.
介绍下从kafka中获取数据,然后放入到 mysql 的操作!
目录
目标
一、准备工作
1.kafka集群
2.zookeeper集群
3.数据表
4. 造数程序
5.发送程序
二、NIFI UI配置
1.kafka的处理器
2. EvaluateJsonPath 处理器配置
3.SplitJson处理器
4.EvaluateJsonPath 处理器
5.PutSQL处理器
6.Setting 的配置信息
7.Scheduling的设置
8.完整的配置图如下
9.执行结果
目标
模拟一个考试系统(学生,老师,成绩),将考试系统的所有数据都放入到kafka的流中,用 nifi 的组件去去拿取出来,并放入到mysql的数据库中去的这样一个业务操作。
一、准备工作
1.kafka集群
必须要有个kafka集群或者有一个单机的kafka,用来存放数据。具体怎么安装kafka或者kafka集群,网络中有很多,这里不再复述。注意:在 kafka 的 server.properties 中要配置如下项目,否则容易出错,连接不上的问题。
host.name=192.168.10.216
listeners=PLAINTEXT://192.168.10.216:9092
2.zookeeper集群
nifi是基于zookeeper集群来实现协调操作的,那么一个必备的zookeeper集群是少不了的,kafka流式处理同样也是要zookeeper的,所以zookeeper是一定要安装好的,如果是单机,那就统一使用单机处理。
安装 zookeeper 的时候,一定要注意 zookeeper 的dataDir 目录一定要跟kafka的config目录下的目录是一致的。
3.数据表
数据表在一个sql文件里面,具体信息如下: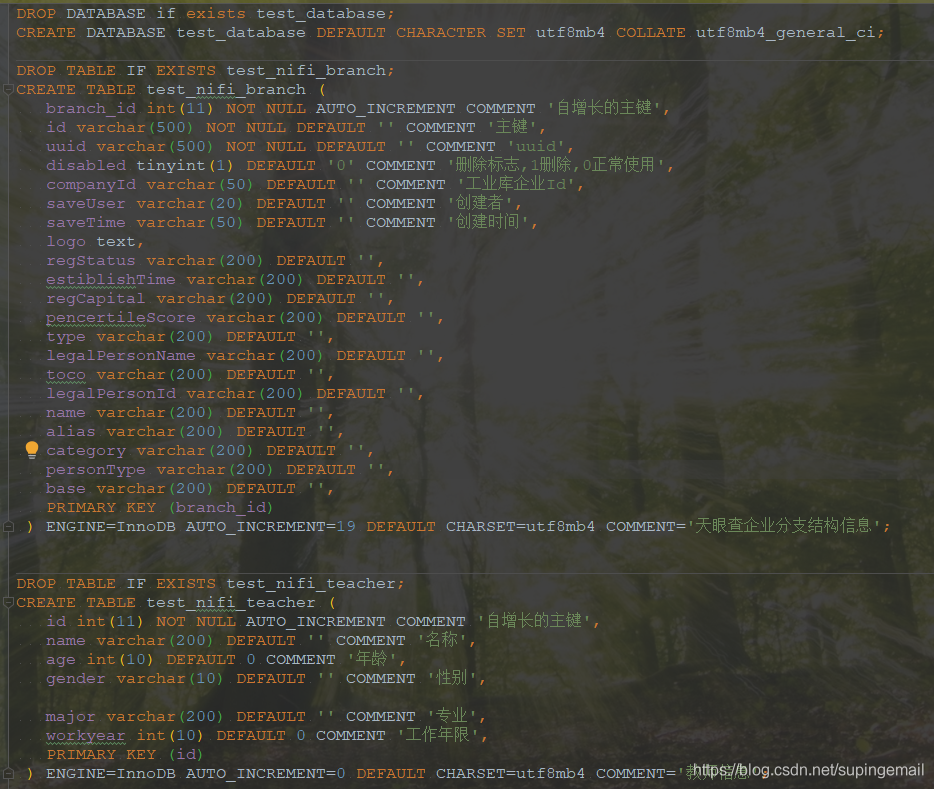
4. 造数程序
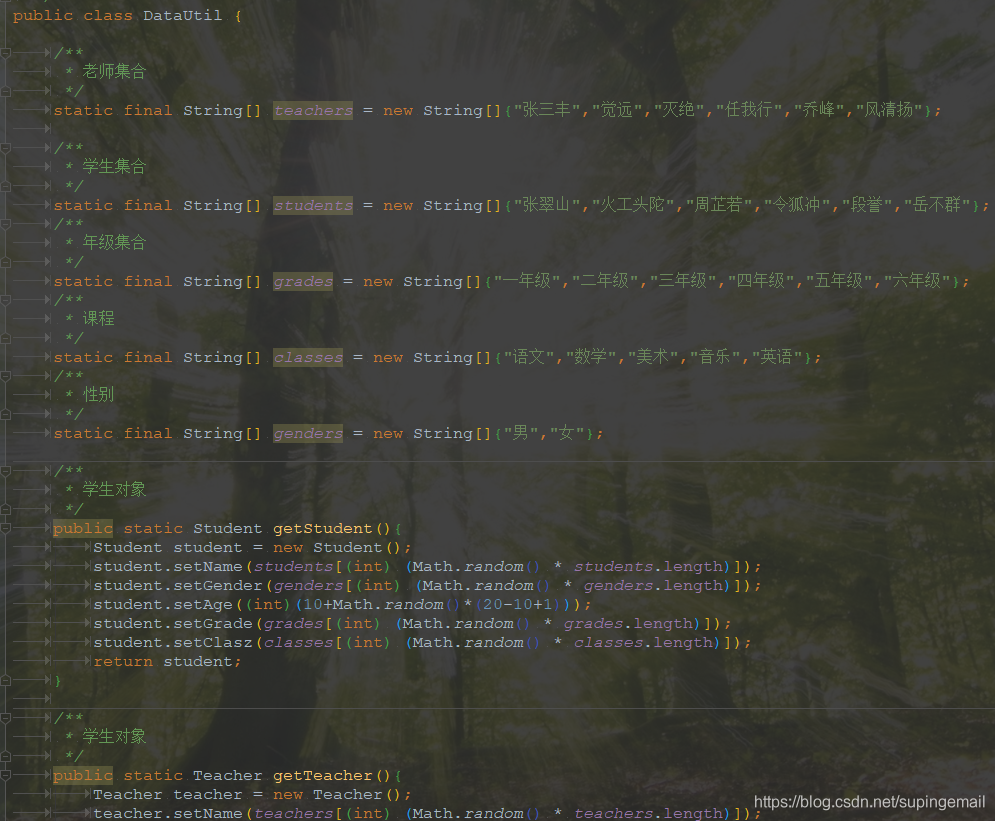
5.发送程序
