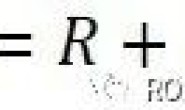AMCL是ROS/ROS2系统中最官方的定位模块,是导航模块中唯一指定的定位算法。在ROS/ROS2系统中,乃至整个移动机器人领域都是举足轻重的重要地位。虽然陆续也有许多其它的定位算法出现,但是在ROS/ROS2系统中,目前也仅仅是为AMCL打些配合类辅助。AMCL并不是时髦的新技术,很传统,也迟早会被其它更优秀的技术所代替。然而就目前来说,是所有机器人技术的初学者来说,是不折不扣的必备知识。
概论
AMCL是Adaptive Monte Carlo Localization(也即是自适应蒙特卡洛定位)的简称,是基于多种蒙特卡洛融合算法在ROS/ROS2系统中的一种实现。有人说这个不应该是Adaptive的意思,应该是Augmented的意思。这怕是对AMCL的误解。Augmented MCL是一种蒙特卡洛算法的演化,是强化了的蒙特卡洛算法,而AMCL是使用包括Augmented MCL算法在内的多种蒙特卡洛算法的适应性实现。一个指算法,一个指实现策略,两者不是同一个概念。
")
蒙特卡洛定位(MCL)基于粒子滤波算法,其一大优点是不受场景的限制,算法简捷快速,同时也可以兼顾算法的精度问题。
粒子滤波使用粒子密度(也就是单位区间内的粒子数)表征事件的发生概率。根据选定的评估方程来推算事件的置信程度,并根据该结果重新调整粒子的分布情况。经过若干次迭代之后,粒子就高度分布在可能性高的区域了。
基于这种推论,MCL将复杂的数学运算,转换成了计算机更易理解的迭代求解,在机器人定位问题上得到了很好的泛化。
如上图所示,在AMCL包中,选型、配置了运动模型、传感器模型、蒙特卡洛航位推算算法、采样算法等等功能模块。传感器模型将传感器数据结构化,运动模型将机器人的运动进行分解和代数化。传感器模型和运动模型相辅相成,紧密合作,为蒙特卡洛滤波做好数据支撑。采样/重采样算法为定位的迭代运算和误差消除提供保障。
下面分别聊一聊各个模块。
传感器模型
传感器的种类与特性
在目前的移动机器人中,有许多种传感器是跟距离相关的。
")
最古老的就应该是防撞杆(bumper)这种了,碰到了我就停,没碰到我就向前走,目前低端的扫地机上都是使用这类的传感器作为运动控制的。在很多的移动机器人上,特别是工业领域里面使用的机器人,也会用保险杠跟紧急制动按钮配合使用,作为安全措施的最后一道屏障。不过这类传感器跟AMCL没有什么直接关系,不是本篇文章的讲解范畴。
各种惯性传感器(Inertial Sensor),例如重力加速计、陀螺仪、地磁仪等等,目前在移动机器人使用的也挺多。跟AMCL相关的常用的用法是将惯性传感器的数据转换成odom数据,作为定位滤波时的参考数据。
最最常用的还是距离传感器(Proximity Sensor,这个外来词汇,中文的翻译没有统一,有人直译成接近传感器,有人译成接近度传感器,有人译成近场传感器)。这里面最流行的时LiDAR线性雷达,数据精密、效率高,技术成熟。
基于摄像机的视觉传感器,是一种新型的定位传感器,也注定是现代机器人的发展方向。不过就目前来说,还不是在精度有一定要求的定位算法的首要传感器来源。
诸如GPS等基于卫星的传感器,有其特定的定位算法,在卫星技术越来越优化的今天,其定位精度也越来越高了,在全室外的场景下,是不可或缺的数据来源。而目前移动机器人的工作环境还主要是室内,因此AMCL也主要是解决室内定位的难题。
")
几种不同的距离传感器
针对于距离传感器来说,其在定位过程中的作用,主要任务是解决 P(Z|x),也就是在给定机器人位置 x 之后,如何评估获得已知观测信息 Z 的概率 P 的问题。如何测量这个概率,就是传感器模型要解决的问题。
波束模型(Beam model)
我们讨论的距离传感器,都是波束型的(Beam-based),也就是都是以传感器为中心向空间发射、通过光或者其它物质的直线传播的时间差来获得距离信息。
为了简化计算,我们为距离传感器设定一个假设:在给定机器人位置之后,其所有的观测都是独立的。这个假设也就限定了移动机器人的适用场景。好在这个假设,在现实世界下通常是成立的。
这个假设的数学表达为:
如果给定K个观测,
")
其在某给定位置的概率表达为:
")
这里提到的观测(Measurement, Z )实际指的就是传感器获得的数据,它是一个集合,包含K个值。 m是给定地图信息,表征的是传感器活动的物理世界在数学上的表示, x 是传感器在地图 m上的位置。
因为各个观测 zi是相互独立的,因此可以拆开为各个分量概率的乘积。
NOTE:这一段描述,有可能有些童鞋听的不太明白,这里有一些数学知识在里面。如果不理解也没有关系,略过这部分内容继续向下看,之后抽空在多想想,或许也就明白了。
