1 地址总线、数据总线和机器字长
1.1 数据总线
数据总线DB(Data Bus)用于传送数据信息。数据总线是双向三态形式的总线,即它既可以把 CPU 的数据传送到存储器或输入输出接口等其它部件,也可以将其它部件的数据传送到 CPU。
1.2 地址总线
地址总线AB(Address Bus,又称位址总线) 属于一种电脑总线 (一部分),是由 CPU 或有 DMA 能力的单元,用来沟通这些单元想要存取(读取/写入)电脑内存元件/地方的实体位址。
地址总线AB是专门用来传送地址的,由于地址只能从 CPU 传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。地址总线的位数(宽度)决定了 CPU 可直接寻址的内存空间大小(The width of the address bus determines the amount of memory a system can address),即决定有多少的内存可以被存取(addressable memory space)。
1.3 机器字长
机器字长是指 CPU 一次处理数据的宽度(Word),我们通常所说的 “32位CPU”、“64位CPU” 中的 “32”、“64” 就是机器字长(word size, word width, or word length)。
机器字长主要由运算器、寄存器决定,通常寄存器长度等于机器字长。如32位处理器,每个寄存器能存储 32bit 数据,加法器支持两个 32bit 数据进行相加。
地址总线可访问的字节(位数)通常等于机器字长。
在 macOS/Xcode 下可用 clang -dM 命令打印 Xcode 编译器在 各个 arch 指令集下的默认宏定义(macro definitions):
$ clang -dM -E -arch $arch -x c /dev/null其中 $arch 可取 32 位的 i386, 64 位的 x86_64(amd64);32 位的 armv7(s),64 位的 arm64。
从打印结果可知针对 32 位 CPU 定义了 _ILP32 和__ILP32__ 的值为1;针对 64位 CPU 定义了_LP64 和__LP64__ 的值为1。
Xcode 工具链中的 MacOSX.sdk 和 iPhoneOS.sdk 的 usr/include/stdint.h 进一步根据 __LP64__==1 定义了机器字长 __WORDSIZE:
#if __LP64__ #define __WORDSIZE 64 #else #define __WORDSIZE 32 #endif目前嵌入式处理器大都以 32 位为主,32 位处理器的地址总线通常都是32位,可寻址范围是 4G byte,地址总线越宽,可寻址范围越大。
指针(uintptr_t)位宽 __POINTER_WIDTH__ =__SIZEOF_POINTER__ * CHAR_BIT,通常等于机器字长。其中 CHAR_BIT 为最小可寻址单位(address resolution)—— 1 byte 所含比特位串宽度,POSIX.1-2001 规范该值为 8。
两个指针之间的偏移计算结果(ptrdiff_t)的原生类型(typedef alias)及字宽同指针(uintptr_t)。
通常数据总线的带宽都要高于机器字长,32位处理器很多都采用 64bit、128bit 的数据带宽,这样可以一次读取更多的数据。
2 从机器语言到汇编指令
2.1 语言要素
语言主要包括以下要素:
1.词汇。一个词汇代表一个意象片段,每个词汇与某事物一一对应。
2.语法。包括格式、结构和规则。
3.语句。词汇按照一定的语法规则有机组合形成语句。
4.语义。亦即动机性,即维特根斯坦说的语言中训练的部分。它包括词汇的表意和语句的含义,表达信息或操作命令。
2.2 打孔纸带
CPU 不认识汇编语言,更不认识 C/C++ 等高级语言,它只认识机器语言(machine language)。计算机内部的数字逻辑电路只认识以高低电平或者开关通断状态信号来量化的二进制0和1,因此机器语言都是基于二进制的编码序列。
在远古时代,只能使用机器语言编程。当程序需要被运行时,程序员需要将他写的程序写入到存储设备上,最原始的存储设备就是纸带,即在纸带上打相应的孔(punched tape,perforated paper tape)。每个孔代表一位(bit),穿孔(presence)表示1,未穿孔(absence)表示0,这些孔序列被扫描识别为机器码位串,并由译码器(扫描器)识别。计算机运算完毕,需要人工翻译结果。
下图为打孔工具:
下图为常用的5列孔和8列孔穿孔纸带(Five-hole and eight-hole punched paper tape):
