.
业务背景:接一个征信公司的api,然后快速解析,批量入库的操作!记录一下流水账,主要是记录关于Statement执行批处理操作,sql后边不允许加”;”的异常 !!!
目录
梳理
1.Jdbc连接池代码 :
2. jdbc url 配置
4.结论
5.总结
梳理
1. api 返回的是 json 串;
2.快速解析json,生成建表语句,并且批量插入(个别接口,返回解析,拼装后的sql语句达到:5w+)
3.使用DruidDataSource 构建jdbc连接池,使用 Statement 的批处理操作.
执行:
1.Jdbc连接池代码 :
private Logger logger = LoggerFactory.getLogger(getClass().getName());
/**
* 数据库集合.
*/
final ConcurrentHashMap<String, DataSource> dataSourceMap = new ConcurrentHashMap();
/**
* 初始化池子
* @param destDbInfo
*/
public boolean initPool(DestDbInfo destDbInfo){
try {
//通过直接创建连接池对象的方式创建连接池对象
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUsername(destDbInfo.getUsername());
druidDataSource.setPassword(destDbInfo.getPassword());
druidDataSource.setUrl(destDbInfo.getUrl());
druidDataSource.setDriverClassName(destDbInfo.getDriver());
druidDataSource.setMinIdle(10);
druidDataSource.setMaxActive(300);
DataSource druidPool = druidDataSource;
String key = JsonUtils.bean2JsonStr(destDbInfo);
dataSourceMap.put(key,druidPool);
return true;
}catch (Exception e){
e.printStackTrace();
}
return false;
}
/**
* 得到数据库连接
*/
public Connection getConn(DestDbInfo destDbInfo){
if (destDbInfo==null){
logger.error("传递的对象为空!");
return null;
}
String key = JsonUtils.bean2JsonStr(destDbInfo);
DataSource druidPool = dataSourceMap.get(key);
try {
if (druidPool!=null){
return druidPool.getConnection();
}
}catch (Exception e){
e.printStackTrace();
}
return null;
}
/**
* 执行入库操作.
* @param destDbInfo
* @param sqls
* @return
*/
public boolean executeSql(DestDbInfo destDbInfo,List<String> sqls) throws SQLException {
if (sqls.isEmpty()){
return false;
}
Connection connection = getConn(destDbInfo);
Statement statement = connection.createStatement();
int count = sqls.size();
for (int i = 0; i < count ; i++) {
System.out.println(sqls.get(i));
statement.addBatch(sqls.get(i));
if (i>0 && i % 10000 ==0){
statement.executeBatch();
statement.clearBatch();
}
}
int[] nums = statement.executeBatch();
System.out.println("执行成功的条数是:"+nums);
statement.clearBatch();
statement.close();
connection.close();
return true;
}
/**
* 执行单条件语句
* @param destDbInfo
* @param sql
* @return
* @throws SQLException
*/
public boolean executeSql(DestDbInfo destDbInfo,String sql) throws SQLException {
if (StringUtils.isBlank(sql)){
return false;
}
Connection connection = getConn(destDbInfo);
PreparedStatement statement = connection.prepareStatement(sql);
int count = statement.executeUpdate();
statement.close();
connection.close();
return count>0 ? true : false;
}
/**
* 使用PreparedStatement查询数据
* @param destDbInfo
* @param sql
* @return 结果集 不要关闭连接
*/
public Integer selectSql(DestDbInfo destDbInfo,String sql){
try {
Connection connection = getConn(destDbInfo);
PreparedStatement pstmt=connection.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
Integer value =null;
while (rs.next()){
value=rs.getInt(1);
}
rs.close();
pstmt.close();
connection.close();
return value;
} catch (SQLException e1) {
logger.error(e1.getMessage());
}
return null;
}
2. jdbc url 配置
jdbc:mysql://192.168.10.186:3306/data_sync?autoReconnect=true&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=utf-8&useSSL=false
mysql中,如果不加上rewriteBatchedStatements=true,你的批处理是假的批处理,只是写了批处理,但是jdbc去执行的时候,却不是按照批处理来执行的。
3. 执行异常,要执行的 sql 如:
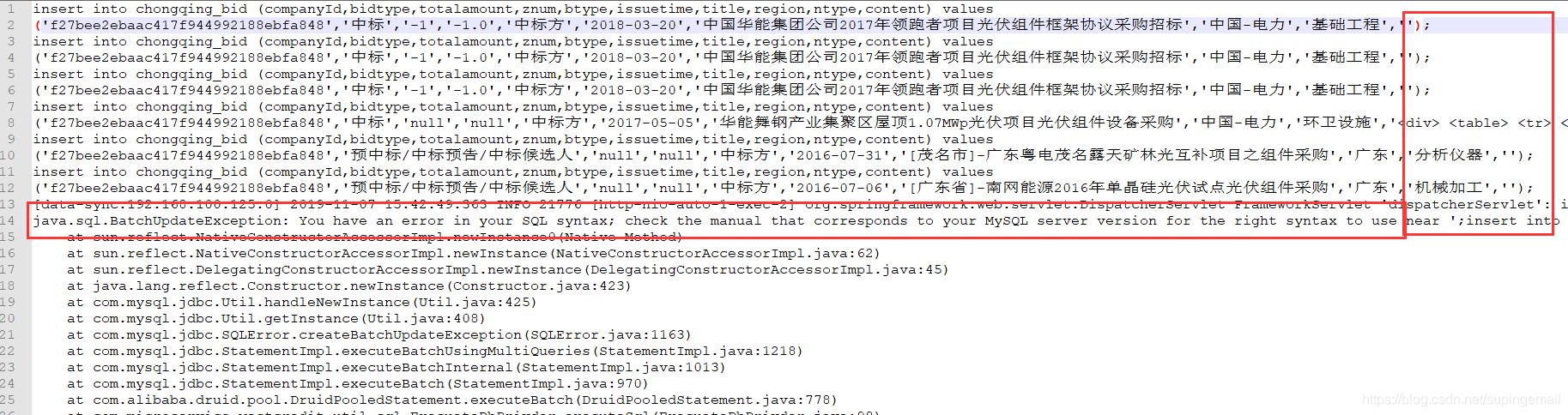

可以看见,所有的sql后边都是加上”;”的,这就会报上面的错误,让人哭笑不得、因为在oracle中,sql语句后边要是不加”;”,那执行是要报错的。
4.结论
哎,真的是一个坑爹的潜藏的异常信息,一般人谁会想到:正常的sql都会写”;”,可是在mysql的批处理上,就会报错,而且这种错误很难定位的到是因为分号的问题。
5.总结
使用rewriteBatchedStatements 是有限制的,即为执行的总条数>3,如果小于这个数,那么还是走的是逐条执行!真的是坑!!!


![[原创] MYSQL 事务隔离级别实验](https://blog.75271.com/wp-content/themes/com75271/timthumb.php?src=https://blog.75271.com/wp-content/themes/com75271/css/img/pic/4.jpg&h=110&w=185&q=90&zc=1&ct=1)
