根据之前的配置,我们已经可以通过move_group发送出机械臂各关节运动的轨迹,并且通过三次样条插补的方法,赋予各个关节在特定角度时的速度和加速度,通过启动程序节点可以看到,本次运动规划使用了LBKPIECE算法,并且使用了4线程并行规划,规划时间为3.478750秒,一共规划了24个路径点。
[ INFO] [1572571719.182638906]: LBKPIECE1: Created 101 (47 start + 54 goal) states in 90 cells (45 start (45 on boundary) + 45 goal (45 on boundary))
[ INFO] [1572571719.184092677]: LBKPIECE1: Created 142 (66 start + 76 goal) states in 130 cells (65 start (65 on boundary) + 65 goal (65 on boundary))
[ INFO] [1572571719.261589804]: ParallelPlan::solve(): Solution found by one or more threads in 0.093549 seconds
[ INFO] [1572571719.261986784]: SimpleSetup: Path simplification took 0.000165 seconds and changed from 5 to 2 states
[ INFO] [1572571719.365034904]: First Move_group give us 24 points
[ INFO] [1572571719.365161116]: Second Move_group max_time is 3.478750
[ INFO] [1572571719.366106885]: Now We get all joints P,V,A,T!
通过上一偏博客所说,因为我觉得move_group规划的路径点有点少,所以将时间数组放大四倍(也就是相邻轨迹点取更短的时间间隔),最终规划的路点就是原来的四倍,效果也不是很理想,因为简单的扩大倍数,得到新的的时间数组的每个点的间隔不是个整数,这个间隔大约类似于0.03768这种看起来比较糟糕的一串数字,而且精度只达到了十毫秒级别,不是很精确。于是改变上述的服务器程序,将三次样条插补的时间间隔取到 0.004 秒,也就是4ms,至于为什么是4ms,而不是1ms或者其他时间,是综合考虑下的结果。下面详细说明。。。
一、首先从时间编程说起:
在不考虑实时性的前提下,通过TCP通信将插补后的数据发送到下位机,因为电机的控制涉及到时间,初步的构思有两种控制方式: 1.直接给定特定时间间隔,在上位机就根据给定时间间隔,计算好所有的PVT,然后通过TCP发送给下位机,下位机将所有数据用数组保存下来(考虑到不同路径规划的路点数目不一样,所以使用变长数组vector),此时下位机只需要读取PVT数组 2.直接将move_group规划好的位置和时间数组发送给下位机,让下位机去计算中间位置插补。 无论哪种方法,对时间的处理要求比较精细,因为插补之后的相邻时间间隔精度为毫秒级,所以要求下位机控制器的时间精度能达到毫秒级。从简化控制流程的角度来看,直接在上位机就将数据插补完成,只让下位机遍历数据控制电机即可,也就是说上位机负责计算,下位机负责控制。所以选择第一种方式。
二、程序执行时间计算:
平时我们使用的时间函数只能把时间精确到秒。如果对时间的处理精度为微秒级,需要使用函数gettimeofday。这个函数的使用方法如下所示:
int gettimeofday(struct timeval * tv , struct timezone * tz )
// 这个函数的参数是两个结构体指针。这两个结构体的定义如下所示。
struct timeval
{
long tv_sec;
long tv_usec;
};
//结构体成员的含义如下所示。
//tv_sec:当前时间的秒数。
//tv_usec:当前时间的微秒数。
// 函数 gettimeofday 会把当前时间的这些参数返回到这两个结构体指针上。如果处理成功,则返回真值 1,否则返回 0。
虽然 tv usec字段能提供微秒级精度,但其返回值的准确性则由依赖于构架的具体实现来决定。在现代X86-32系统上, gettimeofday 的确可以提供微秒级的准确度(例如, Pentium系统内置有时间戳计数寄存器,随每个CPU时钟周期而加一) 虽然 setitimer 使用的 timeval 结构提供有微秒级精度,但是传统意义上定时器精度还是受制于软件时钟频率。如果定时器值未能与软件时钟间隔的倍数严格匹配,那么定时器值则会向上取整。也就是说,假如有一个间隔为19100微秒(刚刚超过19毫秒)的定时器,如果jfy(软件时钟周期)为4毫秒,那么定时器实际上会每隔20毫秒过期一次。
