创建Simulink环境并训练智能体
- 水箱模型
- 创建环境界面
- 创建DDPG智能体
- 训练智能体
- 验证训练的智能体
- 本地函数
本示例说明如何在watertank Simulink®模型中转换PI控制器。使用强化学习深度确定性策略梯度(DDPG)智能体。
水箱模型
此示例的原始模型是水箱模型。目的是控制水箱中的水位。

通过进行以下更改来修改原始模型:
删除PID控制器。
插入RL Agent块。
连接观察向量 [ ∫ e d t e h ] ,在 h hh是水箱的高度e = r − h 和$r $是参考高度。
设置奖励 奖励= 10 ( ∣ e ∣ < 0.1 ) − 1 ( ∣ e ∣ ≥ 0.1 ) − 100 ( h ≤ 0 ∣ ∣ h ≥ 20 ) 。
配置终止信号,以使仿真在以下情况下停止 h ≤ 0 要么 h ≥ 20 。
创建模型
open_system('rlwatertank')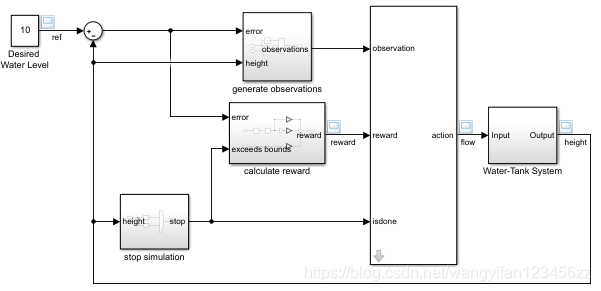
创建环境界面
创建环境模型包括定义以下内容:
1.智能体用来与环境交互的动作和观察信号。
2.智能体用奖励信号来衡量其是否成功。
obsInfo = rlNumericSpec([3 1],...
'LowerLimit',[-inf -inf 0 ]',...
'UpperLimit',[ inf inf inf]');
obsInfo.Name = 'observations';
obsInfo.Description = 'integrated error, error, and measured height';
numObservations = obsInfo.Dimension(1);
actInfo = rlNumericSpec([1 1]);
actInfo.Name = 'flow';
numActions = actInfo.Dimension(1);
构建环境接口对象。
env = rlSimulinkEnv('rlwatertank','rlwatertank/RL Agent',...
obsInfo,actInfo);设置自定义重置功能,以随机化模型的参考值。
env.ResetFcn = @(in)localResetFcn(in);以秒为单位指定模拟时间Tf和智能体采样时间Ts。
Ts = 1.0;
Tf = 200;
修复随机生成器种子以提高可重复性。
rng(0)创建DDPG智能体
给定观察结果和操作,DDPG代理使用评论者价值函数表示近似长期奖励。要创建评论者,首先要创建一个具有两个输入的深度神经网络,即观察和动作,以及一个输出。有关创建深度神经网络值函数表示的更多信息,请参见创建策略和值函数表示。
statePath = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
fullyConnectedLayer(50,'Name','CriticStateFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(25,'Name','CriticStateFC2')];
actionPath = [
imageInputLayer([numActions 1 1],'Normalization','none','Name','Action')
fullyConnectedLayer(25,'Name','CriticActionFC1')];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','CriticOutput')];
criticNetwork = layerGraph();
criticNetwork = addLayers(criticNetwork,statePath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticStateFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActionFC1','add/in2');观察评论者网路的配置。
figure
plot(criticNetwork)

使用指定评论者表示的选项rlRepresentationOptions。
criticOpts = rlRepresentationOptions('LearnRate',1e-03,'GradientThreshold',1);使用指定的深度神经网络和选项创建评论者表示。您还必须指定评论者的操作和观察规范,您可以从环境界面中获得该规范。
critic = rlQValueRepresentation(criticNetwork,obsInfo,actInfo,'Observation',{'State'},'Action',{'Action'},criticOpts);给定观察结果,DDPG智能体使用参与者表示来决定要采取的动作。要创建角色,首先要创建一个具有一个输入(观察)和一个输出(动作)的深度神经网络。
以类似于评论家的方式构造行动者。
actorNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
fullyConnectedLayer(3, 'Name','actorFC')
tanhLayer('Name','actorTanh')
fullyConnectedLayer(numActions,'Name','Action')
];
actorOptions = rlRepresentationOptions('LearnRate',1e-04,'GradientThreshold',1);
actor = rlDeterministicActorRepresentation(actorNetwork,obsInfo,actInfo,'Observation',{'State'},'Action',{'Action'},actorOptions);要创建DDPG智能体,请首先使用来指定DDPG智能体选项rlDDPGAgentOptions。
agentOpts = rlDDPGAgentOptions(...
'SampleTime',Ts,...
'TargetSmoothFactor',1e-3,...
'DiscountFactor',1.0, ...
'MiniBatchSize',64, ...
'ExperienceBufferLength',1e6);
agentOpts.NoiseOptions.Variance = 0.3;
agentOpts.NoiseOptions.VarianceDecayRate = 1e-5;然后,使用指定的参与者表示,评论者表示和智能体选项创建DDPG智能体。
agent = rlDDPGAgent(actor,critic,agentOpts);训练智能体
要训练智能体,请首先指定训练选项。对于此示例,使用以下选项:
每次训练最多进行5000次。指定每个情节最多持续200时间。
在“情节管理器”对话框中显示训练进度(设置Plots选项),并禁用命令行显示(将Verbose选项设置为false)。
当智能体在20个连续情节中获得的平均累积奖励大于800时,请停止训练。此时,药剂可以控制水箱中的水位。
maxepisodes = 5000;
maxsteps = ceil(Tf/Ts);
trainOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes, ...
'MaxStepsPerEpisode',maxsteps, ...
'ScoreAveragingWindowLength',20, ...
'Verbose',false, ...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',800);使用train功能训练智能体。训练是一个计算密集型过程,需要几分钟才能完成。为了节省运行本示例的时间,请通过将设置doTraining为来加载预训练的智能体false。要自己训练智能体,请设置doTraining为true。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('WaterTankDDPG.mat','agent')
end
验证训练的智能体
通过仿真针对模型验证学习的智能体。
simOpts = rlSimulationOptions('MaxSteps',maxsteps,'StopOnError','on');
experiences = sim(env,agent,simOpts);
本地函数
function in = localResetFcn(in)
% randomize reference signal
blk = sprintf('rlwatertank/Desired \nWater Level');
h = 3*randn + 10;
while h <= 0 || h >= 20
h = 3*randn + 10;
end
in = setBlockParameter(in,blk,'Value',num2str(h));
% randomize initial height
h = 3*randn + 10;
while h <= 0 || h >= 20
h = 3*randn + 10;
end
blk = 'rlwatertank/Water-Tank System/H';
in = setBlockParameter(in,blk,'InitialCondition',num2str(h));
end

![[强化学习实战]函数近似方法与原理](https://blog.75271.com/wp-content/themes/com75271/timthumb.php?src=/Uploads/Editor/202103/20210318_59417.png&h=110&w=185&q=90&zc=1&ct=1)