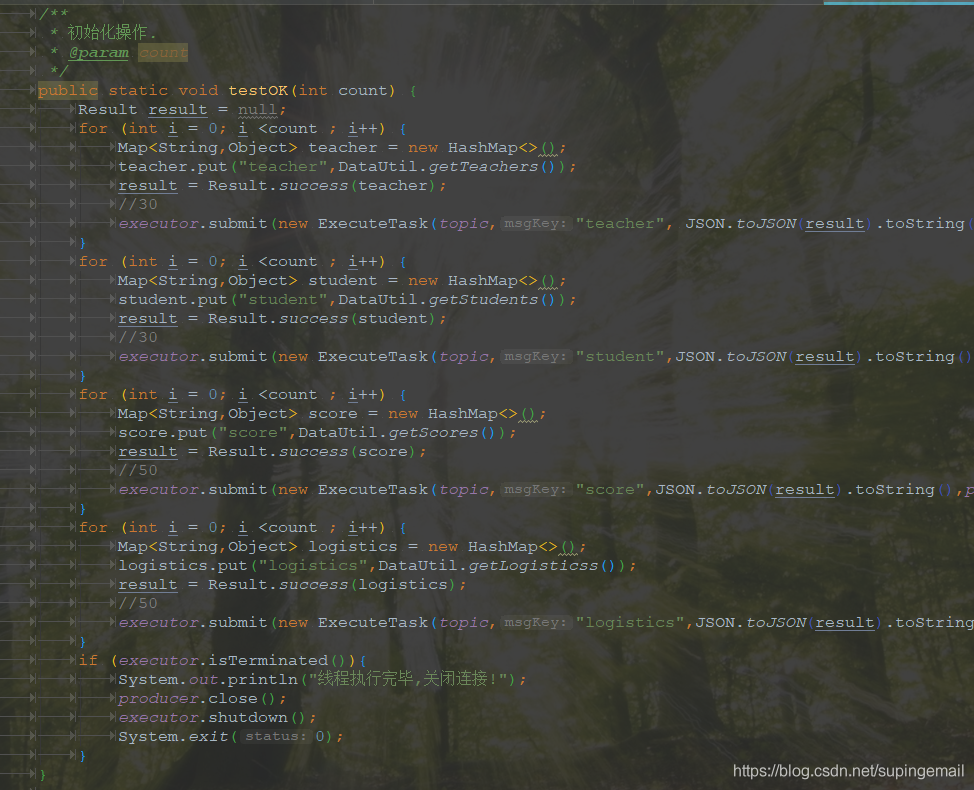
二、NIFI UI配置
需要在nifi的UI界面上配置上kafka的处理器,分隔的处理器,转化校验处理器,放入数据库处理器等,那么现在我们一步一步来操作:
1.kafka的处理器
拉取一个kafka的处理器,并做如下配置:,主要是这个配置,配置出错,那么可能导致没有办法进行下一步操作。
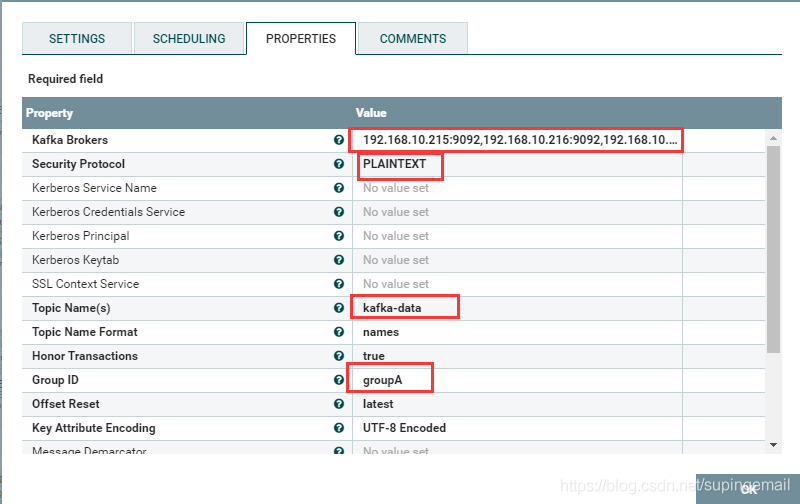
红线部分的都是需要注意的地方,如果配置出错,那么可能结果也会出错!
2. EvaluateJsonPath 处理器配置
拉取一個EvaluateJsonPath 处理器,用来将kakfa内的jsong数据做简单的处理,主要是得到数据标识和返回的消息,具体配置如下:
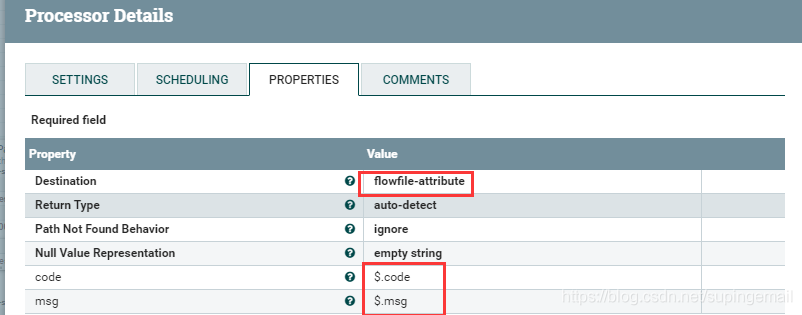
红线部分也是要特别注意的地方,如果配置出错,那么结果也会出错.
