今天我们来说一下刷题时经常用到的前缀和思想,前缀和思想和滑动窗口会经常用在求子数组和子串问题上,当我们遇到此类问题时,则应该需要想到此类解题方式,该文章深入浅出描述前缀和思想,读完这个文章就会有属于自己的解题框架,遇到此类问题时就能够轻松应对。
下面我们先来了解一下什么是前缀和。
前缀和其实我们很早之前就了解过的,我们求数列的和时,Sn = a1+a2+a3+…an; 此时Sn就是数列的前 n 项和。例 S5 = a1 + a2 + a3 + a4 + a5; S2 = a1 + a2。所以我们完全可以通过 S5-S2 得到 a3+a4+a5 的值,这个过程就和我们做题用到的前缀和思想类似。我们的前缀和数组里保存的就是前 n 项的和。见下图

我们通过前缀和数组保存前 n 位的和,presum[1]保存的就是 nums 数组中前 1 位的和,也就是 presum[1] = nums[0], presum[2] = nums[0] + nums[1] = presum[1] + nums[1]. 依次类推,所以我们通过前缀和数组可以轻松得到每个区间的和。
例如我们需要获取 nums[2] 到 nums[4] 这个区间的和,我们则完全根据 presum 数组得到,是不是有点和我们之前说的字符串匹配算法中 BM,KMP 中的 next 数组和 suffix 数组作用类似。那么我们怎么根据 presum 数组获取 nums[2] 到 nums[4] 区间的和呢?见下图

好啦,我们已经了解了前缀和的解题思想了,我们可以通过下面这段代码得到我们的前缀和数组,非常简单
for (int i = 0; i < nums.length; i++) {
presum[i+1] = nums[i] + presum[i];
}
好啦,我们开始实战吧。
leetcode 724. 寻找数组的中心索引
题目描述
给定一个整数类型的数组 nums,请编写一个能够返回数组 “中心索引” 的方法。
我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
输入:
nums = [1, 7, 3, 6, 5, 6]
输出:3
解释:
索引 3 (nums[3] = 6) 的左侧数之和 (1 + 7 + 3 = 11),与右侧数之和 (5 + 6 = 11) 相等。
同时, 3 也是第一个符合要求的中心索引。
示例 2:
输入:
nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心索引。
理解了我们前缀和的概念(不知道好像也可以做,这个题太简单了哈哈)。我们可以一下就能把这个题目做出来,先遍历一遍求出数组的和,然后第二次遍历时,直接进行对比左半部分和右半部分是否相同,如果相同则返回 true,不同则继续遍历。
class Solution {
public int pivotIndex(int[] nums) {
int presum = 0;
//数组的和
for (int x : nums) {
presum += x;
}
int leftsum = 0;
for (int i = 0; i < nums.length; ++i) {
//发现相同情况
if (leftsum == presum - nums[i] - leftsum) {
return i;
}
leftsum += nums[i];
}
return -1;
}
}
leetcode 560. 和为K的子数组
题目描述
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
示例 1 :
输入:nums = [1,1,1], k = 2
输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
暴力法
解析
我们先来用暴力法解决这个题目,很简单,一下就能 AC。
这个题目的题意很容易理解,就是让我们返回和为 k 的子数组的个数,所以我们直接利用双重循环解决该题,这个是很容易想到的。我们直接看代码吧。
class Solution {
public int subarraySum(int[] nums, int k) {
int len = nums.length;
int sum = 0;
int count = 0;
//双重循环
for (int i = 0; i < len; ++i) {
for (int j = i; j < len; ++j) {
sum += nums[j];
//发现符合条件的区间
if (sum == k) {
count++;
}
}
//记得归零,重新遍历
sum = 0;
}
return count;
}
}
好啦,既然我们已经知道如何求前缀和数组了,那我们来看一下如何用前缀和思想来解决这个问题。
class Solution {
public int subarraySum(int[] nums, int k) {
//前缀和数组
int[] presum = new int[nums.length+1];
for (int i = 0; i < nums.length; i++) {
//这里需要注意,我们的前缀和是presum[1]开始填充的
presum[i+1] = nums[i] + presum[i];
}
//统计个数
int count = 0;
for (int i = 0; i < nums.length; ++i) {
for (int j = i; j < nums.length; ++j) {
//注意偏移,因为我们的nums[2]到nums[4]等于presum[5]-presum[2]
//所以这样就可以得到nums[i,j]区间内的和
if (presum[j+1] - presum[i] == k) {
count++;
}
}
}
return count;
}
}
我们分析上面的代码,发现该代码虽然用到了前缀和数组,但是对比暴力法并没有提升性能,时间复杂度仍为O(n^2),空间复杂度成了 O(n)。那我们有没有其他方法解决呢?
