轻量级实时语义分割:ENet & ERFNet
- ENet
- ERFNet
- 总结
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation发表在CVPR2016上。 ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation则发表在2018年1月的IEEE Transactions on Intelligent Transportation Systems的期刊。 两者任务均为轻量级实时性语义分割。
ENet
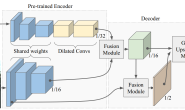
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation 问题 目前已有的几种语义分割网络如SegNet、FCN等,存在参数量大,处理时间长的问题。 之前的方法: 1.在FCN中把全连接层换成了卷积层,但还是无法实时。 2…如使用简单的分类器并使用条件随机场CRF级联它们当成后处理,但该技术很麻烦并且无法label帧中某一类像素较少的类别。 3.将CNN与RNN结合提高精度,也挺耗时。 方法 网络输入与输出分辨率相同:512×512。 左侧图a是输入的初始化步骤。右侧图b是一个改进版的bottleneck模块,原版bottleneck来源于ResNet论文中。 同时作者在所有卷积层中使用了Batch Nomalization和PRelu激活函数。在各个步骤也使用了常规的、空洞、全卷积或不对成卷积(如1×5等),并使用了Dropout随机失活。  下图为整个网络的结构,前三个stage是encoder,后两个是decoder,其中第二和第三个stage是一样的操作除了第三个阶段一开始没有进行下采样。作者没有在任何投影中使用bias项,这可以减少内核数量以及过多的内存操作。
下图为整个网络的结构,前三个stage是encoder,后两个是decoder,其中第二和第三个stage是一样的操作除了第三个阶段一开始没有进行下采样。作者没有在任何投影中使用bias项,这可以减少内核数量以及过多的内存操作。  设计原因 一、feature map resolution 下采样有两大缺点:
设计原因 一、feature map resolution 下采样有两大缺点:
- 丢失精准边缘等空间信息。
- 像素级别的语义分割要求输入输出的分辨率一致。
意味着强下采样需要强上采样一起配合,但却很耗时。 第一个解决方法为FCN中在upsampling的feature map 加上 encoder生成的feature map。  第二个解决方法为:保存在最大池化层中最大元素索引,并使用它们在解码器中生成稀疏的上采样映射。即在下采样使把最大元素与其位置保存起来,上采样时将最大元素填充到原来的位置并在其他位置用零补充。
第二个解决方法为:保存在最大池化层中最大元素索引,并使用它们在解码器中生成稀疏的上采样映射。即在下采样使把最大元素与其位置保存起来,上采样时将最大元素填充到原来的位置并在其他位置用零补充。  作者采用了第二种方法,原因使无需更多的内存。并且发现了强下采样会损害精度,需要限制尽可能它。但下采样的卷积操作也有个好处即有着更大的感受野能够获得更多的context。作者使用了空洞卷积使感受野更大从而使信息更丰富。 二、Early downsampling 作者认为处理分辨率高的输入图片非常耗时,并且视觉信息空间高度冗余,于是先初始化使得分辨率变小(更加有效的表达形式),而且这初始化网络层不应该和分类有着直接贡献,它们应被当成好的特征解析器仅对网络后面的部分进行预处理。 三、Decoder size 本网络包含非对称结构:较大的encoder 和 较小的 decoder。encoder是为了为小分辨率数据提供处理和过滤信息。decoder是为了调整细节。 四、Nonlinear operations 使用ReLU会损害精度,故作者采用了PReLU。在每个feature map使用一个额外的参数,以学习非线性的负斜率。 五、Information-preserving dimensionality changes 作者认为,激进的维数下降会阻碍信息流,故选择在stride 2的卷积下并行执行pooling操作,并将得到的feature map连接起来。这项技术能够将对初始块的推断时间缩短10倍。 六、Factorizing filters 研究表明,卷积权值具有相当多的冗余,每个n×n卷积可以依次分解为两个较小的卷积:一个是n×1滤波器,另一个是1×n滤波器。使用两个卷积:1×5和5×1的卷积来代替两次3×3卷及操作,增加通过块学习函数的多样性并增加感受野。 七、Dilated convolutions 具有广泛的接受野是非常重要的,因此它可以通过考虑更广泛的上下文来进行分类。希望避免对特征图的过度采样,并决定使用扩展卷积。主要适用于在最小分辨率操作阶段中几个bottleneck模块中的主要卷积层。依靠空洞卷积没有额外消耗资源地增加了精度,交错式的将空洞卷积运用在bottleneck(常规和非对称卷积)上。 八、Regularization 使用L2权重衰减的效果不好,于是尝试stochastic depth提高了精度。然而,丢弃整个分支(即,将其输出设置为0)是应用Spatial Dropout的一种特例。作者就将空间Dropout放在了卷积分支的末尾,但在加和之前,结果比stochastic depth要好。 结果