3.SplitJson处理器
配置SplitJson处理器,用来获取json串中的json数据对象,这样方便后边用来入库.
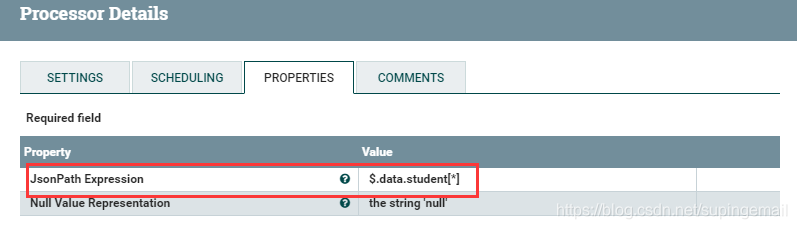
Json path 这块的配置很重要,如果配置出错,那么得到的数据json串也会出错,自然结果也会出错。
4.EvaluateJsonPath 处理器
拉取一個EvaluateJsonPath 处理器,用来将kakfa内的json数据做简单的处理,主要是得到数据具体项目,具体配置如下:
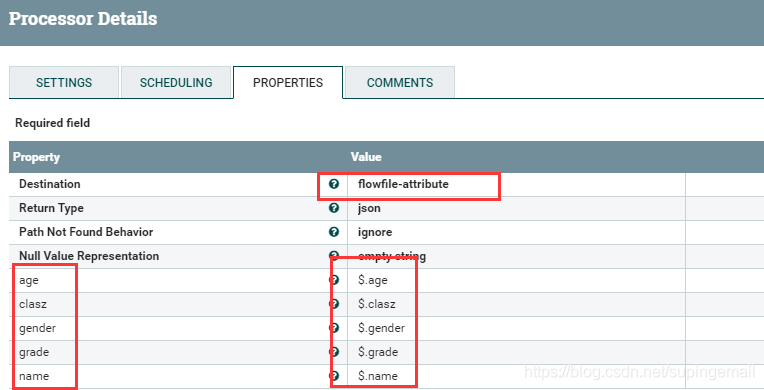
此操作的意义是 : 将json串中的数据条目,使用 $ 表达式的方式获取数据值,在数据走到这个处理器的时候,就可以拿到对应的数值。
5.PutSQL处理器
拉取一个PutSQL,设置连接池对象,和insert 语句操作,具体如下:

在此,DBCPConnectionPool的连接池配置,这里在使用的时候,就可以看看连接池的配置:
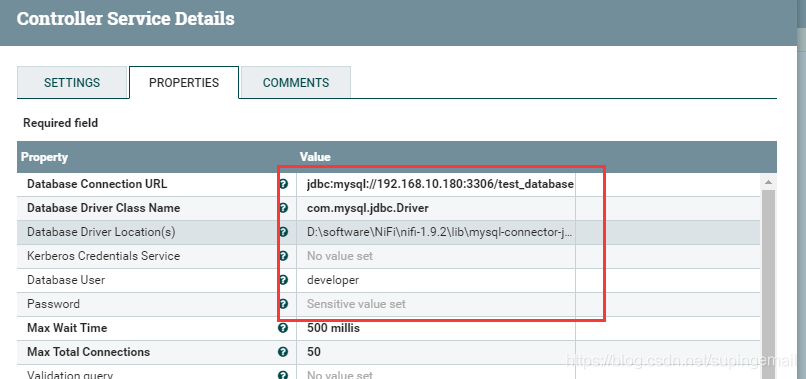
主要配置这些操作,就可以让连接池生效管用,前提是 : 一定要配置正确相关信息。
6.Setting 的配置信息
每一个处理器,都有自己的配置信息需要处理,所以要格外注意配置信息的配置:
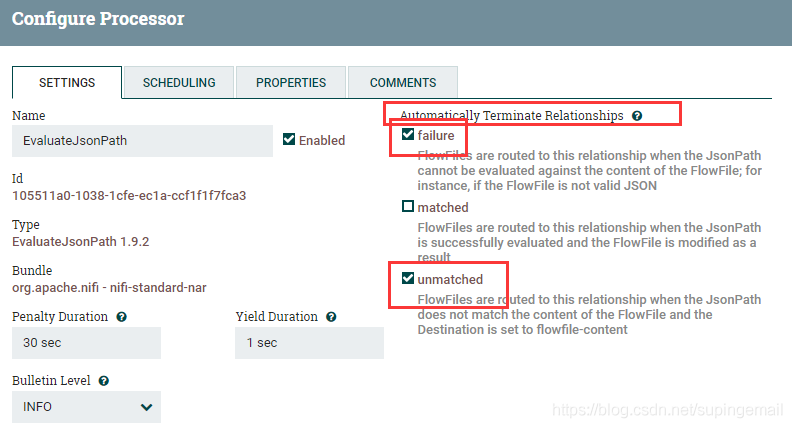
我们再使用任何处理器的时候,都会要让设置automatically terminate relationships的
这里设置表示你要丢弃哪些关联,这里主要是丢弃failure 和 unmatched的项目。
7.Scheduling的设置
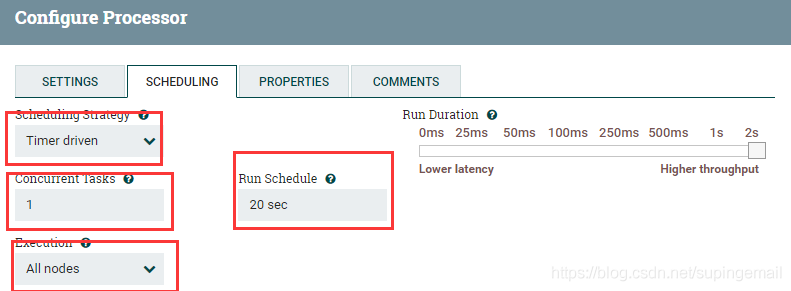
