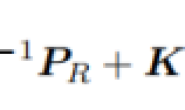Real-Time Loop Closure in 2D LIDAR SLAM文章精读
原文:W. Hess, D. Kohler, H. Rapp, and D. Andor, Real-Time Loop Closure in 2D LIDAR SLAM, in Robotics and Automation (ICRA), 2016 IEEE International Conference on.IEEE, 2016. pp. 1271–1278.
cartographer的原文,发在机器人顶会ICRA2016上
本文将按照文章的顺序,一段一段的进行详细解释,给出我的阅读结论
注意!这篇文章我写的太详细了,以工程为目的请直接看我的其他文章,或者请阅读红字
Abstract(摘要)
使用便携式激光测距仪(又称Lidar)和SLAM(simultaneous localization and mapping)是获取建筑平面图的有效方法。实时生成和可视化楼层平面图有助于操作员评估捕获数据的质量和覆盖范围。而这种便携式的平台计算资源是有限的。而作者现在要介绍了他们使用的方法,他们的建图平台是装着lidar的背包,实现实时建图和5cm的分辨率,主要方法是通过计算scan-to-submap匹配作为约束
Introduction(简介)
现在的方法哪不好:
建筑平面图对各种应用都很有用,现在的方法都是用激光、卷尺来测量,或者结合CAD图。效率低,依赖于测量人员的水平,不一定准确
用SLAM哪好:
使用SLAM,可以快速准确测量建筑物的大小,复杂程度比手动测量要少花几个数量级的时间。SLAM
cartographer的贡献:
论文的主要贡献是,在利用大量雷达数据计算闭合约束时,一种减少计算量的新方法。这让cartographer能够绘制楼层非常大的地图,能达到成千上万平方米
Related work(相关工作)
暂不介绍,有兴趣可以自己阅读
System overview(系统总览)
google的cartographer提供的是实时室内地图构建的解决方案,形式是背包里面装着传感器,生成的是分辨率为5cm的2D网格地图。当操作人员绕着建筑走时,地图就在一点点绘制了。
每帧雷达数据采用一个最佳估计位置加入子图中(submap),当然了这假设雷达在短时间内的数据是精确的。这个最佳估计位姿靠的是雷达匹配(Scan Matching),来自于这一帧雷达与当前子图的匹配结果。因此估计位姿的误差取决于当前雷达数据和累计误差
为了不吃硬件资源还能达到好的结果,cartographer方法没有采用粒子滤波器(缺点:需要大量数据,计算复杂度高)。为了消除累计误差,cartographer的做法是不断pose
optimization(位姿优化)
理解重点!!!一句句的翻译,你肯定有不太明白的地方和细节,请继续看下一节
- Scan matching的时候,当一个子图完成时,新的雷达数据就不加到这个子图中了
- 所有完成的子图和雷达数据都会用于回环闭合
- 如果当前的位姿估计距离子图位姿足够接近,Scan matcher(扫描匹配器)会尝试在子图中找到匹配的Scan。
- 如果在当前估计位姿周围的搜索窗口中找到足够好的匹配,则将其作为 loop closing constraint(回环闭合约束) 添加到优化问题中优化每几秒发生一次,作者发现一旦重新经过
- 相同的地方,回环就立刻闭合了。在轻实时(没那么严格)的约束条件下,闭环扫描匹配的速度要快于新Scan的加入速度,要不然就有问题了
- 作者采用的方法是“branch-and-bound”(分支绑定)
Local 2D SLAM
Cartographer中的Local SLAM,一帧帧Scan变成若干个Submap的过程
cartographer结合了 local SLAM 和 global SLAM,两个SLAM过程都需要优化的就是位姿,也就是雷达观测数据的(x,y,θ),这些位姿被称为 scans(因为是2D,所以x和y是
平移,θ是旋转角)。作者把雷达装在背包上,所以他们的平台是不稳的(晃晃悠悠的意思)。他们因此在背包上装了一个IMU(Inertial measurement unit, 惯性测量单元)。
IMU会给出重力方向,用于把雷达数据投影到2D平面(就是告诉你雷达的姿态,有了姿态你就能知道雷达究竟扫描的是3D世界的哪个平面,再将雷达数据变为投影数据就是了)。
在Local SLAM中,每一帧扫描结果都会匹配世界的一小块区域,世界的这些一小块一小块的区域称为Submap(子图)。
使用非线性优化将 Scan 与 Submap 对齐,这个过程进一步称为Scan Matching(扫描匹配)。Scan Matching 会随着时间存在累计误差,Global SLAM 会消除这些误差。
A. Scans
Local SLAM第一部分,拿到了每帧雷达数据(一堆(x,y)点),是依靠变换矩阵T将Scan的点变换到Submap下的
Submap的构建就是将Scan不断与Submap的坐标系对齐的迭代过程。
假设Submap的坐标系原点是0 ∈ R 2 ,每一个雷达扫描点为p ,那么这一帧雷达的数据为H = { h k } k = 1 , . . . K , h k ∈ R 2
当前雷达帧在Submap坐标系下的位姿为T ξ,用下面的公式就可以把Scan的扫描点转到Submap坐标系下

