分布式存储要点分析
- 引言
- 1 宏观架构
- 1.1 交互关系
- 1.2 可改进项
- 2 监控中心
- 2.1 Pull状态
- 2.2 Observe状态
- 2.3 Work状态
- 2.3.1 节点竞选
- 2.3.2 写数据流程
- 2.3.3 数据修复
- 2.3.4 节点替换
- 3 虚拟节点
- 3.1 数据写入
- 3.2 数据迁移
- 3.3 分裂节点
- 3.4 合并节点
- 4 物理节点
引言
分布式存储和分布式计算是云计算的基石,分布式计算以AP为主、而分布式存储则以CP为主。前者一方面是特定场景不需要太高的一致性,另一方面即便是需要高一致性、也借助持久化层去实现高一致性,所以分布式计算设计考虑更多以AP为主;相对地,分布式存储作为数据持久化的最后一道关卡,不得不对一致性做到高可靠。这也使得分布式存储的设计门槛较高。
目前开源的分布式存储系统很多,其中以HDFS和Ceph最常被提及。本文会提及到两个开源存储系统,但不会深入细节,本文重点阐述怎么设计一款分布式存储系统、分布式存储设计需要重点考虑的一些方面等自研分析。
1 宏观架构
HDFS是一款分布式的FS系统,只提供文件存储应用;而ceph则一款分布式存储系统,对外提供文件存储、对象存储和块存储应用。HDFS采用中心化的架构设计,而ceph采用去中心化。严格意义ceph也是中心化的,ceph也是通过monitor管理集群状态。
ceph的一些设计在理论上比较好,比如FS的元数据自包含、抽象出虚拟节点可以减少monitor的数据量、通过算法避免客户端每次请求访问monitor,但是理想往往与现实存在差异,例如ceph的状态管理比较冗余累赘、过于依赖算法定位而弱化了虚拟节点的定位作用。
设计一款后端分布式存储系统通常需要包含四部分:状态监控、物理节点、虚拟节点、客户端。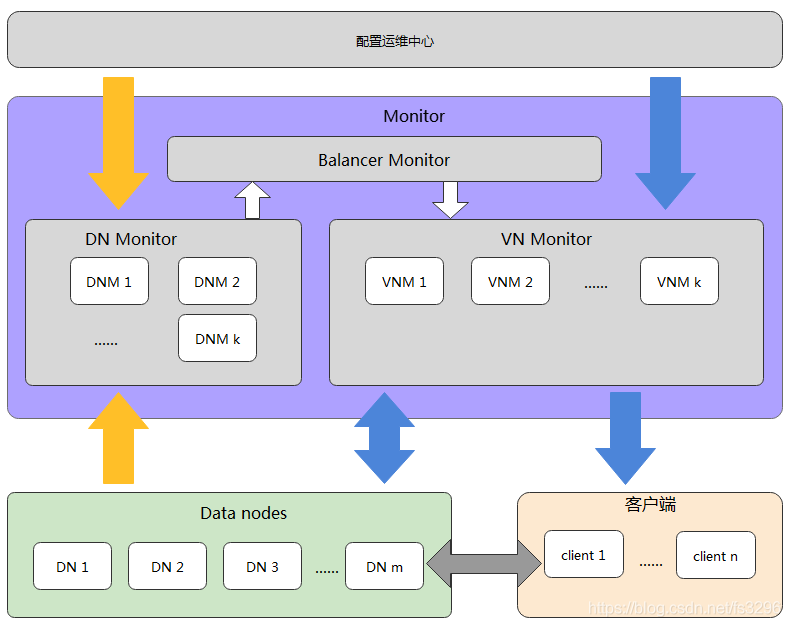
注:本图及后续不会涉及其上提供块、文件和对象应用部分。可理解为我们只讲述类似ceph的rados部分。
整个分为五块:集群状态监控Monitor、存储数据的物理节点Data Nodes、客户端、配置运维中心和集群平衡器Balancer Monitor。在逻辑上数据通过一致哈希算法存储在虚拟节点中,然后数据迁移/备份等都以虚拟节点为单位进行,所以集群状态又分为虚拟节点监控(VNM)和物理节点监控(DNM)。
1.1 交互关系
从交互关系看,共有八种交互:
- 客户端与VN Monitor
客户端通过定时从VN Monitor下载虚拟节点信息,然后通过一致哈希算法先映射到虚拟节点,然后通过最新的虚拟节点信息去请求物理节点。注:这一点与ceph不太一致。 - Data Node与DN Monitor
Data Node会定时向DN Monitor上报自己的状态。 - Data Node与VN Monitor
Data Node定时向VN Monitor拉取与自己相关的虚拟节点信息;同时,也会在运行过程中修改自己管理的虚拟节点信息。 - 配置中心与DN Monitor
配置中心是运行人员的操作入口,通过配置中心添加和移除物理节点。 - 配置中心与VN Monitor
虚拟节点数目决定了数据负载平衡度,一般虚拟节点按2的倍数扩展或收缩。这些都是通过配置中心与VN Monitor进行的 - Balancer Monitor与DN Monitor
Balancer Monitor实时拉取物理节点状态,用于计算承载虚拟节点的Data Node。 - Balancer Monitor与VN Monitor
Balancer Monitor算出承载虚拟节点的Data Node后,会实时写入到VN Monitor中。 - Data Node与Data Node
物理节点与物理节点之间以虚拟节点为单位读写数据、迁移数据。
1.2 可改进项