下图为一段按照 FortranCodingForm 打孔的 FORTRAN 代码片段穿孔纸带:
下图为 CNC 数控机床八单位穿孔纸带的代码标准:
参考阅读:《老爷计算机的打孔纸带》《我的电脑生涯(1):初识计算机》《编程语言简史》《纸带打孔编程之后是怎样编程? 》《Eight Ways to Read Punched Tape》
2.3 汇编语言
二进制机器码太难记了,可以想见打孔编程的工作是多么的枯燥和乏味。于是人们发明了汇编语言(assembly language),使用人类语言的单词作为助记符(instruction mnemonics)与机器码建立一一对应关系。
汇编器维护了这张映射表,并在汇编阶段将汇编代码翻译成指令机器码。从大的方面讲,汇编是相当简单的,它只是使用助记符号替代对应的机器码元。

2.3.1 Intel x86 汇编指令及编码
Intel 机器指令集参考:
– Volume 1: Basic Architecture/Chapter 5 Instruction Set Summary
– Volume 2: Instruction Set Reference, A-Z
下图为 Volume 2: Instruction Set Reference, A-Z/Chapter 2 Instruction Format 定义的 Intel 指令编码格式:
下图为 Appendix B Instruction Formats and Encodings 定义的 General Purpose Instruction Formats and Encodings for Non-64-Bit Modes 汇编指令及机器编码:
8086
指令编码的一般格式如下:
以下为 8086 中具体的 ADD 指令编码示例:
2.3.2 ARM 汇编指令及编码
ARM 机器指令集参考:
ARM and Thumb-2 Instruction Set Quick Reference Card
ARMv7-AR Reference Manual (Issue C)
– A8: Instruction Descriptions/A8.8 Alphabetical list of instructions
– A9: The ThumbEE Instruction Set
ARMv8-A Reference Manual (Issue B.a)
– Part C: The AArch64 Instruction Set
– Part F: The AArch32 Instruction Sets
– G1.5 Instruction Set state
• The T32 instruction set was called the Thumb instruction set.
• The A32 instruction set was called the ARM instruction set.
Cortex-A Series Programmer’s Guide for ARMv8-A
– 5: An Introduction to the ARMv8 Instruction Sets
– 6: The A64 instruction set
下图为 ARMv7-AR 中定义的 A8.8.7 ADD (register, ARM) 指令编码:
2.3.3 MIPS 汇编指令及编码
MIPS 机器指令集参考:
MIPS32 Instruction Set Quick Reference v1.01
The MIPS32 Instruction Set v6.05 /The MIPS64 Instruction Set v6.05
Introduction to the MIPS32 Architecture v6.01
– Chapter 5 CPU Instruction Set
下图为 The MIPS32 Instruction Set v6.05 中的 ADD 指令编码:
MIPS 中的“add d,s,t” 和 “and d,s,t” 都属于3寄存器算术/逻辑运算指令组,域31-26为6位长的主操作码“op”,add和and共享op域,都为0;域5-0为子操作码域,用于区分add(32)和and(36)。25-21为第一个源操作数寄存器s的编码;20-16为第二个源操作数寄存器t的编码;15-11为目的操作数寄存器d的编码。
下表列出了 MIPS32 中汇编指令 add/and 与机器码的对应关系。
ASM
31-26
25-21
20-16
15-11
10-6
5-0
add d,s,t
0
s
t
d
0
32
and d,s,t
0
s
t
d
0
36










3 指令集
3.1 指令集