B. Submaps
Local SLAM第二部分,submap是概率网格地图,地图每个点都是该点是否被占用的概率值,通过计算Hit点集合Miss点集以及公式更新每个点的值
连续的几帧Scan会组成一个Submap,Submap实际是一个概率网格地图 M : r Z × r Z → [ p m i n , p m a x ]

r 是网格地图的分辨率,比如说5cm。每一个格子的值代表当前网格被堵住(有东西)的概率。对于每个网格点,我们定义该网格的像素由最接近该网格点的所有点“影响”的。
(注意:我用的是“影响”一词,因为概率地图的像素是概率值,在格子中的点不能组成概率值,只能影响这个概率值)
每一次Scan插入到Submap(也可以认为是现在说的这个概率地图)的时候,我们都要确定hits(命中)的点和misses(未命中)的点集。命中就是网格里有雷达数据点,未命中
就是没雷达数据点。
每一个Hit的点(下图阴影且画×的),对应的格子点加入到 Hit set (命中点)集中
每一个Miss的点(下图阴影),雷达原点到扫描点中间的点全部加到 Miss set(未命中点集)中,如果这个点已经在命中点集中则不处理

每个还未观察到的网格,可以自定义赋值为一个p m i s s 或者p h i t 值(一般用0.5,即不知道这个格子有没有被占用)。已经观察到的网格,它的赔率(命中比上未命中的概
率)odds更新为(odds可以理解为发生和不发生的比例,用它来描述概率)

每个网格的命中概率更新公式为

未命中概率的更新公式就是,将上式中的p h i t 替换成p m i s s 其中,clamp():将数字限制在一个范围[min, max]内,用在这可以理解为将结果限制在[0, 1]之间,论文里没有提到p pp是如何计算的,我理解应该为 这个格子出现扫描点的次数/Submap总的scan数, 这一解释极大概率是正确的
C. Ceres scan matching
Local SLAM第三部分,新的Scan是通过变换矩阵T插入到Submap中。变换矩阵T是经过IMU的初值,并通过最小二乘法求出的
一帧Scan插入Submap之前,首先要对这帧Scan的位姿进行优化。作者使用的是基于Ceres库的Scan matcher。Scan Matcher的目标就是寻找一个最优位姿,这个位姿能让Scan中的点最大概率地匹配到Submap上。
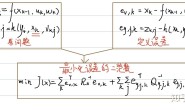
优化问题被看成了一个非线性最小二乘问题

式子中的变换矩阵 T ξ 能把所有的Scan点 h k ,从Scan坐标系下变换到Submap坐标系下。函数M s m o o t h 实现R 2 → R ,使点变为Submap中概率值的平滑形式,作者的M函数用的是双三次差值。我的理解:函数M s m o o t h 实际上就是把每个Submap中的雷达点,变成了是否在Submap中的概率值,每个雷达点通过变换和函数M后如果都能趋近于1,意味着新的这帧Scan很好的匹配了Submap,这也是此优化函数的目的,最小化公式的结果就是令求和号里的每一项都尽量趋近于1
此函数是一个局部优化,因此需要初值。IMU可以测量角速度,从而提供变换 T ξ 初值。即使没有IMU,提高Scan matcher的频率或者提高像素的分辨率也能结果很好,这样的缺点也就是计算量大点,无妨。
Closing loops
Cartographer中的Global SLAM,Submap之间存在累计误差,那么这些Submap如何形成一整张地图,靠的是回环检测和全局优化
由于Scans仅与Submap中最近的一些Scan进行匹配,会有累计误差。 如果对于仅几十个连续的Scans,累积误差很小。 但子图多了累计误差就有影响了。累计误差不可避免,且解决累计误差十分重要
作者的方法是优化所有Scan和Submap的位姿,遵循稀疏姿态调整。 Scan插入时的相对姿态(相对于Submap的)存储在内存中,用于闭环优化。 除了这些相对姿态外,一Submap不再更改了,则将考虑由Scan和Submap组成的对进行循环闭合。Scan Matcher在后台运行,如果找到匹配的对象,则将对应的相对姿态添加到优化问题中。
每一个scan在cartographer程序中被写成一个node,每一个node(也就是每一帧Scan)将和一个submap存在一个位姿变换。submap可以是自己所处的submap,也可以是其他submap。能够建立constraint的位姿将被优化
A. Optimization problem
闭合优化问题也是一个非线性最小二乘问题

submap的pose是:

scan 的pose是

这些被优化的submap位姿和Scan位姿给出了一些constraint(约束)。constraint的表现形式就是位姿 ξ i j 和协方差矩阵 ∑ i j 。位姿 ξ i j 代表 j 帧Scan 在 Submap i 下的位姿。
协方差矩阵 ∑ i j 可以被估计,残差 E EE 的计算公式是

当Scan matcher 将不正确的constraint添加到优化问题时,损失函数ρ (例如Huber损失),可以用于减少异常值的影响,而异常值可能会出现在局部对称的环境(包含隔间的办
公室)中。
B. Branch-and-bound scan matching
分支界定的scan matching,给出当前帧scan对应Submap的最优位姿 ξ
核心公式如下