作者采用了第二种方法,原因使无需更多的内存。并且发现了强下采样会损害精度,需要限制尽可能它。但下采样的卷积操作也有个好处即有着更大的感受野能够获得更多的context。作者使用了空洞卷积使感受野更大从而使信息更丰富。 二、Early downsampling 作者认为处理分辨率高的输入图片非常耗时,并且视觉信息空间高度冗余,于是先初始化使得分辨率变小(更加有效的表达形式),而且这初始化网络层不应该和分类有着直接贡献,它们应被当成好的特征解析器仅对网络后面的部分进行预处理。 三、Decoder size 本网络包含非对称结构:较大的encoder 和 较小的 decoder。encoder是为了为小分辨率数据提供处理和过滤信息。decoder是为了调整细节。 四、Nonlinear operations 使用ReLU会损害精度,故作者采用了PReLU。在每个feature map使用一个额外的参数,以学习非线性的负斜率。 五、Information-preserving dimensionality changes 作者认为,激进的维数下降会阻碍信息流,故选择在stride 2的卷积下并行执行pooling操作,并将得到的feature map连接起来。这项技术能够将对初始块的推断时间缩短10倍。 六、Factorizing filters 研究表明,卷积权值具有相当多的冗余,每个n×n卷积可以依次分解为两个较小的卷积:一个是n×1滤波器,另一个是1×n滤波器。使用两个卷积:1×5和5×1的卷积来代替两次3×3卷及操作,增加通过块学习函数的多样性并增加感受野。 七、Dilated convolutions 具有广泛的接受野是非常重要的,因此它可以通过考虑更广泛的上下文来进行分类。希望避免对特征图的过度采样,并决定使用扩展卷积。主要适用于在最小分辨率操作阶段中几个bottleneck模块中的主要卷积层。依靠空洞卷积没有额外消耗资源地增加了精度,交错式的将空洞卷积运用在bottleneck(常规和非对称卷积)上。 八、Regularization 使用L2权重衰减的效果不好,于是尝试stochastic depth提高了精度。然而,丢弃整个分支(即,将其输出设置为0)是应用Spatial Dropout的一种特例。作者就将空间Dropout放在了卷积分支的末尾,但在加和之前,结果比stochastic depth要好。 结果 

ERFNet
ERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic Segmentation 问题 ENet的方法虽然参数小,速度快,但精度太差。 方法 A. Factorized Residual Layers  上图a和b均为ResNet提出的模块,两者有着相似的参数和接近的精度。但是,bottleneck需要更少的计算资源,随着深度增加这个特点更加划算,因此更加通用。但是,non-bottleneck模块能够获得更好的精度,并且bottleneck仍存在退化问题。 于是作者提出了一个新的版本,如上图c所示。新版本完全使用了1D 卷积。抛开烦人的公式,借用李宏毅模型压缩里的PPT里的一张图:
上图a和b均为ResNet提出的模块,两者有着相似的参数和接近的精度。但是,bottleneck需要更少的计算资源,随着深度增加这个特点更加划算,因此更加通用。但是,non-bottleneck模块能够获得更好的精度,并且bottleneck仍存在退化问题。 于是作者提出了一个新的版本,如上图c所示。新版本完全使用了1D 卷积。抛开烦人的公式,借用李宏毅模型压缩里的PPT里的一张图:
 同理,只要kernal的数量较小,这样的操作既可以近似出原来的效果,但也减少了参数量,只需要更少的计算量。并且,作者在两层1D卷积之间也增加了非线性函数,理论上增加了学习的能力。提出的这一模块可以用于任何需要用到ResNet网络的任务中。 B. 网络架构 ERFNet的网络架构就像之前ENet的编码-解码器架构。与像FCN架构相反,在这种架构中,不同层的特征映射需要被融合,以获得一个细腻的输出。
同理,只要kernal的数量较小,这样的操作既可以近似出原来的效果,但也减少了参数量,只需要更少的计算量。并且,作者在两层1D卷积之间也增加了非线性函数,理论上增加了学习的能力。提出的这一模块可以用于任何需要用到ResNet网络的任务中。 B. 网络架构 ERFNet的网络架构就像之前ENet的编码-解码器架构。与像FCN架构相反,在这种架构中,不同层的特征映射需要被融合,以获得一个细腻的输出。  其中下采样虽然获得了粗糙的输出,但降低了计算量,网络进行了三次下采样,并借鉴了ENet的早期下采样(Early Sampling)模式:即将2×2的maxpooling和3×3卷积(2 strides)concat在一起。并且在提出的resnet block上交错使用空洞卷积(被证明比使用更大size卷积有用),以获得更多的信息。此外也使用了Dropout。 上采样部分仅有调节细腻度并与输入匹配的作用,采用了和ENet类似的架构。不同的是,没有采用ENet的max-unpooling模式。论文采用了简单的步长为2的反卷积(deconvolution layers with stride 2)。 结果
其中下采样虽然获得了粗糙的输出,但降低了计算量,网络进行了三次下采样,并借鉴了ENet的早期下采样(Early Sampling)模式:即将2×2的maxpooling和3×3卷积(2 strides)concat在一起。并且在提出的resnet block上交错使用空洞卷积(被证明比使用更大size卷积有用),以获得更多的信息。此外也使用了Dropout。 上采样部分仅有调节细腻度并与输入匹配的作用,采用了和ENet类似的架构。不同的是,没有采用ENet的max-unpooling模式。论文采用了简单的步长为2的反卷积(deconvolution layers with stride 2)。 结果

总结
ENet和ERFNet在实时性语义分割算是在近五年中较早一批且比较好的工作了。 在Cityscapes数据集上,ENet的IoU达到了58.3,而ERFNet的IoU达到了69.7,精度提升10个点。参数方面,根据RRFNet里的实验数据,ERFNet的参数量比ENet大十倍,速度方面是ENet的将近一半。 总的来说,虽然ERFNet参数量较大,运行较慢,但精度也提升大,实时性和精度确实都在可接受的范围。两篇论文都在Resnet部分进行了改进,比较值得注意的是ERFNet中ResNet的Low-rank approximation的操作,貌似后面经常会使用到。