前缀和 + HashMap
了解这个方法前,我们先来看一下下面这段代码,保证你很熟悉
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer,Integer> map = new HashMap<>();
//一次遍历
for (int i = 0; i < nums.length; ++i) {
//存在时,我们用数组得值为 key,索引为 value
if (map.containsKey(target - nums[i])){
return new int[]{i,map.get(target-nums[i])};
}
//存入值
map.put(nums[i],i);
}
//返回
return new int[]{};
}
}
上面的这段代码是不是贼熟悉,没错就是那个快被我们做烂的两数之和。这一段代码就是用到了我们的前缀和+ HashMap 思想,那么我们如何通过这个方法来解决这个题目呢?
在上面的代码中,我们将数组的值和索引存入 map 中,当我们遍历到某一值 x 时,判断 map 中是否含有 target – x,即可。
其实我们现在这个题目和两数之和原理是一致的,只不过我们是将所有的前缀和该前缀和出现的次数存到了 map 里。下面我们来看一下代码的执行过程。
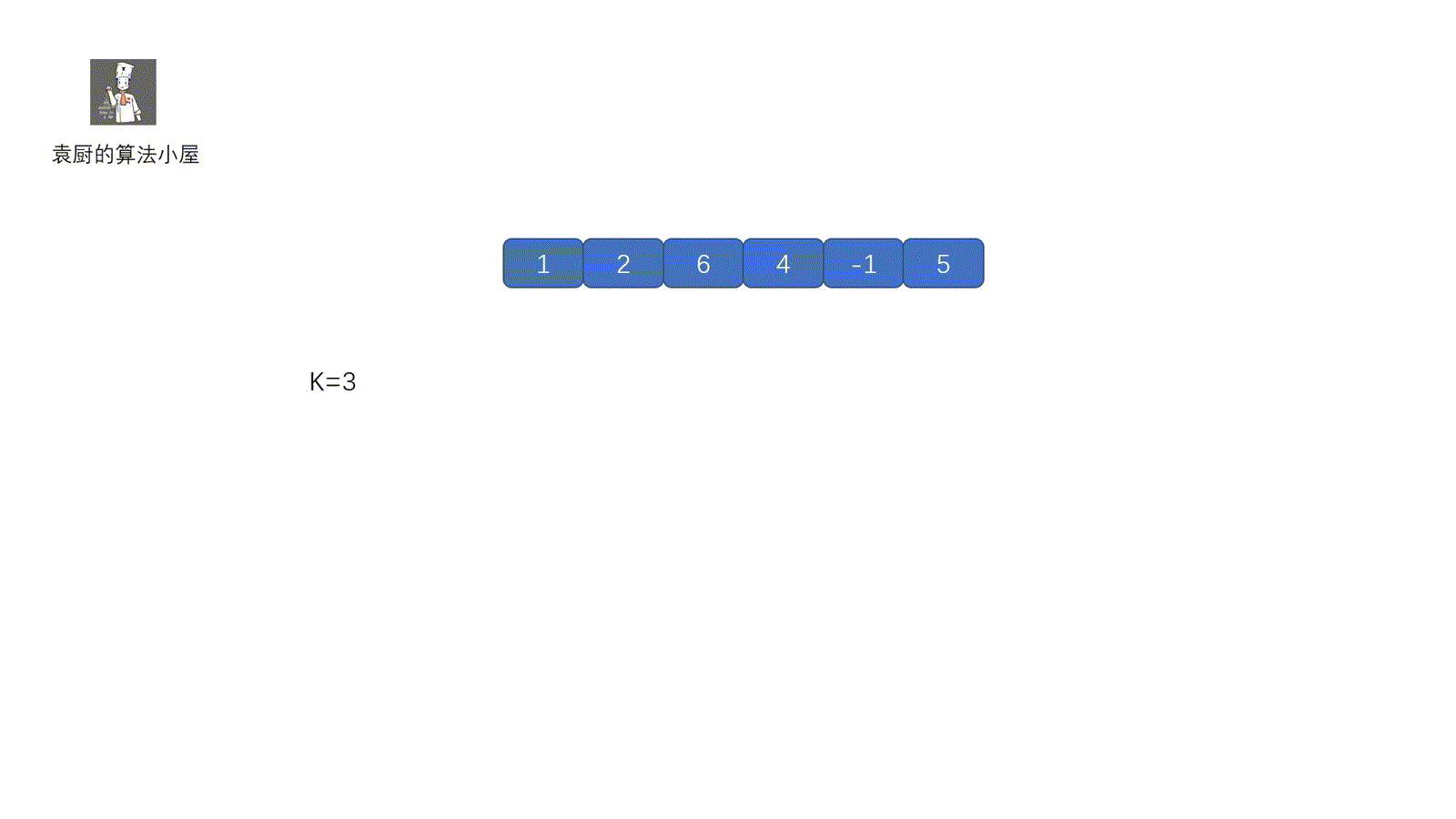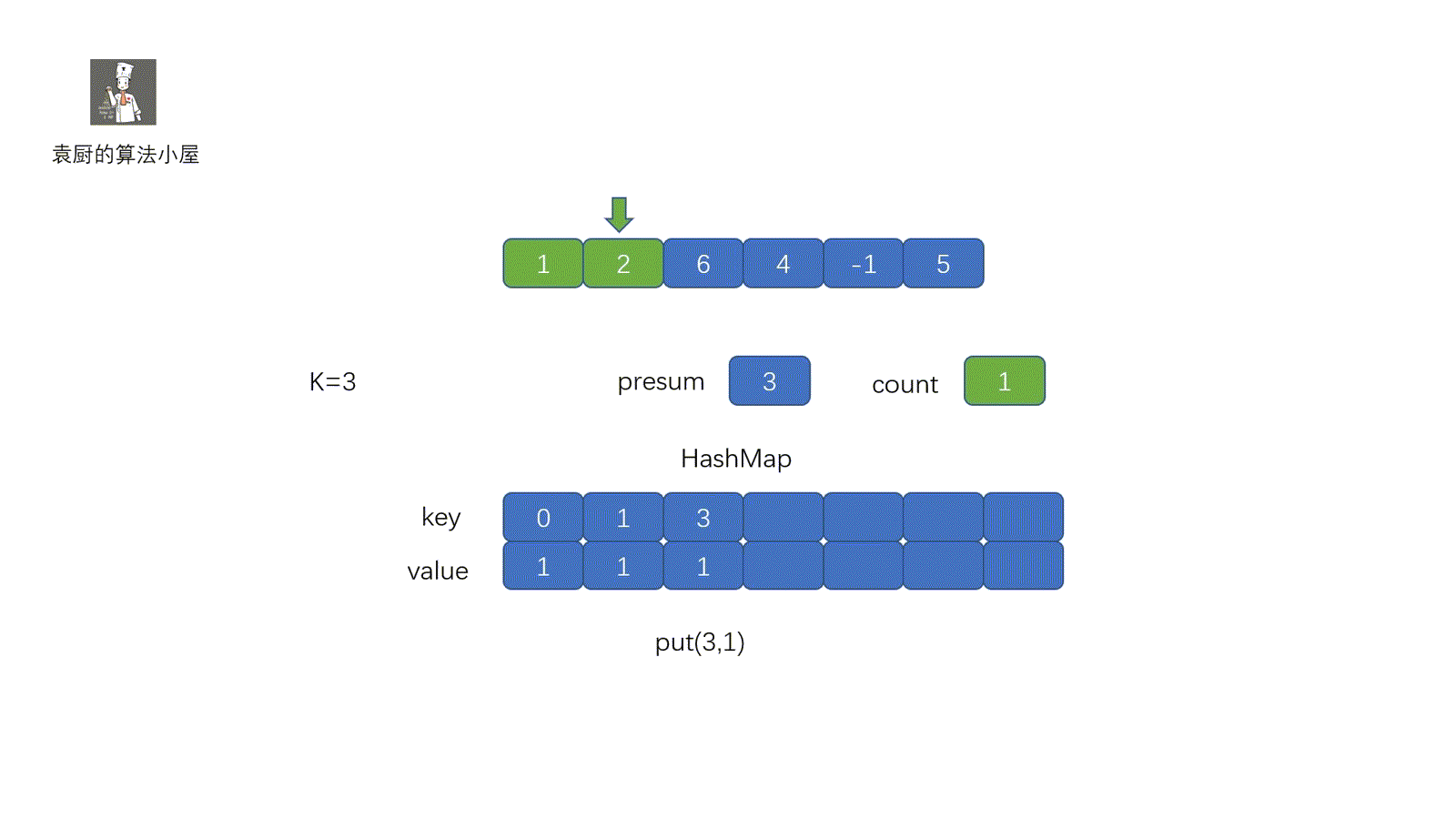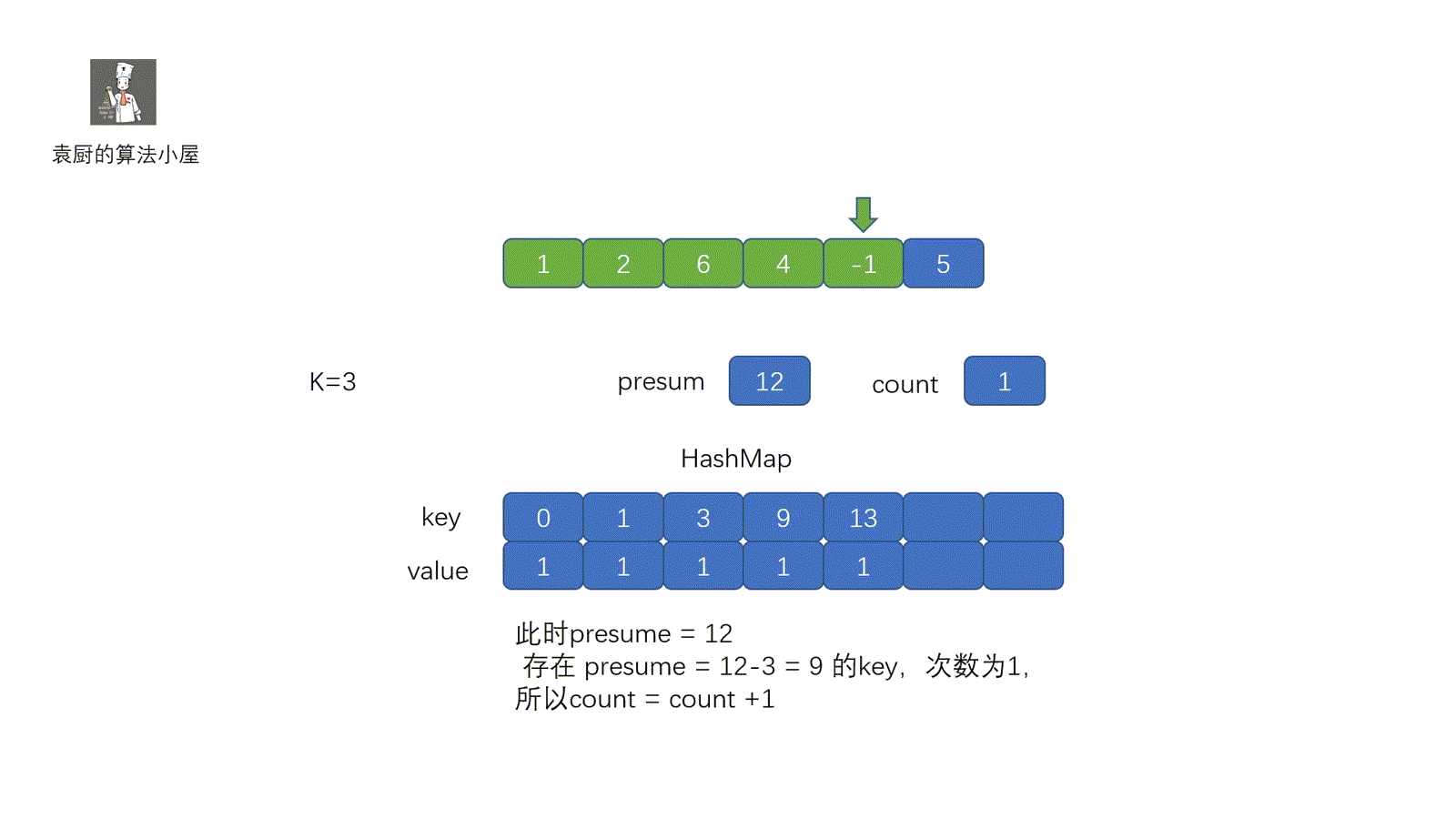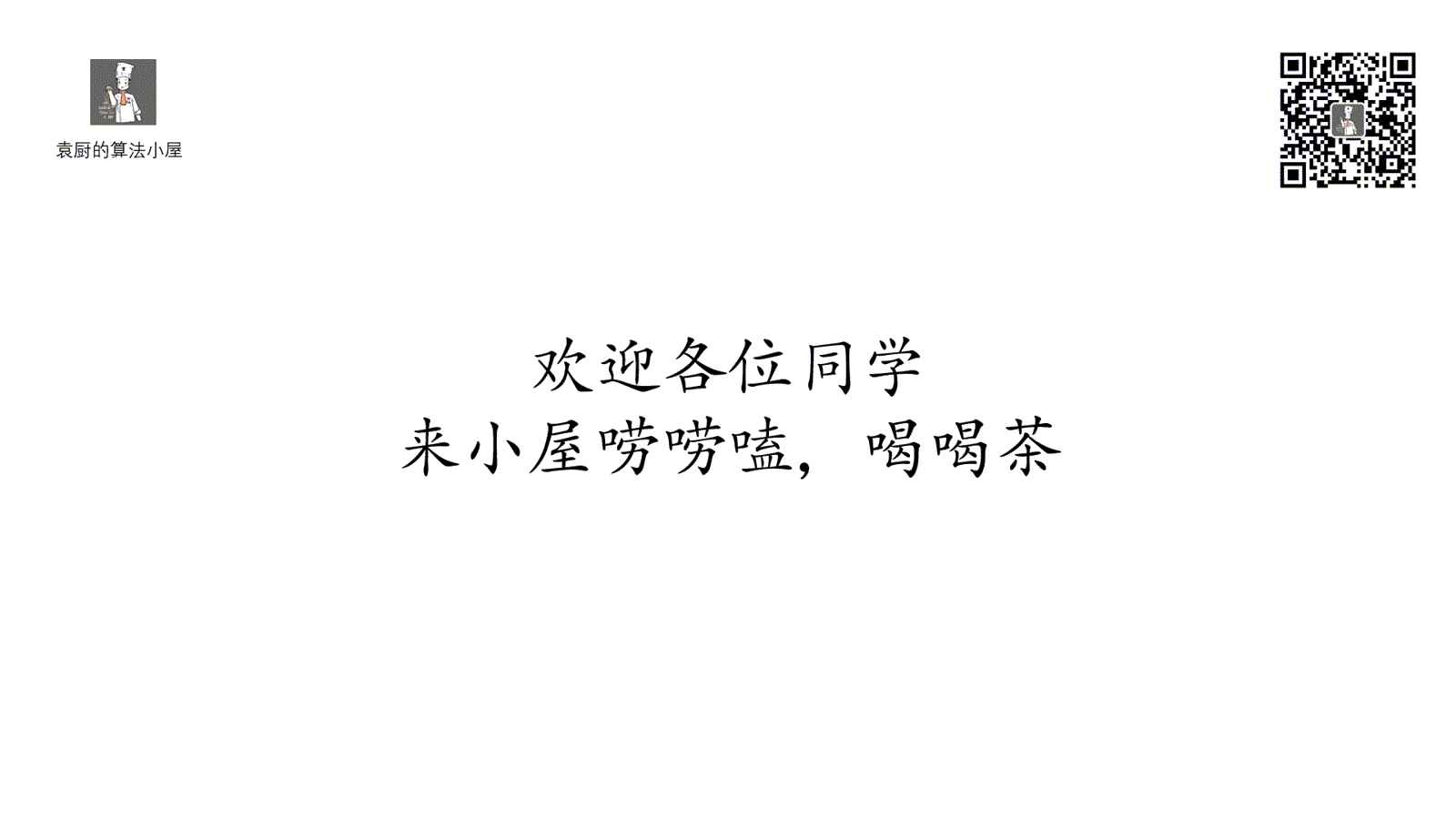