图中,Balancer Monitor负责向VN Monitor写入虚拟节点的再平衡数据,然后由Data Node定时检查更新与自己相关的虚拟节点信息。为了让Data Node快速检查到VN Monitor的更新,一种方式是加快Data Node刷新频率,另一种方式可以让Balancer Monitor在产生了再平衡后,向相关节点发起通知,相比较第二种方式更好。
2 监控中心
对于集群状态的监控管理采用raft或paxzos算法实现分布式一致性,一般优先选择raft算法。DN Monitor和VN Monitor为两个独立的raft集群,一般可按照LSM结合Wisckey的方式优化本地存储读写性能。
在底层LSM存储引擎中,存取正式成员列表和观察成员列表,假定,key为members的value是正式成员列表;key为obversers的value是观察成员列表。正式成员列表中的节点会参与raft竞选和用于主节点判断是否过半写入;观察成员列表只接受主节点的心跳,但主节点不会主动向观察成员发送数据写入。由观察成员自己去从节点或主节点拉取已提交的数据。
节点加入raft集群到移除raft集群的整个过程如下:
- 一个节点在加入前,是既不在obversers中,又不在members;
- 在执行加入操作后,先Pull数据,待数据与主节点相差不多时(假设10个sequence),就向主节点发起将自己写入到obversers中;
- 然后等同步到obversers包含自己的时候就切换到观察状态,然后用观察成员替换正式成员;
- 被替换的节点会从members移到obversers,然后可以选择将obversers中成员清空。最终,整个流程实现闭环。
注1:members中的节点必须先转移到obversers,不能直接删除。
注2:关于替换操作,例如替换前members=[node1, node2, node3, node4, node5],obversers=[node6,node7,node8],执行[node6,node7]替换[node3, node4]后members=[node1, node2, node5, node6, node7],obversers=[node3,node4,node8]。此外,替换节点数组和被替换节点数组可以有一个是空,前者为空表示移除成员,后者为空表示添加成员,都不为空表示既有添加又有移除。
Monitor物理节点运行状态机如下: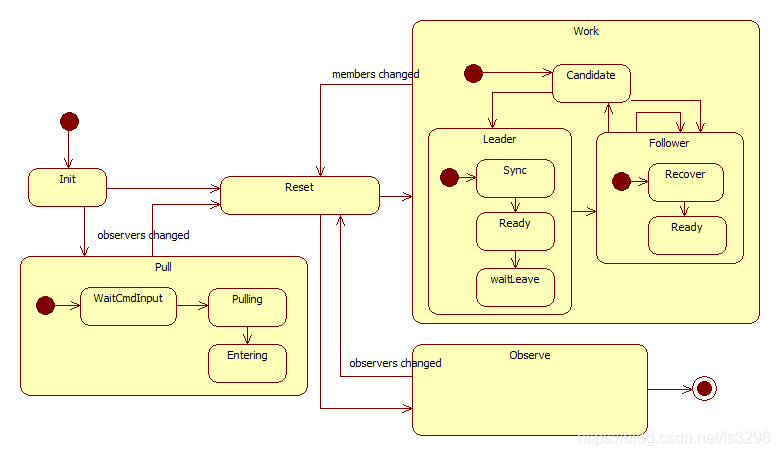
- 启动后,先进入Init状态执行数据初始化,但与传统LSM存储引擎(例如leveldb)不同的是:初始化到最后的一条WriteBatch就不会更新其LastSequence,因为最后一条数据是否被提交、还是在后面被丢掉是需要后续完成才可确定。所以LastSequence只能递增到最后一条WriteBatch的起始Sequeue减一;
- 当init初始化完毕后,若当前节点在正式成员(members)或在观察成员(obversers)中,就会进入Reset状态;否则进入Pull状态;
- 进入Reset状态后,判断当前节点若在正式成员(members),就会进入Work状态;否则就在观察成员(obversers)中,则进入Observe状态;
进入到Reset状态,当前节点要么在正式成员(members)中,要么在观察成员(obversers)中,不会出现第三种情况。 - 对于Work状态,只有members改变就会进入Reset状态(可能当前节点还在members中,或在obversers中);对于Observe状态,若当前节点在members或obversers中,就会进入Reset状态,否则说明自己已经被正式移除而结束运行。
2.1 Pull状态
Pull状态主要处理节点加入obversers的过程:
- 首先进入WaitCmdInput子状态,等待用户输入加入的集群主节点,因为当前本地没有数据,无法正式成员信息。
