@[toc]
一、词袋模型的引出
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词 是否出现.也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数,不过,在构造文档向量的过程中可以看到,词袋并没有表达单词在原来句子中出现的次序。但这个缺点却恰恰是视觉特征点所需的。因为视角变换的原因,同一地点,两次观测的特征点的顺序很可能不同,而词袋模型的这种无序性恰好解决了这一点。
二、原理
图像中的==特征==就好像文档中的==单词==。这些特征的集合也就够成了我们的视觉词袋。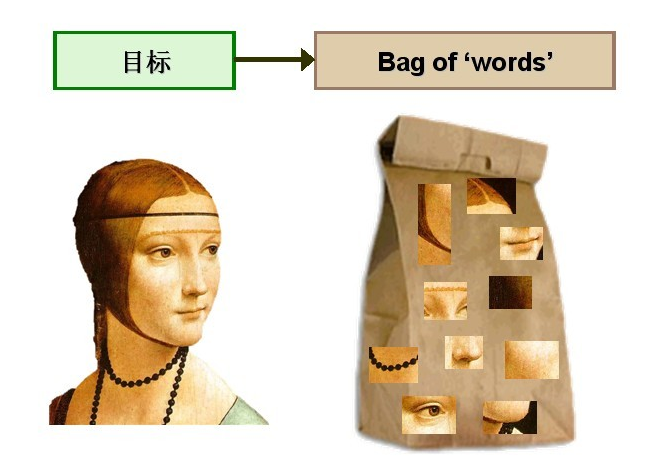
三、实现步骤
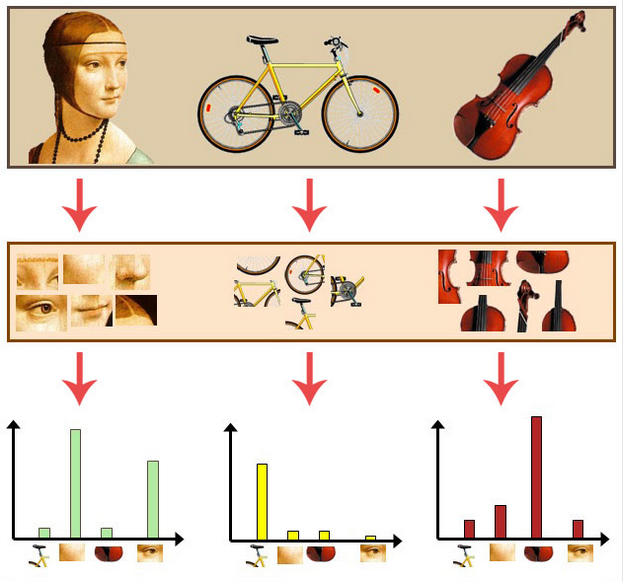
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
3.1 生成词袋
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:
(1)特征检测:在ORB_SLAM采用的是Fast角点检测。
(2)特征表示:128维的BRIEF描述子
(3)词袋生成:利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。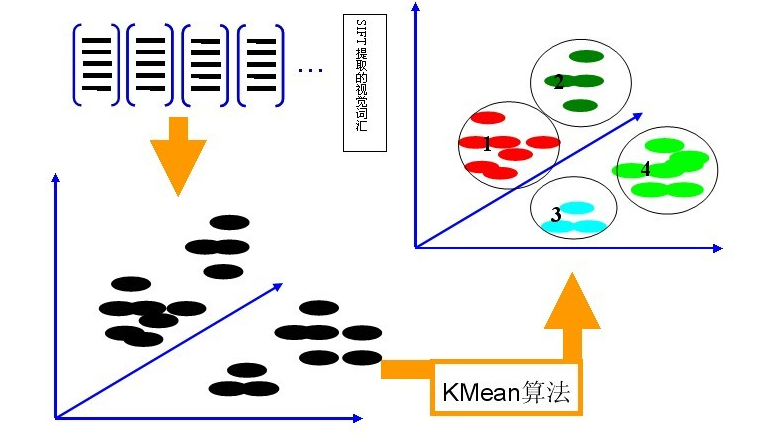
3.2 用词表示图像
利用单词表的中词汇表示图像。ORB_SLAM从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。——视觉词袋模型")
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
然后对于这些向量,使用SVM训练分类。因为使用的是局部特征+直方图统计的形式,因此即便是不同的人脸也会被分为一类。比如眼睛这一特征,不管人脸如何变化,眼睛这一特征的数量人脸也是比自行车或者吉他要多的。
