虽然通过改写Not in Subquery的SQL,进行低效率的SQL到高效率的SQL过渡,能够避免上面所说的问题。但是这往往建立在我们发现任务执行慢甚至失败,然后排查任务中的SQL……继续阅读 » 5年前 (2021-04-01) 1481浏览 0评论1676个赞
聚类算法是机器学习中的一种无监督学习算法,它在数据科学领域应用场景很广泛,比如基于用户购买行为、兴趣等来构建推荐系统。核心思想可以理解为,……继续阅读 » 5年前 (2021-04-01) 1716浏览 0评论521个赞
推荐系统是根据用户的行为、兴趣等特征,将用户感兴趣的信息、产品等推荐给用户的系统,它的出现主要是为了解决信息过载和用户无明确需求的问题,根据划分标准的不同,又分很多种类别……继续阅读 » 5年前 (2021-03-31) 2405浏览 0评论1100个赞
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜、job数分配的不合理、磁盘或网络I/O过高、MapReduce配置的不合理等……继续阅读 » 5年前 (2021-03-29) 3440浏览 0评论1671个赞
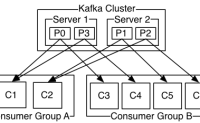
通过之前的文章《Kafka分区分配策略》和《Kafka高性能揭秘》,我们了解到:Kafka高吞吐量的原因之一就是通过partition将topic中的消息保存到Kafka集群中不同的broker中。无……继续阅读 » 6年前 (2021-02-03) 3166浏览 0评论1254个赞
众所周知,Catalyst Optimizer是Spark SQL的核心,它主要负责将SQL语句转换成最终的物理执行计划,在一定程度上决定了SQL……继续阅读 » 6年前 (2021-01-29) 2137浏览 0评论1930个赞
众所周知,Apache Kafka是基于生产者和消费者模型作为开源的分布式发布订阅消息系统(当然,目前Kafka定位于an open-source distributed event streamin……继续阅读 » 6年前 (2021-01-26) 3039浏览 0评论2234个赞