- 然后进入Pulling子状态,全量同步数据;
- 当全量同步到与主节点相差不大(假设10个sequence)时,最后进入Entering子状态。
- 进入Entering子状态后,向主节点发起写入操作将自己写入到obversers。
- 继续同步数据,直到同步到自己写入obversers这条记录导致自己满足进入Reset状态的条件,触发observers changed事件。
2.2 Observe状态
进入Observe状态,可能由两种情况产生:一是节点加入,二是节点移除。
无论是那种情况,Observe状态的节点都会接受主节点的心跳,然后根据主节点的心跳中的last_sequence信息去拉取缺失的数据。
特别地,Observe状态的节点会接受数据读取请求,因为当节点移除时,新替换的成员可能由于数据同步延迟,还没有正式接管集群。
注:在Observe状态,若发现自己被移入到members中,就会切换到Reset;若发现自己既不在members也不在obversers中,就会结束运行。
2.3 Work状态
Work状态是整个raft的运行过程:
- 进入Work后首先进入Candidate子状态发起竞选;若收到新主节点心跳切入Follower子状态,若自己竞选成功就会切入Leader子状态;
- 处于Leader子状态的节点可能会收到新的主节点心跳,这时是被其他主节点发起新的term抢夺。此时,被抢夺主导地位的节点就会直接切入到Follower子状态;
- 处于Follower子状态的节点也可能接收新的主节点心跳,这时就会重新切换到自己,也就是说重新执行Recover到Ready的流程;此外,当超时没有收到主节点心跳时,就会切入Candidate子状态重新竞选主节点。
注:在整个Work状态,若同步到members改变(以正式提交为准),就会切换到Reset。此外,与Observe不同的是:无论自己是否在members中,只要members改变就会切换到Reset。这样做的目的是实现节点切换的无缝过度。
2.3.1 节点竞选
节点竞选过程是raft选主过程。与常规raft选主不同的是:
- 这里的选主信息包含任期主版本main_term、任期子版本sub_term、发起节点的最新members序号members_sequence。其中main_term是发起竞选节点的最后一条数据的sequence;sub_term每次竞选递增;members_sequence是为了在正式节点替换过程中用做区分是否为新的正式成员列表选出的主节点发出的心跳;
- 主节点的心跳信息必须包括:选择成功时的参数main_term、选择成功时的参数sub_term、选择成功时的参数members_sequence和当前自己的last_sequence。节点收到心跳,如果发现心跳发送者的members sequence过期,需要给予错误响应;
- 每个正式成员响应竞选的返回数据,除了包含状态信息,还要包括自己已提交的最大sequence,即last_sequence;响应节点拒绝main_term小于本地最后一条记录的sequence的竞选请求(也就是数据不是最新); 响应节点拒绝members_sequence小于本地已提交members最新sequence的竞选请求(也就是members过期);
- 每个节点竞选失败且是因为members_sequence过期导致,会向last_sequence返回值最大的节点拉取丢失的数据。这是为了防止节点替换过程中,多数节点完成接替,少数节点因为网络延迟出现状态迁移的中断。
2.3.2 写数据流程
写数据请求是在Leader或Follower的Ready状态处理,其他任何状态都不会处理数据写入请求。主从节点处理数据写入的过程如下(本图忽略了参数校验和一些合法性检查过程):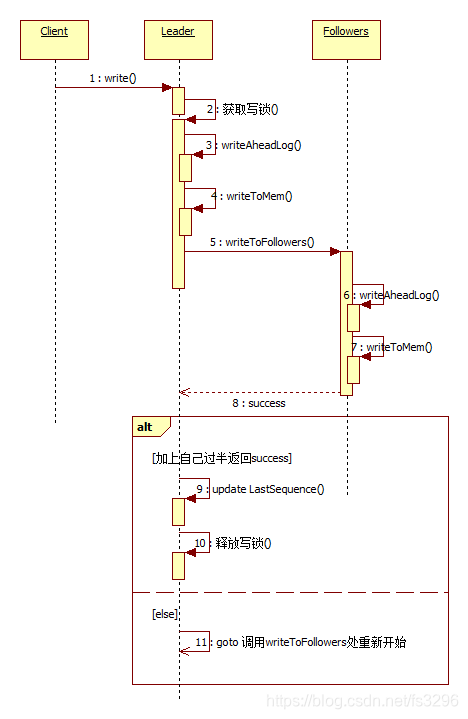