使用变换 T ξ 将scan的全部点 h k 变换到Submap下,W 是位姿 ξ 的搜索窗口,M n e a r e s t 代表 todo
这个搜索效率是由搜索步长决定的。平移量 x xx 和 y yy 的搜索步长设置为了地图分辨率 r rr ,角度搜索步长的设置如下:
d m a x 代表scan所有点中,距离原点最远的点,到原点的距离(当前scan所有点中最大的range)。第二个公式是根据余弦定理得到的,余弦定理:

现在令其中两条边为 d m a x ,另一条边为 r , 代入余弦定理可得角度搜索步长为

搜索宽度 W x = W y = 7 m , W θ = 30 º

那么搜索窗口中的可能性一共是多少种如下

搜索窗口表示如下

整体 Branch-and-bound scan matching 算法如下:

嗯,这是三个for循环,一看就是一个遍历求解。这样计算太复杂了,这时作者说了,窗口大的我们不用这个算法了。请看算法2

作者使用的是分支定界方法。核心思想就是将可能性的子集表示为树中的节点,其中根节点表示所有可能的解,也就是搜索窗口W WW。每个叶子节点代表一个可能的解,全部
叶子节点也就代表了全部的解。
算法分为三个部分:节点选择,分支规则,计算上限
1. 节点选择:采用 “深度优先搜索”(DFS) 算法
算法的效率依赖于两件事:好的上限和好的当前解。 由于我们不想添加差的匹配项作为constraint,因此我们引入了Score阈值,不采纳低于该阈值的解。 由于在实践中通常不会超过这个阈值,这降低了节点选择或寻找初值解的重要性。
关于DFS算法访问子节点的顺序,我们计算每个子节点的分数上限,先访问“最有前途”的子节点,其上限最大。 详见算法3。

2. 分支规则
树中的每个节点是一组整数,c = ( c x , c y , c θ , c h ) ∈ Z 4 。高度为c h 的节点可以表示2 c h × 2 c h 全部可能的平移
很好理解,简单来说就是用另一种方式定义了搜索时的步长。每个参数的含义如下:

一个高度为c h ( c h > 1 ) 的节点,可以分成高度为c h − 1 的四个子节点

3. 计算上限
分支界定算法另外一个部分就是计算内节点的上限了

为了能够有效地计算上式中的最大值,我们使用了预先计算好的网格M p r e c o m p c h 。对每个可能的高度c h 预先计算一个网格,使我们能够以Score与Scan点的数量所成的线性关系,来计算Score。请注意,为了能够做到这一点,我们还计算了W c ‾ ‾ 上的最大值,该最大值大于我们搜索空间边界附近的W c ‾ 。

请注意,M p r e c o m p c h 具有与M n e a r e s t 相同的像素结构,但是在每个像素存储2 h × 2 h 像素框的最大值

为了使构建预计算网格的计算量保持较低,我们等到概率网格不再更新,然后才计算出一组预先计算的网格,并开始对其进行匹配。
对于每个预先计算的网格,我们从每个像素开始,计算2 h 像素宽的行中的最大值。 使用该中间结果,然后构造下一个预计算网格。
Experimental Results
这一章是实验结果和分析
A. Real-World Experiment: Deutsches Museum
德意志博物馆收集的数据,跨度为1,913 s和2,253 m。
CPU:3.2 GHz Intel Xeon E5-1650,SLAM算法使用1,018 s CPU时间,使用最多2.2 GB的内存和最多4个后台线程进行闭环扫描匹配。 它在360 s完成,这意味着它达到了5.3倍的实时性能。 生成的用于闭环优化的图形由11,456个节点和35,300个边组成。 每当将几个节点添加到图中时,都会运行优化问题(SPA)。 典型的解决方案需要进行大约3次迭代,并在大约0.3 s内完成。

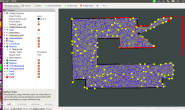
以上是cartographer对德国博物馆二层构建的地图
B. Real-World Experiment: Neato’s Revo LDS
Neato Robotics(一个扫地机器人公司)在其扫地机器人中使用了称为Revo LDS 的激光距离传感器,其价格不到30美元。我们通过在手推车上推着扫地机器人,并以大约2 Hz
的频率进行扫描来捕获数据。 扫描图如下

为了评估平面图的质量,我们将5条直线的激光尺测量结果,与绘图工具计算出的结果图中的像素距离,进行了比较。 结果列于下表,所有值均以米为单位

C. Comparisons using the Radish data set
cartographer在不同的数据集上,与Graph Mapping(GM)和Graph FLIRT进行了对比。所有误差均以米和度(绝对值或平方值)以及其标准偏差给出。

结论是:
cartographer在不同环境下,调整参数和传感器配置,就能work
大部分数据集,cartographer表现更优
本来就想写这一篇分析的,但写的时候我就发现我对文章分析得太细了,我会再写一篇简要的分析,在那一篇中我会简明的缕清算法脉络