传感器模型为了准确描述测量(measurement),重点是要定义各种测量误差并且量化这些误差。
【注】观测是总称,测量是观测中的某一个分量。
常见的传感器观测主要来源于这四类:
")
简而言之,对于某一个特定的测量,不外乎四种情况:
- 正确测量。看到了已有的障碍物,这个是期望的情况。这一类的测量,标记为hit。
- 意外对象。没有看到已有的障碍物,因为被更前景的活动的人体或者其它障碍物遮挡。这个并不是期望的情况,但是在移动机器人场景中常见。现代机器人需要具备在有动态障碍物的环境中运行。这类测量标记为short。
- 随机测量。没有看到已有的障碍物,也没有动态障碍物遮挡,毫无缘由的随机值。这类的随机值并不是最大值或者无效值,对于定位匹配的危害较大,标记为rand。
- 漏检。本来有已知的障碍物,但是测量返回时最大值或无效值,也就是无障碍物的状态。这类测量标记为max。
在一个理想世界中,一个距离传感器总是能够测量到测量范围内的最近的物体的准确距离。然而现实世界并非如此。这4种测量同时存在,并且每一种观测都能够引入误差,因此也就意味着所有的测量都只是一个概率值,前面所述的4中测量的概率值依次记为 Phit, Pshort, Prand 和 Pmax 。
如前所说,准确测量这些概率值,就是传感器模型的首要任务,也是传感器模型的最终解。
根据误差的来源和表现形式,传感器模型(即4种观测的概率分布)如下图所示。
")
")
Phit的误差主要由距离传感器的有限分辨率、大气对测量信号的影响等引起,因此通常用高斯分布来建模,均值为Zexp, 也就是在地图map中该条柱线(Beam)上最近的障碍物的理论值;方差为 b,与传感器的硬件属性相关。
Pshort的存在是因为我们总是假设移动机器人的活动环境是动态,而地图是静态的,因此真实的障碍物情况会有概率跟地图信息不匹配。我们总是假定,典型的或者现代的机器人应该是跟人或者其它可移动的物体共享工作空间,甚至我们需要既定操作空间是可以动态调整的。动态的障碍物总是发生在已知的障碍物之前,因此 Pshort 的非零值只会发生在[0, zk]之间,因为比已知的障碍物离传感器更远的动态障碍物没有意义。而且,离传感器越近的障碍物,发生遮挡的概率越高,离传感器越远,概率越小。(这段写的有点拗口,但是想通了,就是很简单的道理。)
按照经验,将 Pshort用指数分布来建模。在指数分布的模型中,引入预设参数λ,来调整指数分布的斜度,以适应不同的传感器参数和场景要求。(注:这个参数在AMCL的可配置参数列表中)。
Pmax表示检测失败的概率。有时候环境中的障碍物会被完全忽略。例如,在声纳传感器中遇到了镜面反射,或者LiDAR传感器遇到黑色吸光物体、强烈的阳光或灯光照射以及遇到透明玻璃等。将这类误差建模成均匀分布,符合人们的直觉。
Prand 是用来描述除上面3中情形之外所有无法解释的测量的情况。我们总是假定这种情况的存在,来增加数据建模的完整程度。随着硬件制造技术的提高,这种无法解释的测量比例越来越少了,这类型误差的影响也越来越小。
综上,我们把这4种情形简单低组合起来,也就形成了一种通用的传感器模型:
")
注意:图中的“unexp”就是上文提到的“short”,都是指动态障碍物的情况。
由此,该传感器模型引入了6个超参: αhit , αshort , αrand, αmax, b( Phit的方差)和λ(动态障碍物的影响力度)。剩下的问题就变成了如何选定这6个超参,这也是AMCL中的几个重要参数。具体求解的方法有两个:
- 经验值
- 基于数据的数学推导。
由于篇幅问题,这里不再展开。
似然域模型(Likelihood Field)
下面我们还要来重点介绍一下另一种传感器模型:似然域(Likelihood Field)。这种模型既简洁又高效,也是AMCL中推荐使用的。
讲似然域模型之前,先来讲一下波束模型的局限。
基于波束的传感器模型,与几何学和物理学紧密联系的同时,也具有2个主要的缺点:
- 波束模型缺乏光滑性。特别是在又许多小的障碍物的混乱环境中,分布
在 xt 处是不光滑的。不光滑的意思是指,如果机器人在 xt处做微小的位移,其得到的传感器数据很可能就发生很大的差异。譬如,在又很多椅子和桌子的会议室场景,如果传感器的安装的够低的话,那么机器人检测到的就都是这些障碍物的腿,那么机器人做微小移动,传感器波束就会发生很大改变,也就意味着对距离的推断会发生很大的假设变换,因而引起位置估计的大误差。而缺乏光滑性会产生比较严重的后果。首先,会导致置信度的不连续。置信度偏重是一个超参,在这种情况下,无论如何设置这个参数,都不准确,都有可能错过正确状态。其次,波束的不光滑,常常会出现局部极小问题,而错过全局最优,也就容易导致机器人定位丢失现象。