注1:主从节点同步数据必须包括发起者的元信息:任期主版本main_term、任期子版本sub_term、发起节点的最新members序号members_sequence。
注2:从节点在接收主节点心跳的过程中,如果心跳信息里面last_sequence大于当前的LastSequence就会更新自己的LastSequence;此外,在writeToFollowers时也会带主节点的last_sequence,所以在下次写入的时候也会更新从节点的LastSequence。
2.3.3 数据修复
数据修复是节点刚选主完毕,主节点进行Sync、从节点进行Recover的过程。
- 对于Leader状态,进入后需要先切入Leader/Sync子状态,进行对最后一条数据的重新同步和提交。完成后才会切换到Leader/Ready;
- 对于Follower状态,进入后需要先切入Follower/Recover,向主节点拉取本地的最后一条WriteBatch,进行比对,如果不一致就会丢弃掉本地的最后一条WriteBatch。最后完成这一步后才会正式切换到Follower/Ready。
需要数据修复是因为:从节点不知道本地最后一条WriteBatch是否已过半提交,没有的话就可能被丢弃;主节点也不知道最后一条WriteBatch是否已过半提交,没有的话就必须进行过半同步。例如:节点1,2,3,4,5组成集群,1是主节点,大家最后一条WriteBatch的sequence都是10,此时主节点1写入了新的WriteBatch,且只同步给了节点2就宕机。此时2到5都有可能选主成功,若2是从节点就需要丢弃掉sequence大于10的记录,若2是主节点就需要重新提交最后一条WriteBatch。
2.3.4 节点替换
节点替换就是修改members和obversers过程,本质上是写入数据操作的一个特殊流程。
- 对于从节点,当接收到主节点对members和obversers的put写入后,等待更新到其LastSequence大于等于这条记录的最后sequence(也就是其正式在本地提交),就会触发members changed事件,然后切换到到Reset状态
- 对于主节点,当本地提交后,不会立刻触发members changed事件。这时会先切换到Leader/waitLeave子状态,然后不接受任何写入,但此时会接受读取。在同步心跳过程中,当过半节点收到心跳后响应members过期,才会触发members changed事件,然后切换到到Reset状态。特别地,若提前收到新term的主节点心跳,会提前切入到Reset。
注:节点最后通过Reset切换到Observe状态后,要加入的节点还可能存在同步延迟,所以在Observe状态的节点会提供数据读取请求。
3 虚拟节点
虚拟节点是存储数据、备份数据、迁移数据的基本单位。数据不直接存储到物理节点,中间通过虚拟节点为纽带来隔离数据的内部存储/备份/迁移细节,相当于起到数据和物理位置的解耦。
在详细介绍虚拟节点前,先解决几个问题:
- 当集群机器增多或减少时,怎么增加和减少虚拟节点来实现调整负载均衡?
虚拟节点的总个数按2的倍数扩展和收缩,这么做是为了方便数据的分裂和合并。虚拟节点总个数由mask决定,mask = 虚拟节点总个数 – 1。mask转换为二进制后,其1的位数代表虚拟节点的编码位数,如下图:
由上图可知,虚拟节点的标识符由两部分组成:一部分是mask;另一部分是二进制编码转换后的整数。例如(mask=3,code=0)与(mask=7,code=0)不是一个节点。最终虚拟节点的合并和分裂以2的倍数分组进行。
- 当某个虚拟节点分布在物理节点A、B、C三台上,客户端怎么知道它当前的位置?若A宕机后,根据算法需要将虚拟节点分布在B、C、D,那么VN Monitor怎么记录D迁移数据的过程?整个迁移过程中,可能D也会中途宕机,如果只记录虚拟节点当前位置,那么可能造成数据丢失,怎么保证数据的完备性?