在机器语言中,指令就是一个语句。指令格式为“操作码域+操作数域”,操作码域指明了指令的操作性质及功能,操作数域则给出了操作数或操作数的地址。操作码和操作数是机器可识别的词汇,包括“操作命令”、“内存地址”、“字节”、“寄存器”,它们组合在一起的机器指令体现语义。不同类型的操作命令和操作数,具有不同的组合表现形式。
指令集(ISA:Instruction Set Architecture)是指CPU指令系统所能识别(翻译)执行的全部指令的集合。处理器要完成计算任务,需要具备以下几种指令类型。
(1)运算指令
运算由运算器单元(ALU)实现,指令包括算术运算指令、逻辑运算指令和移位指令。
算术运算指令实现加减乘除(+-*/)等基本的算术运算;逻辑运算指令实现与或非(&|~)等基本的逻辑运算;移位指令实现二进制比特位(bit)的左右移(<<>>)运算。
(2)控制指令
除了做计算外,CPU还要实现循环。循环是由跳转指令实现的,跳回去执行就是循环。循环在一定条件下跳出,否则就成死循环了,条件跳转指令能完成这个功能。条件跳转指令在一定条件下实现跳转,它能实现分支功能。跳转指令也称为控制指令。控制由CPU控制器单元实现。
(3)数据传送指令
运算和控制指令的操作数从哪里来的呢?操作数都放在存储器中。在x86 IA中,运算指令的操作数既可以是寄存器,也可以是存储器;而在其他 RISC IA(例如MIPS)中,运算指令的操作数只能是寄存器,因此需要先使用加载指令(load)将存储器中的数据导入到寄存器中,运算完成后,再用存储指令(store)将寄存器中的运算结果数据导出到存储器中。这类指令就是数据传送指令。
有了这三类指令,CPU就能完成各种复杂的运算。
3.2 指令集的演进
当今处理器的指令集按照复杂度可简单分为两种:复杂指令集(CISC,Complex InstructionSet Computer)和精简指令集(RISC,Reduced Instruction Set Computer)。
一开始的处理器都是 CISC 架构,随着时间的演进,有越来越多的指令集加入。采用复杂指令系统的计算机有着较强的处理高级语言的能力,这对提高计算机的性能是有益的。当计算机的设计沿着这条道路发展时,有些人没有随波逐流,他们回过头去看一看过去走过的道路,开始怀疑这种传统的做法:IBM 公司设在纽约 Yorktown 的 JhomasI.Wason 研究中心于1975年组织力量研究指令系统的合理性问题。因为当时已感到,日趋庞杂的指令系统不但不易实现,而且还可能降低系统性能。
1979年以帕特逊教授为首的一批科学家也开始在美国加册大学伯克莱分校开展这一研究,结果表明,CISC 存在许多缺点。首先,在这种体系架构中,各种指令的使用频率相差悬殊:一个典型程序的运算过程所使用的80%指令只占一个处理器指令系统的20%,剩余80%的指令则只占整个程序的20%。事实上最频繁使用的指令是取、存和加这些最简单的指令。于是帕特逊教授提出了精简指令集的理念,主张指令系统应当只包含那些使用频率很高的少量指令,较为复杂的指令则利用常用的简单指令去组合。按照这个原则发展而成的计算机被称为精简指令集计算机(Reduced Instruction Set Computer)结构,简称 RISC。
在设计理念上,RISC 的设计重点在于降低由硬件执行指令的复杂度,因为软件比硬件容易提供更大的灵活性和更高的智能,因此 RISC 设计对编译器有更高的要求;CISC 的设计则更侧重于硬件执行指令的功能,使 CISC 的指令变得很复杂。总之 RISC 对编译器的要求高,CISC 强调硬件的复杂性,CPU 的实现更复杂。CISC 提供了很多微码支持,使得汇编程序的工作量减少,而 RISC 完成同样的操作则需要更多的指令。
3.3 RISC 与 CISC 比较
<1>指令集——RISC 处理器减少指令集的种类,只提供固定长度的简单指令,大多都在四五个周期内完成,通常一个周期执行一条指令。
<2>寄存器——RISC 的寄存器拥有更多的通用寄存器,寄存器操作较多。例如 MIPS 提供了32个通用寄存器,ARM 提供了27个通用寄存器,CISC 的寄存器都是用于特定目的的。
<3>内存访问——RISC 处理器只处理寄存器中的数据,运算指令的操作数只能是寄存器。这是因为访问存储器很耗时,同时对外部存储器的读写会影响其寿命;CISC 能够在存储器中直接运行。对内存变量的直接访存不利于流水线实现,因此 RISC 没有实现可以操作内存变量的指令。RISC 内存引用总是通过 load 指令将内存变量加载到寄存器,再通过 store 指令将寄存器中的值写回到内存,大型寄存器堆(Register Files)使得这不会成为一个大问题。
<4>简化的寻址方式——RISC 没有 CISC 那样复杂众多的寻址方式。例如 MIPS 只有一种数据寻址模式,几乎所有的加载和存储的内存地址都是通过单个基址寄存器的值加上一个16位的有符号偏移量来选择。