我们来拆解一下动图,可能有的同学会思考为什么我们只要查看是否含有 presum – k ,并获取到presum – k 出现的次数就行呢?见下图,所以我们完全可以通过 presum – k的个数获得 k 的个数

好啦我们来看一下代码吧
class Solution {
public int subarraySum(int[] nums, int k) {
if (nums.length == 0) {
return 0;
}
HashMap<Integer,Integer> map = new HashMap<>();
//细节,这里需要预存前缀和为 0 的情况,会漏掉前几位就满足的情况
//例如输入[1,1,0],k = 2 如果没有这行代码,则会返回0,漏掉了1+1=2,和1+1+0=2的情况
//输入:[3,1,1,0] k = 2时则不会漏掉
//因为presum[3] - presum[0]表示前面 3 位的和,所以需要map.put(0,1),垫下底
map.put(0, 1);
int count = 0;
int presum = 0;
for (int x : nums) {
presum += x;
//当前前缀和已知,判断是否含有 presum - k的前缀和,那么我们就知道某一区间的和为 k 了。
if (map.containsKey(presum - k)) {
count += map.get(presum - k);//获取次数
}
//更新
map.put(presum,map.getOrDefault(presum,0) + 1);
}
return count;
}
}
做完这个题目,各位也可以去完成一下这个题目,两个题目几乎完全相同 leetcode 930. 和相同的二元子数组
leetcode1248. 统计「优美子数组」
题目描述
给你一个整数数组 nums 和一个整数 k。
如果某个 连续 子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」。
请返回这个数组中「优美子数组」的数目。
示例 1:
输入:nums = [1,1,2,1,1], k = 3
输出:2
解释:包含 3 个奇数的子数组是 [1,1,2,1] 和 [1,2,1,1] 。
示例 2:
输入:nums = [2,4,6], k = 1
输出:0
解释:数列中不包含任何奇数,所以不存在优美子数组。
示例 3:
输入:nums = [2,2,2,1,2,2,1,2,2,2], k = 2
输出:16
如果上面那个题目我们完成了,这个题目做起来,分分钟的事,不信你去写一哈,百分百就整出来了,我们继续按上面的思想来解决。
HashMap
解析
上个题目我们是求和为 K 的子数组,这个题目是让我们求 恰好有 k 个奇数数字的连续子数组,这两个题几乎是一样的,上个题中我们将前缀区间的和保存到哈希表中,这个题目我们只需将前缀区间的奇数个数保存到区间内即可,只不过将 sum += x 改成了判断奇偶的语句,见下图。

我们来解析一下哈希表,key 代表的是含有 1 个奇数的前缀区间,value 代表这种子区间的个数,含有两个,也就是nums[0],nums[0,1].后面含义相同,那我们下面直接看代码吧,一下就能读懂。
