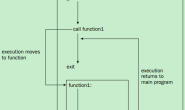
(1)构造函数、析构函数与赋值函数
构造函数、析构函数与赋值函数是每个类最基本的函数。它们太普通以致让人容易麻痹大意,
其实这些貌似简单的函数就象没有顶盖的下水道那样危险。
每个类只有一个析构函数和一个赋值函数,但可以有多个构造函数(包含一个拷贝构造函数,其它的称为普通构造函数)。对于任意一个类A,如果不想编写上述函数,C++编译器将自动为A 产生四个缺省的函数,例如:
A(void); // 缺省的无参数构造函数
A(const A &a); // 缺省的拷贝构造函数
~A(void); // 缺省的析构函数
A & operate =(const A &a); // 缺省的赋值函数
这不禁让人疑惑,既然能自动生成函数,为什么还要程序员编写?原因如下:
<1>如果使用“缺省的无参数构造函数”和“缺省的析构函数”,等于放弃了自主“初始化”和“清除”的机会,C++发明人Stroustrup 的好心好意白费了。
<2>“缺省的拷贝构造函数”和“缺省的赋值函数”均采用“位拷贝”而非“值拷贝”的方式来实现,倘若类中含有指针变量,这两个函数注定将出错。
对于那些没有吃够苦头的C++程序员,如果他说编写构造函数、析构函数与赋值函数很容易,可以不用动脑筋,表明他的认识还比较肤浅,水平有待于提高。
下面以类String 的设计与实现为例,深入阐述被很多教科书忽视了的道理。String的结构如下:
class String
{
public:
String(const char *str = NULL); // 普通构造函数
String(const String &other); // 拷贝构造函数
~ String(void); // 析构函数
String & operate =(const String &other); // 赋值函数
private:
char *m_data; // 用于保存字符串
};
(2)构造函数是一种特殊的成员函数,无返回值,函数名与类同名。它提供了对成员变量进行初始化的方法,使得在声明对象时能自动地初始化对象。因为当程序创建一个对象时,系统会自动调用该对象所属类的构造函数。
例一:class Student
{
Student()//默认无参无赋值操作构造函数
{
}
}
Student stu;//声明对象
以上代码中的无参无操作构造函数即为系统自动提供一个默认的构造函数,该默认构造函数没有参数,它仅仅负责创建对象而不做任何赋值操作。
例二:class Student
{
Student()//无参带赋值操作构造函数
{
memberVariable1=constValue1;
memberVariable2=constValue2;
}
}
Student stu;//声明对象
以上代码中,在默认构造函数添加赋值初始化操作,该构造函数将覆盖默认构造函数。该构造函数没有参数,它不仅负责创建对象而还负责成员变量的状态初始化。
例三:class Student
{
Student(type1 value1,type2 value2) //含参带赋值操作构造函数
{
memberVariable1=value1;
memberVariable2=value2;
}
}
Student stu(value1,value2);//声明对象
以上代码中,在默认构造函数中添加参数和赋值初始化操作,该构造函数将覆盖默认构造函数。该构造函数没有参数,它不仅负责创建对象而还负责传值对成员变量进行状态初始化。
一旦类中有了一个带参数的构造函数而又没无参数构造函数的时候系统将无法创建不带参数的对象,此时以下三种声明都是错误的:
Student stu;
Student *stu = new Student;
Student *stu = new Student();
例四:class Student
{
Student()
{
}
/*Student()
{
memberVariable1=constValue1;
memberVariable2=constValue2;
}*/
Student(type1 value1,type2 value2)
{
memberVariable1=value1;
memberVariable2=value2;
}
};
Student stu; // 声明对象—栈对象
Student *stu; // 类指针变量—栈对象
Student *stu = new Student; // çèStudent *stu = new Student();—堆对象
Student stu(value1,value2); // 声明对象—栈对象
Student *stu = new Student(value1,value2); // 声明对象—堆对象
以上代码中,既有无参(默认)构造函数,又有含参和赋值操作的构造函数;既可声明无参对象,也可声明含参初始化对象。注意new是在堆上动态创建的。
由于构造函数和普通函数一样具有重载特性所以编写程序的人可以给一个类添加任意多个构造函数,来使用不同的参数来进行初始化对象!