虚拟节点的关键状态信息都是记录在VN Monitor,然后各个Data Node同步。由VN Monitor构建raft集群确保数据的一致性。
VN Monitor维护的每个虚拟节点VN的数据结构如下:
相关属性:
- VNId:是虚拟节点的编码值,相同mask情况下VNId唯一,在VN Monitor中不可能存在VNId相同、mask不同的情况,所以能保证其唯一性;
- mask:其值加1是虚拟节点最大数量;
- locateSet:当前最新、最全数据的物理承载节点成员;
- activeSet:当前应该迁移到的物理节点成员;
- move:大于零,正在执行分裂操作,小于零,正在执行合并操作。例如当前mask=0b1111,move=3,分裂后mask=0b1111111;若mask=0b1111,move= -3,合并后mask=0b1;
- splitedVNs:若move大于0,在被分裂的虚拟节点的该字段填充:分裂后虚拟节点ID列表;
- mergeVNs:若move小于0,在被合入前后VNId相等的虚拟节点的该字段填充:被合入的虚拟节点ID列表;
VNInfo信息修改,一般由以下情况产生:
- 当客户端向VN Monitor请求VNInfo,若该VNId的VNInfo不存在,就会向Balancer Monitor请求计算这个VNInfo的activeSet信息,然后VN Monitor写入返回的VNInfo,并返回给客户端;
- 当Balancer Monitor监听到DN Monitor状态改变,就会计算各个已经在VN Monitor创建的VNInfo的activeSet,然后向VN Monitor写入activeSet改变后的VNInfo;
- 当Data Node在读写、迁移虚拟节点时,会修改相关VNInfo的信息;
- 当虚拟节点数量修改时,Balancer Monitor会分裂或合并VNInfo,这个过程相对前面修改单个VNInfo而言,比较耗时,但一般集群不会经常调整虚拟节点数目。
注:修改VNInfo分为无条件修改和有条件修改。无条件修改就是直接Put,而有条件修改与sql的where方式update类似,需要判断VNInfo没有更改则Put。VNInfo按KV方式存储,key是VNId,value为VNInfo。由于每次写入带sequence版本信息,所以从VN Monitor拉取数据时会附带写入时的sequence一并返回;当Data Node或Balancer Monitor向VN Monitor发起有条件修改时,在请求中带上要更新的旧sequence,然后VN Monitor判断该sequence是否还是最新(也就是说是否没有被修改),如果是最新的就真正Put,反之返回错误码和被抢先新修改的VNInfo。
各个Data Node向VN Monitor拉取自己相关的VNInfo(也就是locateSet或activeSet包含自己)发生变化,然后做出相关操作。每个虚拟节点围绕着VNInfo按如下的状态机在Data Node上面运行: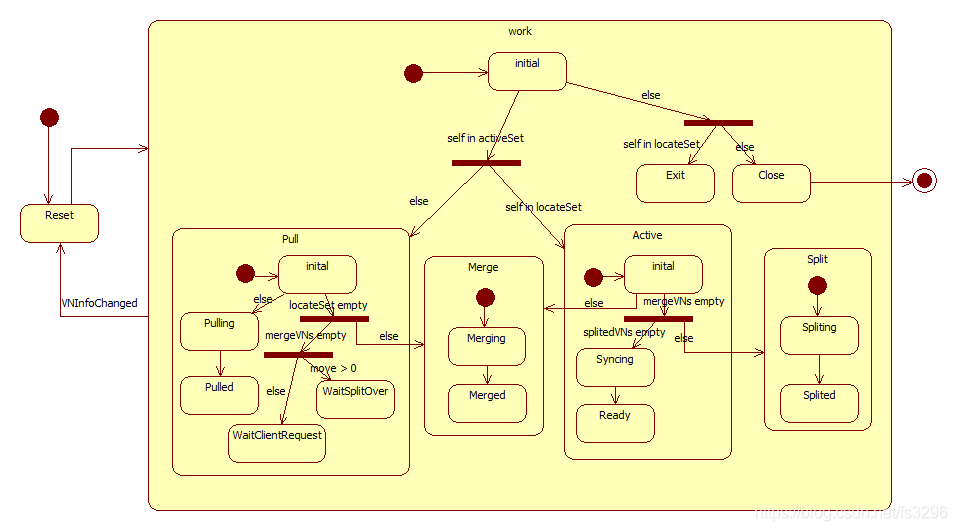
从最顶层看,整个状态机是Reset和Work相互切换的过程。Reset状态读取最新的VNInfo到状态机,然后切换到Work状态;Work状态如果后台检查到VNInfo改变(也就是当前VNInfo有新写入)就会切换到Reset,然后再由切回Work,开始新的Work的工作流。
Work工作流程是处理数据读写、数据迁移、虚拟节点合并和分裂操作,整个流程由VN Monitor的强一致性实现逻辑闭环:
- 首先,进入子initial状态,在其中判断当前节点是否在activeSet或locateSet。若在activeSet、不在locateSet中,则进入Pull子状态迁移数据;若在activeSet、也在locateSet中,则进入Active子状态中;若不在activeSet、但在locateSet中,则进入Exit子状态中,此时还不能删除数据,需要等待activeSet里面的节点过来迁移数据;若不在activeSet、也不在locateSet中,则进入Close子状态,此时可以清理资源和结束状态机运行。
- 在Pull状态,首先进入Pull/inital子状态,根据VNInfo信息判断切入下级状态。若locateSet为空、mergeVNs不空(此时move必小于0),则进入Merge状态进行数据合并;若locateSet为空、mergeVNs也为空、move大于0,则进入Pull/WaitSplitOver等待虚拟节点分裂完毕(分裂完毕VN Monitor会收到更新VNInfo的locateSet,触发切换);若locateSet为空、mergeVNs也为空、move不大于0(move必等于0),则进入Pull/WaitClientRequest等待客户端请求(说明这是刚刚创建的VNInfo,处于activeSet的第一个Data Node在收到客户端请求后,向VN Monitor发起有条件修改VNInfo的locateSet);若locateSet不为空,则进入Pull/Pulling全量拉取数据。
在Pull/Pulling阶段,根据locateSet去拉取数据;当数据拉取完毕后,进入Pull/Pulled。在activeSet、但不在locateSet的第一个Data Node在Pull/Pulled阶段会向VN Monitor发起有条件修改VNInfo的locateSet为activeSet。 - 在Active状态,首先进入Active/inital子状态,根据VNInfo信息判断切入下级状态。若mergeVNs不为空,则进入Merge状态;若mergeVNs为空、splitedVNs不为空,则进入Split状态;若mergeVNs为空、splitedVNs也为空,则进入Active/Syncing同步数据,将各个active状态的Data Node一致。