<5>高效的流水线特性——流水线的本质就是 CPU 并行运行,只是并行运行不像FPGA中的那么直接,它只是把一条指令分成几个更小的执行单元;CISC 指令的执行需要调用一个微码,明显没有 RISC 的指令吞吐量大。
固定的指令长度、大型寄存器堆和 load/store 结构可充分发挥流水线特性。在并行处理方面 RISC 明显优于 CISC,RISC 可同时执行多条指令,它可将一条指令分割成若干个进程或线程,交由多个处理器同时执行。由于 RISC 执行的是精简指令集,所以它的制造工艺简单且成本低廉。
<6>子程序调用——在 CISC 中,程序调用返回时需要将上下文保存到堆栈中,push/pop 指令需要访问内存操作;而 RISC 没有提供 push/pop 支持,将它们存放在寄存器中,而且参数也是用寄存器传递。RISC 中断可视为特殊的子程序调用:CISC 发生中断时,所有的寄存器内容都被压入堆栈中;而 RISC 对中断进行区分对待,分为轻量级和重量级。对于轻量级中断只保存需要保存的寄存器内容;对于重量级中断的处理如同常规中断。
<7>RISC的缺点——代码密度不高,可执行文件体积较大,汇编代码可读性差。代码密度不高是值得关注的问题:若不使用 cache,会需要更大的指令存储控件,取指时也占用更大的内存带宽;若采用 cache,又会降低 cache 的命中率。而从 CPU 的设计上来讲,由于 RISC 的核心代码要少很多,使得其结构相应简化,因此在体积、造价、功耗、散热和价格上都具有优势。
<8>CISC与RISC的融合演进
从以上的比较来看,RISC 与 CISC 各有千秋,由于 RISC 具有更强的实用性,故应该是未来处理器的发展方向。但事实上,当今时代 wintel 一统江湖,且早期很多软件都是根据 CISC 设计的,单纯的 RISC 将无法兼容。此外,现代 CISC 结构的 CPU 已经融合了很多 RISC 的成分,其性能差距已经越来越小。复杂指令可以提供更多的功能,这是程序设计所需要的。例如 ARM 提供了DSP& SIMD扩展:增强型DSP指令(E变种)和媒体功能扩展(SIMD变种)。因此,CISC 与 RISC 的融合应该是未来的发展方向。
3.4 指令集的五朵金花
处理器公司很多,品牌也很多,而指令集则相对稳定,用指令集对处理器公司分类是比较常见的做法。有5种指令集最为常见,它们构成了处理器领域的5朵金花。
<1>x86——硕大的大象
Intel x86 是经典的 CISC 体系结构,它是史上最赚钱的指令集,几乎所有的个人计算机都使用 Intel x86 指令集的处理器。
英特尔的钟摆策略(Intel’s Tick-Tock Strategy):在奇数年,英特尔将会推出新的工艺;而在偶数年,英特尔则会推出新的架构。简单的说,就是奇数工艺年和偶数架构年的概念。钟摆策略能够体现英特尔技术变化方向。当有英特尔钟摆往左摆的时候,tick这个策略会更新工艺;往右摆的时候,tock会更新处理器微架构。
参考:
官方 datasheet:Intel® 64 and IA-32 Architectures Software Developer Manuals
<2>ARM——稳扎稳打的蚁群
如果要问哪个指令集的处理器销量最大,很多人会认为是 Intel,不过一家来自英国的公司让我们大跌眼镜,这家公司就是 ARM 公司。
在智能手机领域,ARM(Acorn RISC Machine)独领风骚,占据了手机市场90%以上的份额。当今手机上的应用处理器,不管是高通还是TI的,东芝还是三星的,在内部都采用了 ARM 内核(microprocessor)。
从 ARMv7开始引入了 Architecture profiles的概念:针对高、中、低阶划分为 A(Application profile)、R(Real-time profile)、M(Microcontroller profile) 三大系列。ARMv6/ARM11 之后的处理器家族改称为 Cortex。当今市场上的高阶智能手机普遍采用 Coretex-A 系列或 A 型变种。
iPhone 4S 的 Apple A5 和 iPhone 5(C) 的 Apple A6 都是基于 32-bit 的 `ARMv7-A` 架构; iPhone 5S 之后的 Apple A7~A10 开始基于 64-bit 的 `ARMv8-A` 架构。
model arch(ISA) profile Processor(holding) Device(SoC) iPhone 4 ARMv7-A A ARM Cortex-A8 Apple A4 iPhone 4S ARMv7-A A ARM Cortex-A9 Apple A5 iPhone 5(C) ARMv7-A A ARM Cortex-A15(tweaked) Apple A6 iPhone 5S ARMv8-A A variant Apple A7 iPhone 6(+) ARMv8-A A variant Apple A8 iPhone 6S(+) ARMv8-A