类一旦定义就可以当作一种新的数据类型,可作为另一个类的数据成员,即类可以嵌套定义。
类是一个抽象的概念,并不是一个实体,并不能包含属性值(这里来说也就是构造函数的参数了),只有对象才占有一定的内存空间,含有明确的属性值!
一个类可能需要在构造函数内动态分配资源,那么这些动态开辟的资源就需要在对象不复存在之前被销毁掉,那么c++类的析构函数就提供了这个方便。
(3)构造函数的初始化表
构造函数有个特殊的初始化方式叫“初始化表达式表”(简称初始化表)。初始化表位于函数参数表之后,却在函数体 {} 之前。这说明该表里的初始化工作发生在函数体内的任何代码被执行之前。
构造函数初始化表的使用规则:
<1> 如果类存在继承关系,派生类必须在其初始化表里调用基类的构造函数。例如:
class A
{ …
A(int x); // A 的构造函数
};
class B : public A
{ …
B(int x, int y);// B 的构造函数
};
B::B(int x, int y): A(x) // 在初始化表里调用A 的构造函数
{ …
}
<2>类的 const 常量只能在初始化表里被初始化,因为它不能在函数体内用赋值的方式来初始化。
<3>类的数据成员的初始化可以采用初始化表或函数体内赋值两种方式,这两种方式的效率不完全相同。
[1]非内部数据类型的成员对象应当采用第一种方式初始化,以获取更高的效率。例如:
class A
{ …
A(void); // 无参数构造函数
A(const A &other); // 拷贝构造函数
A & operate =( const A &other); // 赋值函数
};
class B
{
public:
B(const A &a); // B 的构造函数
private:
A m_a; // 成员对象
};
示例 9-2(a)中,类B 的构造函数在其初始化表里调用了类A的拷贝构造函数,从而将成员对象m_a 初始化。
示例 9-2 (b)中,类B 的构造函数在函数体内用赋值的方式将成员对象m_a 初始化。我们看到的只是一条赋值语句,但实际上B 的构造函数干了两件事:先暗地里创建m_a对象(调用了A 的无参数构造函数),再调用类A 的赋值函数,将参数a 赋给m_a。
示例 9-2(a) 成员对象在初始化表中被初始化:
B::B(const A &a) : m_a(a)
{
…
}
示例9-2(b) 成员对象在函数体内被初始化:
B::B(const A &a)
{
m_a = a;
…
}
[2]对于内部数据类型的数据成员而言,两种初始化方式的效率几乎没有区别,但后者的程序版式似乎更清晰些。若类F的声明如下:
class F
{
public:
F(int x, int y); // 构造函数
private:
int m_x, m_y;
int m_i, m_j;
}
示例9-2(c)中F 的构造函数采用了第一种初始化方式,示例9-2(d)中F 的构造函数采用了第二种初始化方式。
示例 9-2(c) 数据成员在初始化表中被初始化:
F::F(int x, int y) : m_x(x), m_y(y)
{
m_i = 0;
m_j = 0;
}
示例9-2(d) 数据成员在函数体内被初始化:
F::F(int x, int y)
{
m_x = x;
m_y = y;
m_i = 0;
m_j = 0;
}
(4)拷贝构造函数和赋值函数的区别
拷贝构造函数和赋值函数非常容易混淆,常导致错写、错用。拷贝构造函数是在对象被创建时调用的,而赋值函数只能被已经存在了的对象调用。以下程序中,第三个语句和第四个语句很相似,你分得清楚哪个调用了拷贝构造函数,哪个调用了赋值函数吗?
String a(“hello”);
String b(“world”);
String c = a; // 调用了拷贝构造函数,最好写成c(a);
c = b; // 调用了赋值函数
(5)析构函数也是特殊的类成员函数,它没有返回类型,没有参数,不能随意调用,也没有重载,只有在类对象的生命期结束的时候,由系统自动调用,用来在系统释放对象前做一些清理工作,如利用delete运算符释放临时分配的内存、清零某些内存单元等。
定义析构函数因使用“~”符号加类名(逻辑非运算符),表示它为逆构造函数,它不能带任何参数。
参考:
《C和指针》
《高质量C++编程指南》 林锐