在Active/Syncing阶段,同步一致后,就会切换到Active/Ready状态,此时可以正常处理客户端的读写请求了。 - 在Merge状态,首先进入Merging,根据mergeVNs信息,将它们的数据全量拉取的本地;然后待数据拉完进入Merged,首节点会向VN Monitor发起有条件修改当前的VNInfo(例如修改mask和move归零以及清空mergeVNs等)、删除被合入的VNInfo。
- 在Split状态,首先进入Spliting,根据splitedVNs信息,将当前VN的数据分裂成splitedVNs中的虚拟节点;然后待分裂完成,首节点会向VN Monitor发起有条件修改当前VNInfo(例如修改mask和move归零以及清空splitedVNs等)、创建分裂的VNInfo。
3.1 数据写入
整个数据写入关键有三部分:客户端向VN Monitor查询VNInfo、客户端向VNInfo中的activeSet的首物理节点发起请求、VNInfo的activeSet列表的物理节点写入数据。
- 客户端向VN Monitor查询VNInfo
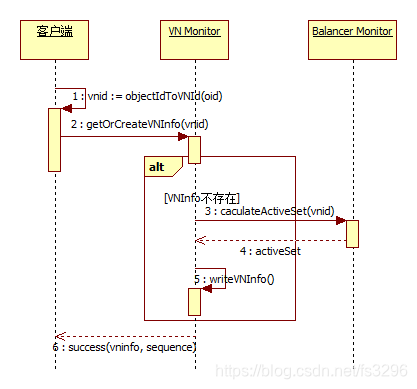
注1:此时创建的VNInfo其locateSet为空、move=0、splitedVNs和mergeVNs为空。例如当前虚拟节点容量为8、请求vnid=2,返回的vninfo={VNId=2, mask=0b111, locateSet=[], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]}。
注2:若VNInfo在VN Monitor第一次新建,物理节点DN_A, DN_B, DN_C会刷新到这条VNInfo记录,根据前面的状态机最终切换到Work/Pull/WaitClientRequest状态等待客户端第一次请求。
- 客户端向VNInfo中的activeSet的首物理节点发起请求
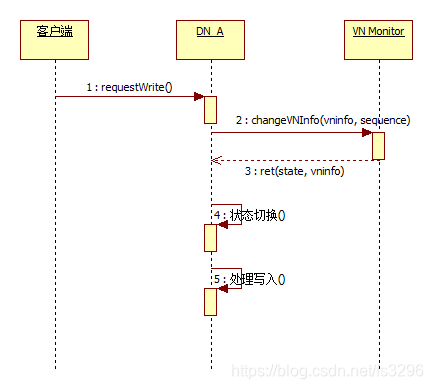
注1:此时修改VNInfo的locateSet。结合前面的举例:前虚拟节点容量为8、vninfo={VNId=2, mask=0b111, locateSet=[], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]},修改后vninfo={VNId=2, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]}
注2:修改VNInfo后会导致DN_A, DN_B, DN_C关于这个VNInfo的状态机切换,最后切换到Work/Active/Ready就可以正式处理读写请求了
注3:DN_A修改VNInfo前假设VNInfo的最新sequence=100,在修改时发现其最新sequence不等于100就会修改失败,然后返回被其他端修改的VNInfo然后也会触发状态机运行
注4:客户端与物理节点交互会带上VNInfo的sequence信息,两边验证sequence的新旧来确定刷新VNInfo和通知对方刷新。这一点与ceph比较Epoch版本思想类似
- VNInfo的activeSet列表的物理节点写入数据
物理节点DN_A, DN_B, DN_C之间进行数据同步写入分为链式写入和主从写入。hdfs是链式写入;ceph是主从写入。前者有利于利用网络带宽、后者实时性高,所以HDFS的文件分片较大、ceph的分片相对较小(默认只有4M)。
无论是链式写入,还是主从写入。节点之间传输数据必须带上VNInfo的VNId和sequence信息,这样来保证状态一致性。
3.2 数据迁移
整个数据迁移包含:Balancer Monitor更新VNInfo的activeSet、物理节点切换状态机迁移数据、Pull首节点向VNInfo更新VNInfo的locateSet。
- Balancer Monitor更新VNInfo的activeSet
结合前面的例子,假设物理节点DN_A和DN_C宕机。此时,Balancer Monitor检查到VD Monitor的变化,就会重新计算上面的VNInfo的activeSet。假设新计算的activeSet为[DN_B, DN_D, DN_E],然后向VN Monitor把{VNId=2, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]}改为{VNId=2, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_B, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]}。注:此时locatSet还没有改变。
- 物理节点切换状态机迁移数据
前面VNInfo的变化,必然被物理节点DN_B, DN_D, DN_E更新到。然后就会触发他们状态转换,最终DN_B进入Work/Active/Syncing等待同步,DN_D, DN_E进入Work/Pull/Pulling子状态。DN_D, DN_E在Work/Pull/Pulling状态中向DN_B发起全量数据拉取(DN_A和DN_C已经宕机)。当拉取完数据,DN_D, DN_E切入到Work/Pull/Pulled。
- Pull首节点向VNInfo更新VNInfo的locateSet