A variant Apple A9 iPhone 7(+) ARMv8-A
A variant Apple A10
参考:
WiKi:ARM architecture /List of ARM microarchitectures
官方 datasheet:ARM infocenter |ARM 体系结构 | Reference Manuals;Architectures, Processors, and Devices Development Article
<3>MIPS——优雅的孔雀
如果要说最经典的 RISC 处理器,那么非 MIPS 莫属,就连它的竞争对手,也不得不承认它的优雅,它被作为处理器教科书的典范,很多其他的处理器,都能看到它的身影。
MIPS 全称为 Microprocessor without Interlocked Piped Stages,无内部互锁流水级的微处理器。中国科学院计算所自主研发的龙芯,采用类似于 MIPS 的简单指令集。
参考:
WiKi:MIPS architecture
官方 datasheet:MIPS Architectures / documentation
<4>Power——昔日的贵族
最早提出 RISC 思想的是 IBM 公司,PowerPC 是一种 RISC 多发射体系结构。
1990 年,IBM 推出了高性能的 POWER(Performance Optimized With Enhanced RISC)处理器。POWER 性能卓越,一直以来都被用在 IBM 自己的服务器上。1997 年与国际象棋大师卡斯帕罗夫交战的深蓝计算机使用的是 POWER 2 处理器;2011年参加知识竞赛电视节目“Jeopardy!”挑战人类的 Watson 计算机使用的是 POWER 7 处理器。
由于 POWER 的高性能,IBM 想到可以将 POWER 用于 PC 领域,因此 IBM 向 Apple 抛了橄榄枝,Apple 当然求之不得。Apple 一直都使用 Motorola 的处理器,因此 Apple 又把 Motorola 拉下了水。这3家公司一拍即合,富有传奇色彩的三大巨头,同时又是在 PC 时代只能赚吆喝的3个难兄难弟终于结拜在了一起,于1991年成立了AIM联盟(AIM 为 Apple、IBM、Motorola 的3个首字母)。AIM 对 POWER 处理器进行了修改,于是就形成了 PowerPC,PC 是 Performance Computing 的缩写。
Apple 公司的 Macintosh 过去十几年来一直采用的是 IBM 研发的 PowerPC 处理器,但是苹果于2005年6月宣布终止与IBM和摩托罗拉长期合作关系,放弃 PowerPC 支持全面 Intel 化。苹果CEO史蒂夫·乔布斯(Steve Jobs)指出,转换芯片架构是因为英特尔提供更优越的产品蓝图。
<5>C6000——偏安一隅的独立王国
以上介绍的这些处理器,都是较通用的处理器,还有一种较专业的处理器,它的名字叫 DSP(Digital Signal Processor,数字信号处理器),专业做信号处理运算的。
这几年,全球的无线通信网络建设如火如荼,视频网站、视频通信系统也如雨后春笋般涌现出来,在这些产品或服务的背后,一个是无线通信技术,一个是音视频技术,这二者的共同点在于:它们都需要大量的信号处理运算,而这正是DSP的强项。
20世纪80年代初,Motorola 和 TI(德州仪器)都推出了自己的手机 DSP 芯片,Motorola 要强于 TI,但由于 Motorola 的芯片只给自己的手机用,诺基亚、爱立信等公司选择了 TI,从此成就了 TI。
现在的 DSP 芯片主要由 TI、Freescale、LSI 等公司推出,TI DSP 一家独大,占据绝大部分市场份额。TI 也是半导体领域的先驱之一,第一块集成电路的发明人、诺贝尔奖得主 Jack Kilby 就来自于 TI。
C6000 系列 DSP 是 TI 的高端 DSP,C62/C64/C64+ 是定点 DSP 内核,C67 是浮点 DSP 内核,C66 是定点/浮点融合的内核。
与 C6000 直接竞争的,是 Starcore 体系结构,最早由 Infineon、Agere、Motorola 的合资公司设计。公司经过多年的分与合之后,目前这个体系结构的 DSP 由 Freescale 和 LSI 推出。
4 指令的执行
4.1 通用寄存器
指令的语义主要是完成一定的功能操作,其操作对象就是操作数。在进行运算之前,数据必须就位,那么操作数放在哪里呢?