class Solution {
public int numberOfSubarrays(int[] nums, int k) {
if (nums.length == 0) {
return 0;
}
HashMap<Integer,Integer> map = new HashMap<>();
//统计奇数个数,相当于我们的 presum
int oddnum = 0;
int count = 0;
map.put(0,1);
for (int x : nums) {
// 统计奇数个数
oddnum += x & 1;
// 发现存在,则 count增加
if (map.containsKey(oddnum - k)) {
count += map.get(oddnum - k);
}
//存入
map.put(oddnum,map.getOrDefault(oddnum,0)+1);
}
return count;
}
}
但是也有一点不同,就是我们是统计奇数的个数,数组中的奇数个数肯定不会超过原数组的长度,所以这个题目中我们可以用数组来模拟 HashMap ,用数组的索引来模拟 HashMap 的 key,用值来模拟哈希表的 value。下面我们直接看代码吧。
class Solution {
public int numberOfSubarrays(int[] nums, int k) {
int len = nums.length;
int[] map = new int[len + 1];
map[0] = 1;
int oddnum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
//如果是奇数则加一,偶数加0,相当于没加
oddnum += nums[i] & 1;
if (oddnum - k >= 0) {
count += map[oddnum-k];
}
map[oddnum]++;
}
return count;
}
}
leetcode 974 和可被 K 整除的子数组
题目描述
给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
示例:
输入:A = [4,5,0,-2,-3,1], K = 5
输出:7
解释:
有 7 个子数组满足其元素之和可被 K = 5 整除:
[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
前缀和+HashMap
解析
我们在该文的第一题 **和为K的子数组 **中,我们需要求出满足条件的区间,见下图
我们需要找到满足,和为 K 的区间。我们此时 presum 是已知的,k 也是已知的,我们只需要找到 presum – k区间的个数,就能得到 k 的区间个数。但是我们在当前题目中应该怎么做呢?见下图。

我们在之前的例子中说到,presum[j+1] – presum[i] 可以得到 nums[i] + nums[i+1]+…. nums[j],也就是[i,j]区间的和。
那么我们想要判断区间 [i,j] 的和是否能整除 K,也就是上图中紫色那一段是否能整除 K,那么我们只需判断
(presum[j+1] – presum[i] ) % k 是否等于 0 即可,
我们假设 (presum[j+1] – presum[i] ) % k == 0;则
presum[j+1] % k – presum[i] % k == 0;
presum[j +1] % k = presum[i] % k ;
我们 presum[j +1] % k 的值 key 是已知的,则是当前的 presum 和 k 的关系,我们只需要知道之前的前缀区间里含有相同余数 (key)的个数。则能够知道当前能够整除 K 的区间个数。见下图

题目代码
class Solution {
public int subarraysDivByK(int[] A, int K) {
HashMap<Integer,Integer> map = new HashMap<>();
map.put(0,1);
int presum = 0;
int count = 0;
for (int x : A) {
presum += x;
//当前 presum 与 K的关系,余数是几,当被除数为负数时取模结果为负数,需要纠正
int key = (presum % K + K) % K;
//查询哈希表获取之前key也就是余数的次数
if (map.containsKey(key)) {
count += map.get(key);
}
//存入哈希表当前key,也就是余数
map.put(key,map.getOrDefault(key,0)+1);
}
return count;
}
}
我们看到上面代码中有一段代码是这样的
int key = (presum % K + K) % K;
这是为什么呢?不能直接用 presum % k 吗?