DN_D, DN_E切入到Work/Pull/Pulled后,DN_D作为Pull首节点(也就是activeSet中处于Pull最前面的节点),会向VN Monitor把{VNId=2, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_B, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]}更改为{VNId=2, mask=0b111, locateSet=[DN_B, DN_D, DN_E], activeSet=[DN_B, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]}。特别地,此处的更改与前面数据写入时的更改一样需要带上sequence判断VNInfo是否被其他节点修改过,若修改过就会返回错误和被提前修改的VNInfo。
当修改VNInfo后,会导致DN_B, DN_D, DN_E都重新切换到Work/Active/Syncing进行数据同步。之所以需要同步数据是在物理节点之间写入同步时会出现:只写入部分出现断连、宕机的情况。数据同步分为主从同步和链式同步。前者比较简单,就是active首节点负责将所有节点同步到与最新的节点一致,active从节点直接进行Work/ActiveReady;后者是每个节点负责将自己后面的节点的最新数据拉到自己合并,然后推送给后面数据较旧的节点。最后,无论那种方式,所有节点都会切换到Work/ActiveReady提供客户端的读写请求。
最后,整个数据迁移的过程都是无条件修改activeSet和有条件修改locateSet保证数据完备性。
3.3 分裂节点
分裂节点包括:Balancer Monitor根据VN Monitor的VNInfo发起分裂、物理节点执行分裂、activeSet首节点向VN Monitor提交分裂完成。
- Balancer Monitor根据VN Monitor的VNInfo发起分裂
Balancer Monitor检查到虚拟节点容量扩大后,就会修改VN Monitor中已创建的VNInfo的move和splitedVNs信息。
例如:之前的虚拟节点总容量为8,mask=0b111。存在的VNInfo如下:
{VNId=0, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]}
{VNId=2, mask=0b111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]}
{VNId=6, mask=0b111, locateSet=[DN_D, DN_E, DN_F], activeSet=[DN_D, DN_E, DN_F], move=0, splitedVNs=[], mergeVNs=[]}
其他虚拟节点还没有创建。。。。。。
现在虚拟节点容量调整到16,mask=0b1111。Balancer Monitor依次分三次事务提交到VN Monitor,依次如下:
事务1:Put {VNId=0, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=1, splitedVNs=[0, 8], mergeVNs=[]};Put {VNId=8, mask=0b111, locateSet=[], activeSet=[DN_A, DN_B, DN_C], move=1, splitedVNs=[], mergeVNs=[]};
事务2:Put {VNId=2, mask=0b111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=1, splitedVNs=[2, 10], mergeVNs=[]};Put {VNId=10, mask=0b111, locateSet=[], activeSet=[DN_C, DN_D, DN_E], move=1, splitedVNs=[], mergeVNs=[]};
事务3:Put {VNId=6, mask=0b111, locateSet=[DN_D, DN_E, DN_F], activeSet=[DN_D, DN_E, DN_F], move=1, splitedVNs=[6, 14], mergeVNs=[]};Put {VNId=14, mask=0b111, locateSet=[], activeSet=[DN_D, DN_E, DN_F], move=1, splitedVNs=[], mergeVNs=[]};
注:上面每个事务的Put都是有条件Put,会比较Put的VNInfo有没有被Data Node更新。
- 物理节点执行分裂
当执行完Balancer Monitor根据VN Monitor的VNInfo发起分裂后,Data Node会执行状态机转换。前面的VNId等于8、10、14的虚拟节点在承载的物理节点上会切换到Work/Put/WaitSplitOver状态;VNId等于0、2、6的虚拟节点在承载的物理节点会切换到Work/Split/Spliting状态进行数据分裂。
- activeSet首节点向VN Monitor提交分裂完成
以VNId等于2的虚拟节点为例:当执行完分裂后切换到Work/Split/Splited状态,节点DN_C作为首节点会向VN Monitor发起一个事务写入:
Put {VNId=2, mask=0b1111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]};Put {VNId=10, mask=0b1111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]};
当事务写入到VN Monitor后也会触发每个虚拟节点在其承载的物理节点上的状态切换,最终会切换到Work/Active/Ready状态。