- 波速模型涉及的计算量偏大。该模型要求对每一个波束都要做射线投射,这需要很大的计算量。如果将机器人工作空间的地图表示离散栅格化,可以将一部分的计算预处理,可以起到一定的运行时间的优化,然而这种优化是以消耗大量的内存作为代价的,因而也是一种不可能的方案。
似然域模型就是用来解决波束模型的这些缺陷的。这种模型符合数学证明以及实践检验,但缺乏合理的物理解释。这种模型不计算基于传感器物理特性而生成的条件概率,而只是将工作空间的障碍物情况做整体的模糊处理,可以使用各种空间情况,得到的后验更光滑,计算更高效。
同样地,我们首先也需要先假定传感器模型的噪声跟误差来源。我们假定有3种来源:
- 测量噪声。
- 测量失败。
- 无法解释的随机测量。
测量噪声是指测量得到的障碍物的位置跟地图上显示的障碍物位置不能完全吻合。此类噪声可以用以地图上距离该测量终点最近的障碍物为中心,两者之间的欧氏距离为方差的高斯分布来拟合。也就是说,这种模型对概率分布的求解,只关注测量到已知障碍物的末端,而不是关心所有波束的数学跟物理特性。因此说对于给定地图m和机器人方位(也就是传感器方位) xt 的情况下,对观测结果z的分布概率为:
")
这里d是测量末端到最近的障碍物的欧氏距离,σ是一个特别重要的超级参数,表示了障碍物的膨胀级别,也反映了算法的收敛效率,可以根据传感器的精度跟地图的精度来设置。大家切记。
测量失败是指在某个特定的测量方向上,本来有障碍物,但是没有被测量到,也就是测量结果为最大值,而实际应该小于最大值。(这个分布跟波束模型的 pmax 是一致的)。
无法解释的随机随机测量,是指某个测量值并不是最大值,也不是障碍物的近距离误差表示,它对应于波束模型的 prand 。
这段话,很多同学可能看的云里雾里。下面用个例子吧。
")
上图左边给出了一个地图,地图上有3个障碍物(灰色部分),一个正方形,两个小圆点。图下方的小原型代表机器人及其方向。从机器人发出的虚线代表传感器的某一个测量。
上图右边是针对于给定地图的似然域,是一张单色(黑、白、灰)的灰度图,颜色越白表示该区域检测到障碍物的可能性越大,反之,颜色越深,可能性越小。大家注意,这个似然域是根据确定的地图预先设置的,并不会随着机器人的位置跟观测的不同而不同。
而对于这个灰度图,你可能自然而然地想到了navigation模块种的costmap,他们使用的是同一种表示方法。对于占用地图的模式来说,这是一种常用的减少运行时计算量的方法。
以图上给定的这条观测为例,其观测的概率分布如下图:
")
图上有3个明显的波峰,分别对应该次观测(也就是图上虚线)依次离3个障碍物最近的地图。依次的意思是从机器人出发、沿虚线向远处依次检测的过程。
该概率曲线是上面提到的3种误差分布的叠加,即一个高斯分布和两个均匀分布。
另外,似然域模型跟地图并不是一种强性绑定,如果没有地图信息,直接通过传感器的观测数据生成一个基于该部分数据的似然域。下图给出了一个基于LiDAR传感器的依次扫描之后得到的数据,然后用这些scan数据生成的似然域表示。
")
基于单次的扫描数据生成的似然域表示,事实上定义了一个局部地图,它在校准独立扫描技术中起着很重要的作用。
说得更明白一点,预处理的似然域跟地图存在很好的一一对应的关系。请看下面的例子,左边是占用栅格地图,右边是预处理的似然域。
")
下面的程序伪代码给出了用似然域模型计算测量概率的算法。
")
该算法跟上面提到的那个概率图形,并不完全吻合,是一个简化版本,也是ROS/ROS2 AMCL模块种使用的版本。
在这个算法中,忽略了测量失败的情况(伪代码第3行),这样就减少了一个超参,而对概率的估计影响也不大。某一次观测的概率分布是该次观测中所有有效测量(包括hit和rand两类)的概率分布的成绩。
这个算法引入了3个超参: phit、 prandom和σ。比波束模型少。
【注】: phit、 prandom对应波束模型超参中的 αhit,αrand。
好了,简单地做一下总结:
似然域模型的优势:
- 高效,使用2D的似然域预查表,跟ROS/ROS2的假设完全吻合。
- 光滑连续可求导,即使在障碍物混乱的场景。
- 因为可求导,因此可以使用诸如爬坡算法、梯度下降算法等做优化
- 不需要依赖波束的物理特性
当然似然域模型,也有一些缺点:
- 弱化了动态障碍物的影响,因此在动态障碍物比较多的情况下需要格外小心
- 没有为光束做物理特性建模,那么从算法上无法杜绝波束穿墙的非正常情况。也就是无法确保测量的末端位置应该处于传感器与障碍物之间。
- 算法上没有处理未知区域,在给定的算法上地图上只有障碍物跟空白区域两种状态。(当然,在AMCL模块中,增加了逻辑处理未知区域。)
当然,还有其它一些传感器模型算法,因为跟AMCL包关系不大,不展开了。