CPU 内部有很多通用寄存器(General Purpose Register),这些寄存器用来存储指令的操作数,它对程序员可见。例如x86有8个通用寄存器,MIPS有32个寄存器。这一堆寄存器也被叫做寄存器堆(Register File)。寄存器一般为 SRAM,可将其看做 CPU 的缓存。
在硬件实现上,算术逻辑运算单元 ALU 直接访问通用寄存器进行计算。通用寄存器中的数据需要先读到ALU输入寄存器(ALU Input Register)中,ALU运算结束后,数据会存储在ALU输出寄存器(ALU Output Register)中,最后再送回通用寄存器中。
在MIPS中,运算指令的操作数只能是寄存器,因此在执行运算指令之前,调用数据传送指令load将数据从内存加载到通用寄存器中。在x86中一般使用 mov 指令进行数据传送。
4.2 指令执行过程
指令的执行过程按时间顺序可分为以下几个步骤:
(1)CPU发出指令地址。将指令指针寄存器(IP,Instruction Pointer)的内容——指令地址,经地址总线送入存储器的地址寄存器中。
(2)从地址寄存器中读取指令。将读出的指令暂存于存储器的数据寄存器中。
(3)将指令送往指令寄存器。将指令从数据寄存器中取出,经数据总线送入控制器的指令寄存器中。
(4)指令译码。指令寄存器中的操作码部分送指令译码器,经译码器分析产生相应的操作控制信号,送往各个执行部件。
(5)按指令操作码执行。
(6)修改程序计数器的值,形成下一条要取指令的地址。若执行的是非转移指令,即顺序执行,则指令指针寄存器的内容加1,形成下一条要取指令的地址。指令指针寄存器也称为程序计数器(PC,Program Counter)。
5 流水线作业(The Instruction Pipeline)
5.1 流水线的概念
关于流水线,生活中到处可见,工厂的生产流水线和食堂的打饭流水线都是流水线的经典范例。在《MIPS体系结构透视》中借用食堂打饭流水线的例子很好的阐述了流水线的概念。
所谓流水线(pipeline),就是将那些重复性的工作分解成几个串行的部分,使得工作能在工人中间移动。每个熟练工人只需要依次将他们熟悉的那部分工作做好即可。虽然每个顾客等待服务的总时间有所增加,但是却有四个顾客能同时接受服务,这样在午餐高峰期能够接待的顾客数量增加了三倍。
假如Evie的小卖部新增了一种炸鸡腿,交由Bert负责派发,这样Bert在给顾客派发炸土豆时还得派发炸鸡腿。此时,Bert这一环节相比以前耗时增加,导致流水线效率下降。于是Evie再请了一个朋友加入食物派发流水线,专门负责派发鸡腿。我们说Evie店的流水线从四步(step)增加到了五步,流水线的级数(深度)增加了一级,相应增加了人力成本。
5.2 CPU指令执行流水线
如果将程序看成是内存中存储的一些指令的话,一个即将运行的程序看起来和排着队等待接受服务的顾客没什么相似之处。但是,在CPU看来,情况就不一样了。CPU从内存中提取每条指令,进行译码,找到所需要的操作数,执行相应操作,并存储运算产生的结果——然后又从头开始重复同样的工作。这样等待执行的程序就是一个指令的序列,该队列中一次只有一条指令经过CPU。
由于每条指令要做不同的工作,因此在CPU内部已经配有各种不同的专用的大块逻辑电路(每一流水阶段都有独立的逻辑电路来处理),所以构造一个流水线并没有使CPU复杂度增加多少,只是让CPU工作得更努力一些而已。
采用流水线技术后,并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行,因而从总体上看加快了指令流速度,缩短了程序执行时间。
为了进一步满足普通流水线设计所不能适应的更高时钟频率的要求,高档次处理器中的流水线的深度(级数)在逐代增多。当流水线深度在5~6级以上时,通常称为超流水线结构(Super Pipeline)。显然,流水线级数越多,每级所花的时间越短,时钟周期就可以设计的越短,指令速度越快,指令平均执行时间也就越短,但是相应设计成本也会增加。
5.3 ARM 多级流水线