注:这个事务的Put都是有条件Put,会比较Put的VNInfo有没有被Data Node更新。
最后,Balancer Monitor和Data Node修改VNInfo都会由VN Monitor检查是否被其他节点修改,这样确保一致性。若被其他节点修改,比如因为节点宕机引起active变化用于再平衡,这时的数据分裂操作会转移到新平衡的节点。待新平衡的节点迁移完数据后继续分裂虚拟节点。
3.4 合并节点
与分裂节点类似,合并节点包括:Balancer Monitor根据VN Monitor的VNInfo发起合并、物理节点执行合并、activeSet首节点向VN Monitor提交合并完成。
- Balancer Monitor根据VN Monitor的VNInfo发起合并
Balancer Monitor检查到虚拟节点容量缩小后,就会修改VN Monitor中已创建的VNInfo的move和mergeVNs信息。
例如:之前的虚拟节点总容量为8,mask=0b1111。存在的VNInfo如下:
{VNId=0, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=0, splitedVNs=[], mergeVNs=[]}
{VNId=2, mask=0b111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]}
{VNId=6, mask=0b111, locateSet=[DN_D, DN_E, DN_F], activeSet=[DN_D, DN_E, DN_F], move=0, splitedVNs=[], mergeVNs=[]}
{VNId=5, mask=0b111, locateSet=[DN_E, DN_F, DN_G], activeSet=[DN_E, DN_F, DN_G], move=0, splitedVNs=[], mergeVNs=[]}
其他虚拟节点还没有创建。。。。。。
现在虚拟节点容量调整到4,mask=0b11。Balancer Monitor依次分三次事务提交到VN Monitor,依次如下:
事务1:Put {VNId=0, mask=0b111, locateSet=[DN_A, DN_B, DN_C], activeSet=[DN_A, DN_B, DN_C], move=-1, splitedVNs=[], mergeVNs=[0]};
事务2:Put {VNId=2, mask=0b111, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=-1, splitedVNs=[], mergeVNs=[2, 6]};Put {VNId=6, mask=0b111, locateSet=[DN_D, DN_E, DN_F], activeSet=[], move=-1, splitedVNs=[], mergeVNs=[]};
事务3:Put {VNId=1, mask=0b111, locateSet=[], activeSet=[DN_L, DN_M, DN_N], move=-1, splitedVNs=[], mergeVNs=[5]};{VNId=5, mask=0b111, locateSet=[DN_E, DN_F, DN_G], activeSet=[], move=-1, splitedVNs=[], mergeVNs=[]};
注:上面每个事务的Put都是有条件Put,会比较Put的VNInfo有没有被Data Node更新。此外上面合入后需要丢弃的节点会把activeSet置空(将丢弃的节点在合并过程中拒绝客户端的读写请求)。
- 物理节点执行合并
当执行完Balancer Monitor根据VN Monitor的VNInfo发起合并后,Data Node会执行状态机转换。前面的VNId等于5、6的虚拟节点在locateSet相关的物理节点上会切换到Work/Exit状态,等待数据合并;VNId等于0、1、2的虚拟节点在承载的物理节点会切换到Work/Merge状态进行数据合并,其中VNId等于1的节点通过Pull切换到Merge、而0和2号节点通过Active切换到Merge。
进入Merge状态后,首先进入Work/Merge/Merging状态。在该状态,当前虚拟节点通过mergeVNs中的VNid列表依次找到它们的locateSet去拉取数据,然后合并到当前虚拟节点。
- activeSet首节点向VN Monitor提交合并完成
同样,以VNId等于2的虚拟节点为例:当执行完合并后切换到Work/Merge/Merged状态,节点DN_C作为首节点会向VN Monitor发起一个事务写入:
Put {VNId=2, mask=0b11, locateSet=[DN_C, DN_D, DN_E], activeSet=[DN_C, DN_D, DN_E], move=0, splitedVNs=[], mergeVNs=[]};Delete {VNId=6};
当事务写入到VN Monitor后也会触发每个虚拟节点在其承载的物理节点上的状态切换,最终合并后的节点会切换到Work/Active/Ready状态响应客户端请求、删除的节点会切换到Work/Close状态清理存储空间等资源。
注:这个事务的Put或Delete都是有条件Put,会比较Put或Delete的VNInfo有没有被Data Node更新。
与分裂节点一样,Balancer Monitor和Data Node修改VNInfo都会由VN Monitor检查是否被其他节点修改,这样确保一致性。
4 物理节点
wisckey