这是因为当我们 presum 为负数时,需要对其纠正。纠正前(-1) %2 = (-1),纠正之后 ( (-1) % 2 + 2) % 2=1 保存在哈希表中的则为 1.则不会漏掉部分情况,例如输入为 [-1,2,9],K = 2如果不对其纠正则会漏掉区间 [2] 此时 2 % 2 = 0,符合条件,但是不会被计数。
那么这个题目我们可不可以用数组,代替 map 呢?当然也是可以的,因为此时我们的哈希表存的是余数,余数最大也只不过是 K-1所以我们可以用固定长度 K 的数组来模拟哈希表。
class Solution {
public int subarraysDivByK(int[] A, int K) {
int[] map = new int[K];
map[0] = 1;
int len = A.length;
int presum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
presum += A[i];
//求key
int key = (presum % K + K) % K;
//count添加次数,并将当前的map[key]++;
count += map[key]++;
}
return count;
}
}
leetcode 523 连续的子数组和
题目描述
给定一个包含 非负数 的数组和一个目标 整数 k,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,且总和为 k 的倍数,即总和为 n*k,其中 n 也是一个整数。
示例 1:
输入:[23,2,4,6,7], k = 6
输出:True
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6。
示例 2:
输入:[23,2,6,4,7], k = 6
输出:True
解释:[23,2,6,4,7]是大小为 5 的子数组,并且和为 42。
前缀和 + HashMap
这个题目算是对刚才那个题目的升级,前半部分是一样的,都是为了让你找到能被 K 整除的子数组,但是这里加了一个限制,那就是子数组的大小至少为 2,那么我们应该怎么判断子数组的长度呢?我们可以根据索引来进行判断,见下图。

此时我们 K = 6, presum % 6 = 4 也找到了相同余数的前缀子数组 [0,1] 但是我们此时指针指向为 2,我们的前缀子区间 [0,1]的下界为1,所以 2 – 1 = 1,但我们的中间区间的长度小于2,所以不能返回 true,需要继续遍历,那我们有两个区间[0,1],[0,2]都满足 presum % 6 = 4,那我们哈希表中保存的下标应该是 1 还是 2 呢?我们保存的是1,如果我们保存的是较大的那个索引,则会出现下列情况,见下图。

此时,仍会显示不满足子区间长度至少为 2 的情况,仍会继续遍历,但是我们此时的 [2,3]区间已经满足该情况,返回 true,所以我们往哈希表存值时,只存一次,即最小的索引即可。下面我们看一下该题的两个细节
细节1:我们的 k 如果为 0 时怎么办,因为 0 不可以做除数。所以当我们 k 为 0 时可以直接存到数组里,例如输入为 [0,0] , K = 0 的情况
细节2:另外一个就是之前我们都是统计个数,value 里保存的是次数,但是此时我们加了一个条件就是长度至少为 2,保存的是索引,所以我们不能继续 map.put(0,1),应该赋初值为 map.put(0,-1)。这样才不会漏掉一些情况,例如我们的数组为[2,3,4],k = 1,当我们 map.put(0,-1) 时,当我们遍历到 nums[1] 即 3 时,则可以返回 true,因为 1-(-1)= 2,5 % 1=0 , 同时满足。
视频解析

题目代码
class Solution {
public boolean checkSubarraySum(int[] nums, int k) {
HashMap<Integer,Integer> map = new HashMap<>();
//细节2
map.put(0,-1);
int presum = 0;
for (int i = 0; i < nums.length; ++i) {
presum += nums[i];
//细节1,防止 k 为 0 的情况
int key = k == 0 ? presum : presum % k;
if (map.containsKey(key)) {
if (i - map.get(key) >= 2) {
return true;
}
//因为我们需要保存最小索引,当已经存在时则不用再次存入,不然会更新索引值
continue;
}
map.put(key,i);
}
return false;
}
}
好啦,前缀和能写的都在这了,看完妥妥的搞定这些题目,很简单,而且还会有自己的解题思维,遇到类似题目一点不慌。
另外我们新建了一个刷题打卡小队,每天用小程序打卡,互相监督,群内还有几位大佬进行指导讲解,个人认为还不错。需要的可以看我简介,
另外还联合几位老哥整理了一份经典必刷题,题目大纲,需要的可以看我的个人简介,在小屋内点击刷题大纲查看。