在 TI C6000 DSP 中,所有指令的执行大概分为Fetch(取指)、Decode(译码)、Execute(执行)三个大的步骤,每个大的步骤又可以细分为一些小的步骤,实现了更深的流水线。
ARM7T/ARMv4T/ARM7TDMI(-S) 及之前的 ARM cores 即为经典的 3级流水线(3-stage pipeline)设计。




从 ARM9/ARMv4T 开始,ARM 体系架构从普林斯顿结构(von Neumann architecture)升级为改进的哈佛结构(Harvard architecture),相应的流水线也从 ARM7EJ/ARMv5TEJ/ARM7EJ-S 开始升级支持到 5级流水线(5-stage pipeline),参考下节 MIPS 经典五级流水线。
ARM10 开始支持6级流水线,ARM11开始支持8级流水线。
发展到 Cortex-A(32-bit)/ARMv7-A/Cortex-A8 已经支持多达 13 级流水线,后续支持更深度的甚至乱序(out-of-order)的超标量(superscalar)流水线结构。
以下列举了 List of ARM microarchitectures 中由 ARM 公司设计的 ARM cores(family/architecture/core) 对应的流水线级数发展史:
- ARM7T/ARMv4T/ARM7TDMI(-S):3-stage pipeline
- ARM7EJ/ARMv5TEJ/ARM7EJ-S:5-stage pipeline
- ARM10E/ARMv5TE/ARM1020E:6-stage pipeline
- ARM11/ARMv6/ARM1136J(F)-S:8-stage pipeline
- ARM11/ARMv6T2/ARM1156T2(F)-S:9-stage pipeline
- Cortex-R/ARMv7-R/Cortex-R7:9-stage pipeline
- Cortex-A(32-bit)/ARMv7-A/Cortex-A7:8–10 stage pipeline
- Cortex-A(32-bit)/ARMv7-A/Cortex-A8:13-stage superscalar pipeline
- Cortex-A(32-bit)/ARMv7-A/Cortex-A15:15–24 stage pipeline
- Cortex-A(32-bit)/ARMv8-A/Cortex-A32:dual issue, in-order pipeline
- Cortex-A(64-bit)/ARMv8-A/Cortex-A57:3-way superscalar, deeply out-of-order pipeline
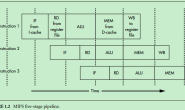
5.4 MIPS 经典五级流水线
(1)MIPS的五级流水线
MIPS体系架构依据流水线结构设计,将处理器的执行阶段划分为以下五个阶段:
- <1> IF:Instruction Fetch,取指。从指令缓存(I-Cache)中获取下一条指令。
- <2> ID(RD):InstructionDecode(Read Register),译码(读寄存器)。翻译指令,识别操作码和操作数,从寄存器堆中读取数据到ALU输入寄存器。
- <3> EX(ALU):Execute,执行(算术/逻辑运算)。在一个时钟周期内,完成算术或逻辑操作。注意,浮点算术运算和整数乘除运算不能在一个时钟周期内完成。
- <4> MEM:Memory Access,内存数据读或者写。在该阶段,指令可以从数据缓存(D-Cache)中读/写内存变量。平均来说,大约四分之三的指令在这一阶段没有执行任何操作,为每条指令分配这个阶段是为了保证同一时刻不会有两条指令都访问数据缓存。
- <5> WB:Write Back,写回。操作完成后,将计算结果从ALU输出寄存器写回到通用寄存器中。
