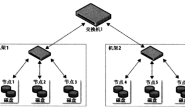
MapReduce的运行流程:
容错机制:
1,重复执行
2,推测执行
hadoop运行状态进程有SecondaryNameNode、NameNode、DateNode、TaskTracker、JobTracker
WordCount demo使用:
1/ java -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar -d word_count_class/ WordCount.java
3/ jar -cvf wordcount.jar *.class 打包 生成打包文件wordcount.jar
4/ hadoop fs -mkdir input_wordcount
5/ 输入文件hadoop fs -put input/* input_wordcount/
6/ hadoop fs -ls 查看存放位置
7/ hadoop fs -ls input_wordcount 查看存放的文件
8/ hadoop fs -cat input_wordcount/file 查看存放文件
9/ hadoop jar word_count_class/wordcount.jar WordCount input_wordcount cutput_wordcount
10/ hadoop fs -ls output_wordcount
11/ hadoop fs -cat output_wordcount/par-r-00000