且只取了低阶的导数项去近似,所以在强非线性条件下,EKF性能不够好。其次,我们假设了随机变量是服从高斯分布的,因此在噪声非高斯情况下EKF也不能适用。最后,EKF还要求动态模型和量测模型可微,也限制了其适用范围。
5 从BF到UKF
待施工
6 参数估计Vs状态估计 & 贝叶斯学习Vs贝叶斯滤波
待施工