软件时钟(jfe)在本书中所描述的时间相关的各种系统调用的精度是受限于系统软件时钟( software clock)的分辨率,它的度量单位被称为 jiffies. jiffies的大小是定义在内核源代码的常量HZ。这是内核按照 round- robin的分时调度算法(35.1节)分配CPU进程的单位在24或以上版本的 Linux/x86-32内核中,软件时钟速度是100赫兹,也就是说,一个jy是10毫秒。Linux面世以来,由于CPU的速度已大大增加, Linux/x86-322.6.0内核的软件时钟速度已经提高到1000赫兹。更高的软件时钟速率意味着定时器可以有更高的操作精度和时间可以拥有更高的测量精度。然而,这并非可以任意提高时钟频率,因为每个时钟中断会消耗少量的CPU时间,这部分时间CPU无法执行任何操作。经过内核开发人员之间的的讨论,最终导致软件时钟频率成为一个可配置的内核的选项(包括处理器类型和特性,定时器的频率)。自2.6.13内核,时钟频率可以设置到100、250(默认)或1000赫兹,对应的jmiy值分别为10、4、1毫秒。自内核26.20,增加了个频率:300赫兹,它可以被两种常见的视频帧速率25帧每秒(PAL)和30帧每秒(NTSC)整除.
虽然gettimeofday的时间精度能达到毫秒级,我们依然不能简单的使用这个函数去处理时间延时,因为仅仅延时是不够的,其中还涉及到操作文件,读写数据,累积起来的误差可能相当离谱。简言之,gettimeofday这类时间编程函数虽然本身精度够高,但是提供不了类似定时器中断的功能,多次执行之后,误差会很大。 虽然不能用这个去控制延时时间,但是用它粗略的计算程序执行的时间,和路径规划的时间做比较,那将有大大的用武之地!!如下:
#include <iostream>
#include <time.h>
int main()
{
while(1)
{
// PRU开始时间
struct timeval start;
gettimeofday(&start,NULL);
// 加载并执行 PRU 程序
prussdrv_exec_program (PRU_NUM, "./redwall_arm_client.bin");
// pru结束时间
struct timeval end;
gettimeofday(&end,NULL);
double diff;
diff = end.tv_sec -start.tv_sec + (end.tv_usec - start.tv_usec)*0.000001;
cout<< "EBB PRU程序已完成,历时约 "<< diff << "秒!" << endl;
}
}
}
上述代码可以判断beaglebone执行./redwall_arm_client.bin(单独编译的PRU汇编程序,用来精确的执行机械臂电机控制)所消耗的时间,用来和期望的时间做比较,从而计算误差。
三、PRU实时接口 汇编指令处理延时
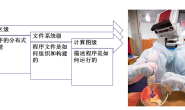
如图所示工控机将PVT运动数据通过TCP协议传送给多轴控制器由多轴控制器完成插值运算并通过控制器控制各轴完成预定动作。整个机械系统由6个直流伺服电机驱动并选用以色列ELMO公司电机驱动器及控制器。
---延时时间精确控制") 此处的多轴控制器使用的是beaglebone,基于ARM架构的板子,beaglebone提供实时接口,linux默认情况下是非抢占式操作系统,所以对于机械手这种需要在规定时间内完成特地的实时任务,或对于高速信号发生器或采样点模式,则linux提供的软实时系统无法满足要求。 PRU-ICSS(工业通信子系统)可以完成精确计时、计算.实时系统通常被描述为不考虑负载的情况下,能否在规定时间(ms/us级别)内得到有效响应。 beaglebone的AM335x处理器包含两个32位200MHZ的PRU核,称为PRU0和PRU1,每个核都带有8kb的程序存储器和8kb的数据存储器,程序存储器存储的是PRU要执行的程序指令,而数据存储器通常用于存储由程序指令操纵的数据或数组.PRU0使用的数据存储器是RAM0,PRU1使用的是RAM1,但是,每个PRU也可以访问另一个PRU的数据内存和一个12kb的独立共享内存。