只要CPU从缓存中获取数据,那么执行每条MIPS指令就被分成五个流水阶段,并且每个阶段占用固定的时间,通常是只耗费一个处理器时钟周期。RD/WB操作只占用半个时钟周期,故MIPS五段流水线只占用四个时钟周期。
对于运算指令,在MEM阶段空闲。对于load指令,在EX阶段计算要访问的地址,在MEM阶段从内存中将数据读入到 MEM register(MEM和WB之间的流水线寄存器)中,在WB阶段,将MEM register的数据写回到Register File中。对于store指令,在EX阶段计算要访问的地址,在MEM阶段将寄存器中的数据写回到存储器中。
(2)流水线和缓存
高效的流水线操作要求每个阶段占用相同的时间。高效的流水线还依赖于高速缓存(Cache),可以将内存访问速度提高50倍左右。当CPU需要数据时,首先在缓存中查找,如果该数据在缓存中则命中,那么缓存很快就把数据返回给CPU。由于无法猜测CPU将使用什么数据,故缓存仅存储最近一段时间内CPU从主内存中获取的数据副本。如果缓存缺失(没有命中),则需要重填(Invalidate and Refill)。
x86的寄存器个数很少,所以同样的程序编译给x86会比MIPS使用多得多的数据存取操作。当然,x86使用堆栈来代替寄存器给这些额外存取使用,这些堆栈位置将是内存中使用非常频繁的区域,对应高速缓存的使用效率非常高。
MIPS体系架构设计时采用了独立的指令缓存和数据缓存,这样CPU就可以同时获取指令和读写内存变量。
(3)严格流水线的限制
RISC(Reduced Instruction Set Computing,精简指令集)相对CISC(Complex Instruction Set Computing,复杂指令集)对指令集作了巧妙和有效的规定,从而使得流水线可以高效和成功的实现。所有的MIPS指令都经过严格的定义,以遵循同样的流水线阶段顺序,即使这些指令在某个流水线阶段什么也不做。于是最终结果是:只要CPU保持从缓存中命中(hit)数据,就能在每个时钟周期开始一条指令。
流水线的严格要求限制了指令的某些操作能力。
首先,要求所有的指令一样长(刚好是一个机器字长32位),这样的指令可以在固定时间被读取。定长指令的要求限制了操作的复杂程度。比如,在指令中没有足够的位空间对真正复杂的寻址模式进行编码。定长指令直接导致的一个问题就是,一个典型的程序在支持变长指令的x86体系架构上,编译后其指令平均长度只有3个字节,在MIPS代码中则全部是4个字节,从而占用了更多的内存空间。通常MIPS二进制文件要比680×0或80×86二进制文件大20%~30%。
第二,MIPS中的指令操作必须符合流水线特性。指令操作只有在正确的流水线阶段才能够执行,并且必须在一个时钟周期内执行完毕。比如,寄存器写回阶段只允许一个值存储到寄存器堆,因此这些MIPS指令只能修改一个寄存器的值。出栈操作需要将两个值(栈中的数据以及递增的栈指针值)写回到寄存器中,因此它不适合流水线。所以,MIPS没有提供对栈操作的硬件支持,没有x86那样的push/pop指令。
第三,流水线的设计规则没有实现可以操作内存变量的指令。缓存或者内存的数据只有在流水线的第四阶段才能够获得。对于ALU而言,这些数据来得太迟了。内存访问仅通过简单的load/store指令来将数据导入或导出寄存器。




参考:
wiki:Computer architecture / Multi-core processor / Instruction set architecture
《大话处理器》《各种通讯总线介绍》
《MIPS体系结构透视》《MIPS体系结构》《MIPS体系结构的特点》
《RISC与CISC比较》《CISC與RISC之比較》《CISC与RISC的区别》
《完全看透ARM处理器:RISC与CISC是什么?历史、架构一次看透》
《ARM 与 MIPS 比较》《ARM与X86 CPU架构对比区别》
《ARM vs X86 – Key differences explained! 》
《Baring It All to Software: Raw Machines》