实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
四、vocabulary tree(字典)
4.1 生成字典
ORB_SLAM中为了加速匹配采用了树的结构来存储词袋,这也就是我们常说的“字典”。具体步骤如下:
(1)遍历所有的训练图像,对每幅图像提取ORB特征点。
(2)设定vocabulary tree的分支数K和深度L。将特征点的每个描述子用 K-means聚类,变成 K个集合,作为vocabulary tree 的第1层级,然后对每个集合重复该聚类操作,就得到了vocabulary tree的第2层级,继续迭代最后得到满足条件的vocabulary tree,它的规模通常比较大,比如ORB-SLAM2使用的离线字典就有108万+ 个节点。
(3)离根节点最远的一层节点称为叶子或者单词 Word。根据每个Word 在训练集中的相关程度给定一个权重weight,==训练集里出现的次数越多,说明辨别力越差,给与的权重越低。==
4.2 使用字典
(1)对新来的一帧图像进行ORB特征提取,得到一定数量(一般几百个)的特征点,描述子维度和vocabulary tree中的一致
(2)对于每个特征点的描述子,从离线创建好的vocabulary tree中开始找自己的位置,从根节点开始,用该描述子和每个节点的描述子计算汉明距离,选择汉明距离最小的作为自己所在的节点,一直遍历到叶子节点。
整个过程是这样的,见下图。紫色的线表示 一个特征点从根节点到叶子节点的过程。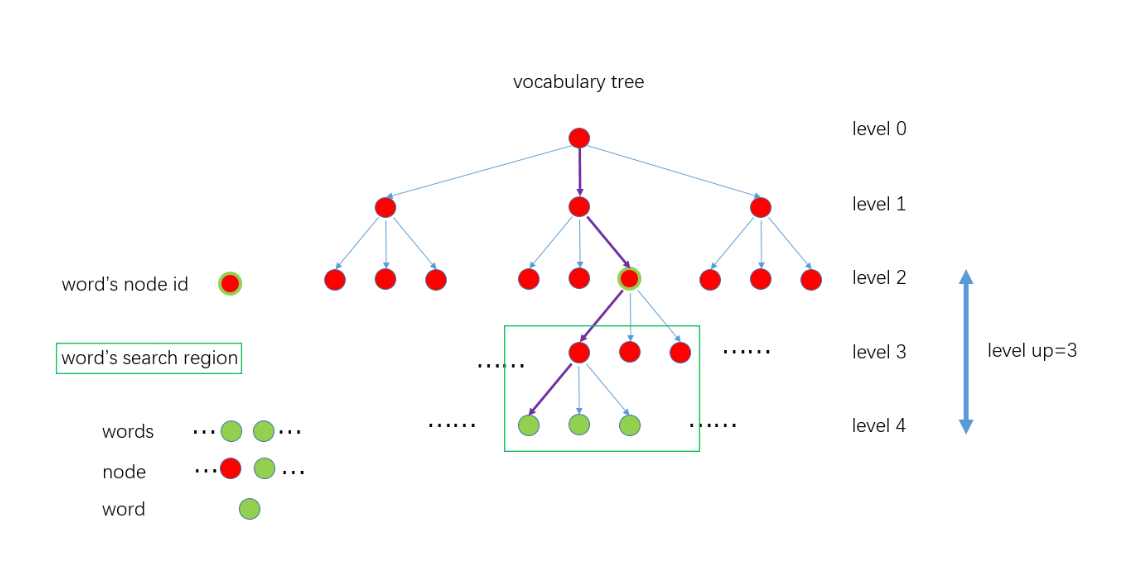
参考
论文:
《Bags of Binary Words for Fast Place Recognition in Image Sequences 》
链接:
https://customers.pyimagesearch.com/the-bag-of-visual-words-model/
https://blog.csdn.net/tiandijun/article/details/51143765