此处的多轴控制器使用的是beaglebone,基于ARM架构的板子,beaglebone提供实时接口,linux默认情况下是非抢占式操作系统,所以对于机械手这种需要在规定时间内完成特地的实时任务,或对于高速信号发生器或采样点模式,则linux提供的软实时系统无法满足要求。 PRU-ICSS(工业通信子系统)可以完成精确计时、计算.实时系统通常被描述为不考虑负载的情况下,能否在规定时间(ms/us级别)内得到有效响应。 beaglebone的AM335x处理器包含两个32位200MHZ的PRU核,称为PRU0和PRU1,每个核都带有8kb的程序存储器和8kb的数据存储器,程序存储器存储的是PRU要执行的程序指令,而数据存储器通常用于存储由程序指令操纵的数据或数组.PRU0使用的数据存储器是RAM0,PRU1使用的是RAM1,但是,每个PRU也可以访问另一个PRU的数据内存和一个12kb的独立共享内存。
---延时时间精确控制") PRU 程序可以使用自带的通用本地寄存器,用来存储和检索数据,因为这个本地PRU存储已经被隐射到LINUX主机上的全局地址空间,这样就可以在PRU和linux主机程序之间实现数据共享。(这个很重要,内存空间一定要搞清楚,这是后面编写汇编程序和C程序的前提)
PRU 程序可以使用自带的通用本地寄存器,用来存储和检索数据,因为这个本地PRU存储已经被隐射到LINUX主机上的全局地址空间,这样就可以在PRU和linux主机程序之间实现数据共享。(这个很重要,内存空间一定要搞清楚,这是后面编写汇编程序和C程序的前提)
- PRU0 映射的起始地址0x0000 0000 在内存空间实际的地址0x4a30 0000 数据空间最长为8KB
- PRU1 映射的起始地址0x0000 0000 在内存空间实际的地址0x4a30 2000 数据空间最长为8KB
- 共享空间 映射的起始地址0x0001 0000 在内存空间实际的地址0x4a31 0000 数据空间最长为12KB
通过上述地址就可以看出来,为什么每个PRU也可以访问另一个PRU的数据内存和一个12kb的独立共享内存,通过基址偏移访问对应地址空间就可以访问其他核或者共享内存的数据。虽然数据在内存空间中可以被共享访问,但是也可以看出来,每个PRU内存是很有限的,仅为8KB,所以当我们编写程序的时候,就不能让数据长度超过8KB,例如,int array[100];int 类型占据4个字节, 4X100 = 400个字节 小于 8 x 1024 个字节,没有超出! 但是 加长数组的长度,int array[4000]; 则 4 x 4000 = 16000 大于 8 x 1024 ,所以超过的程序会覆盖到PRU1对应的地址空间,访问就会出错。至于为什么数组长度我要举例为4000,因为机械臂一次路径规划完成的时间大概为3到4秒,如果每次控制时间取0.001s即1ms,则会产生一个长度越为4000的数组。如果数组过长,这样取时间间隔就无法完成任务。那么8KB的内存到底满足多长的int类型数组呢? 8 x 1024 / 4 = 2048 个,也就是int array[2048] 数组长度相对于4000来说缩减了一半,考虑到还有其他一些数据,例如所以每次控制时间取0.003或者0.004秒 ,如果不想改变控制时间,必须要存储4000的长度,那么可以分割数组,分阶段的将数据存储。我的机械臂实际取的是4ms,这会产生一个1000左右长度的int类型的数组。
// 实例化样条
cubicSpline spline;
double max_time = time_from_start[point_num-1]; // ROS规划的最大时间
ROS_INFO("Second Move_group max_time is %f ",max_time);
double rate = 0.004; // 这就是时间间隔4ms
time_from_start_.clear(); // 清空
// lumbar关节三次样条插补
spline.loadData(time_from_start, p_lumbar, point_num, 0, 0, cubicSpline::BoundType_First_Derivative);
p_lumbar_.clear();
v_lumbar_.clear();
a_lumbar_.clear();
x_out = -rate;
while(x_out < max_time) {
x_out += rate;
spline.getYbyX(x_out, y_out);
time_from_start_.push_back(x_out); // 将插补之后的数据存储
p_lumbar_.push_back(y_out);
v_lumbar_.push_back(vel);
a_lumbar_.push_back(acc);
}
接下来通过TCP将所有数据从上位机传输到下位机的beaglebone。具体完整程序会在后续博客给出。
四、数据写入PRU内存
将数据写入PRU 内存的方法有两种,一种是调用prussdev_pru_write_memory()函数,例如,使用PRU PWM生成器时,使用该函数将PWM的占空比和延时因子传递到内存中,然后汇编程序根据延迟因子和占空比输出pwm。