用红框标注的,是需要注意的地方,表示每一个处理器在处理的时候,可以配置的项目.
8.完整的配置图如下
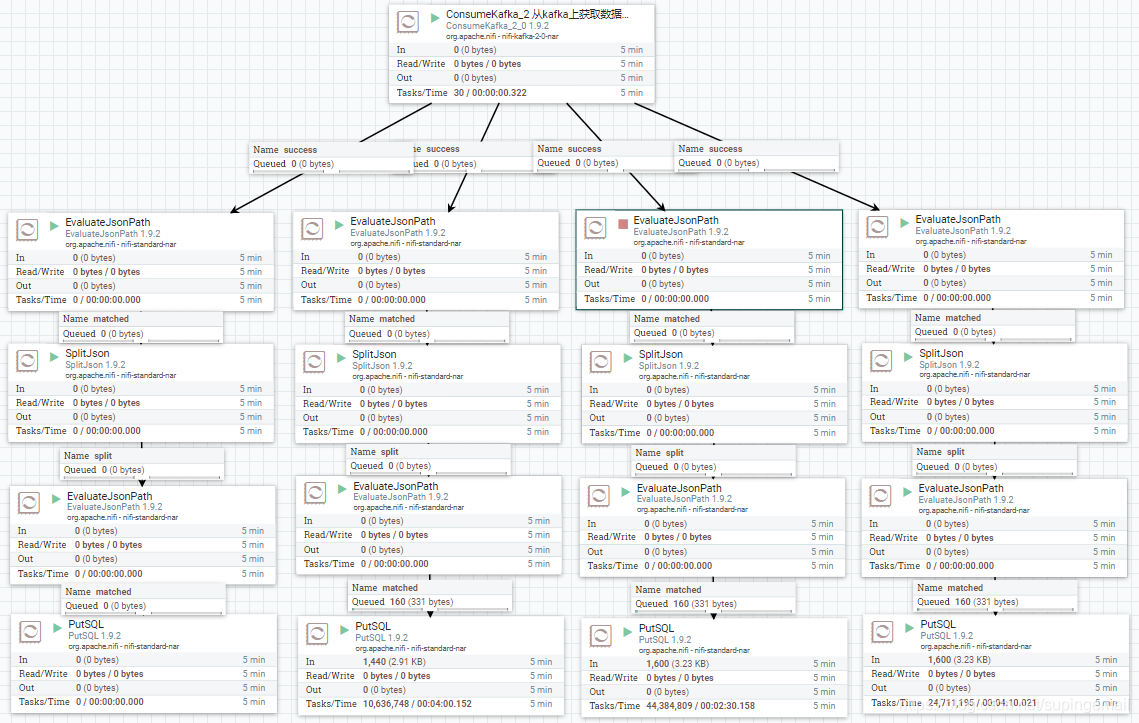
这个表示把数据放入到kakfa的处理器中,然后从处理器中把josn数据取出来,格式化,然后组合成insert into 的插入sql语句,插入完成之后,就可以去数据库中查找最终的结果。
9.执行结果
可以通过数据库来查看数据录入的正确性.通过以上的操作,开启处理器后,可以看见数据库的结果为 :
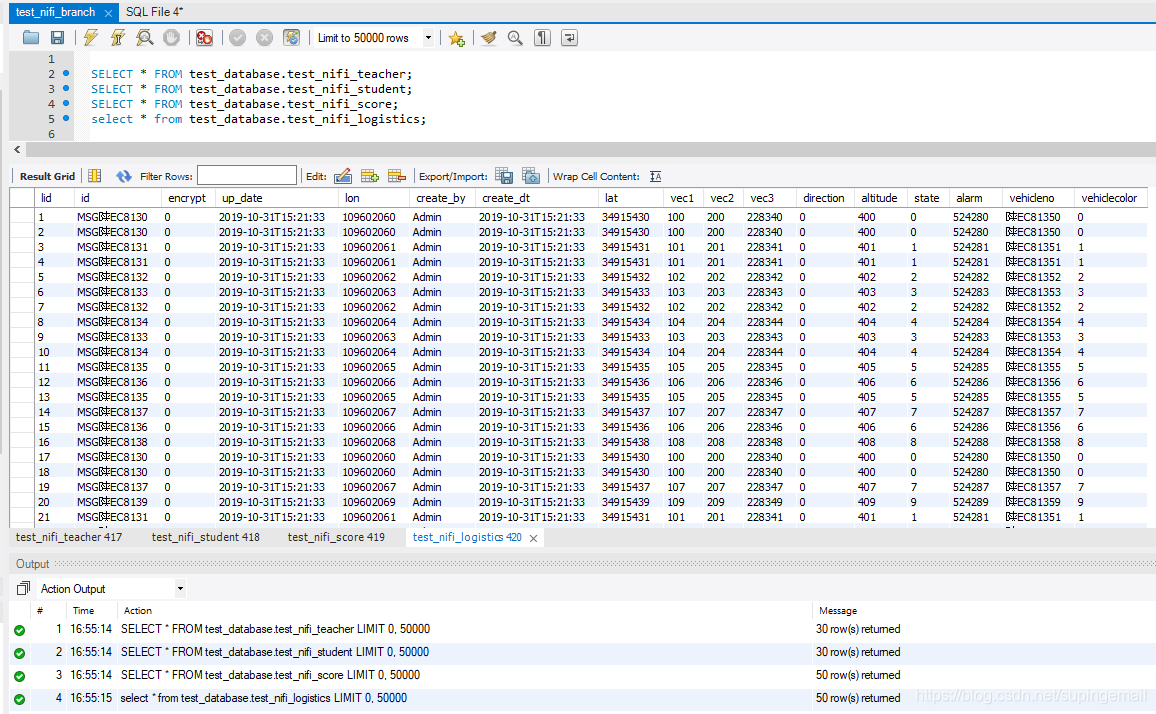
如此操作之后,就可以将我们放入kafka的json格式的老师数据,同学数据和分数数据拉取下来,放入到我们的mysql数据库中。
如果需要源码或者需要这个的设计文档,请微信搜索:codingba ,留意我会发相关资料。