// 将占空比50%复制到PRU中
unsigned int percent = 50;
prussdrv_pru_write_memory(PRUSS0_PRU0_DATARAM, 0, &percent, 4);
// 将10us周期写入内存中的下一个 word 位置(即 4-bytes 后)
unsigned int sampletimestep = 10;
prussdrv_pru_write_memory(PRUSS0_PRU0_DATARAM, 1, &sampletimestep, 4);
第二种方法就是机械手程序里面会使用到的方法:
static void *pru0DataMemory;
static unsigned int *pru0DataMemory_int;
srand(unsigned int time(NULL));// 设置随机数的种子
prussdrv_map_prumem(PRUSS0_PRU0_DATARAM, &pru0DataMemory);
pru0DataMemory_int = (unsigned int *) pru0DataMemory;
unsigned int sampletimestep = 10; //delay factor 暂取10us
*(pru0DataMemory_int) = sampletimestep;
unsigned int numbersamples = v_lumbar.size(); //采样数
*(pru0DataMemory_int+1) = numbersamples;
for (i=0; i< v_lumbar.size(); i++)
{
*(pru0DataMemory_int+2+i) = rand()%50+1; // 1~50的随机数
}
// 覆盖设备树
$ sudo cp EBB-GPIO-Example-00A0.dtbo /lib/firmware
// 设置加载设备树的环境变量
$ export SLOTS=/sys/devices/bone_capemgr.9/slots
$ export PINS=/sys/kernel/debug/pinctrl/44e10800.pinmux/pins
$ source ~/.profile
// 加载设备树
$ sudo sh -c "echo EBB-PRU-Example > $SLOTS"
// 编译PRU程序
$ pasm -b redwall_arm_client.p
// 编译C++程序
$ g++ redwall_arm_client.cpp -o redwall_arm_client -lpthread -lprussdrv
// 执行C++程序,该程序会调用PRU程序
$ sudo ./redwall_arm_client
五、PRU程序调试软件的使用
prudebug 软件的使用,可以帮助调试PRU汇编程序,在github上面下载完整的prudebug_master软件包github.com/poopgiggle/prudebug 将软件包下载到板子当中,解压之后进入目录 直接make编译即可。使用方法,详见README,这里主要介绍几个比较常用的指令 用法:prudebug [-a pruss-address] [-u] [-m] [-p处理器] -a-pruss-address为ARM存储器空间中PRU的存储器地址-u-强制使用UIO映射PRU存储器空间 -m- 如果未使用-u或-m选项,则强制使用/ dev / mem映射PRU内存空间,然后它将首先尝试UIO -p- 选择要使用的处理器(设置PRU内存位置)AM1707- AM1707 AM335X-AM335x 运行pru程序之后,直接./prudbug 就会出现如下界面,在PRU0> 后面输入指令即可: PRU0> BR [breakpoint_number [address]]-查看或设置指令断点 D memory_location_wa [length]-PRU数据存储器的原始转储(与完整PRU存储器块的开头相距32位字偏移-所有PRU) DD memory_location_wa [length]-转储数据存储器(距PRU数据存储器开头的32位字偏移) DI memory_location_wa [长度]-转储指令存储器(距PRU指令存储器开头的32位字偏移) DIS memory_location_wa [长度]-反汇编指令存储器(32位从PRU指令存储器的开头开始的字偏移量) G-开始执行指令的处理器(当前IP) GSS-使用自动单步执行开始处理器的执行-这允许运行带有断点的程序 HALT- 暂停处理器 R-显示当前的PRU寄存器。 RESET-重置当前PRU SS-单步执行当前指令。 GSS 使用自动单步执行开始处理器的执行-这允许运行带有断点的程序