- 一、skimage及opencv-python库的安装
-
- 1、skimage库的安装
- 2、opencv-python库的安装
- 二、face_recognition的下载及安装
-
- 1、安装相关依赖
- 2、pip3的安装、升级及换源
- 3、face_recognition的下载
- 4、扩展
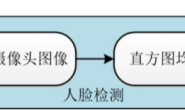
- 四、实现摄像头人脸检测
-
- 1、摄像头人脸检测python代码
- 2、接入笔记本的摄像头
- 3、摄像头人脸检测结果
在人工智能的深入学习中,我们逐渐进入人脸识别的算法学习,当然,这也是嵌入式领域需要着手解决的问题,本次博客,林君学长讲带大家了解如何在Ubuntu16.04系统上面,通过python3+dlib实现基础人脸识别和笔记本摄像头的人脸检测,一起看步骤吧!
- Ubuntu版本:ubuntuKylin-16.04
- Python版本:python3.5
- Dlib版本:dlib-19.2.0
一、skimage及opencv-python库的安装
1、skimage库的安装
1)、安装skimage库所需要的依赖库
sudo apt-get install python-numpy
sudo apt-get install python-scipy
sudo apt-get install python-matplotlib
以上的库,只是为了skimage库的安装做准备,当然,后续我们也会用到这些库 2)、安装skimage库
sudo pip3 install scikit-image
2、opencv-python库的安装
sudo pip3 install opencv-python
通过以上步骤,我们的skimage库以及opencv-python库就安装好了,接下来,我们进行人脸识别库的安装吧!
二、face_recognition的下载及安装
face_recognition库是进行人脸识别重要的库,所以然而,该库除了一些必要的依赖之外,最重要的就是他会下载dlib库,通过dlib可以进行人脸识别和检测,
1、安装相关依赖
sudo apt-get install build-essential cmake
sudo apt-get install libgtk-3-dev
sudo apt-get install libboost-all-dev
 林君学长之前安装过所以显示如上图,小伙伴按照上面安装就好!
林君学长之前安装过所以显示如上图,小伙伴按照上面安装就好!
2、pip3的安装、升级及换源
由于Ubuntu自带版本是python2.7和python3.5,因此,pip对应是python2.7,而pip3对应的则是python3.5,本次我们需要的python环境是python3,因此,我们需要进行的pip3的安装 1)、pip3的安装
sudo apt-get install python3-pip
以上安装方法安装的pip3是老版本的,是pip8点几,所以我们需要进行pip3的升级 2)、pip3的升级
sudo pip3 install --upgrade pip
3)、查看pip3的版本
pip -V
 4)、切换pip3为国内源 为了加快下载速度,我们需要对pip3进行换源,加快我们其他库的下载速度
4)、切换pip3为国内源 为了加快下载速度,我们需要对pip3进行换源,加快我们其他库的下载速度
mkdir ~/.pip
touch ~/.pip/pip.conf
sudo gedit ~/.pip/pip.conf
文件内容写为如下清华园就好:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
到这里,我们pip3的安装就完成了,接下来,我们需要的就是face_recognition的下载啦:
3、face_recognition的下载
1)、通过https://pypi.douban.com/simple/ 网站下载,不能够直接下载,否则不会下载成功
pip3 install -i https://pypi.douban.com/simple/ face_recognition
 该库会帮助我们下载numpy、scipy、dlib以及pillow库,因此,下载时间会久一点,但由于我们换源,所以不会太久,唯一等待过久的就是dlib下载后,他会自动进行编译,这需要耗费一点时间,我们等待dlib编译完成就好 通过以上步骤,我们的face_recognition人脸识别包就安装好了,接下来,我们进行其他相关库的安装吧!
该库会帮助我们下载numpy、scipy、dlib以及pillow库,因此,下载时间会久一点,但由于我们换源,所以不会太久,唯一等待过久的就是dlib下载后,他会自动进行编译,这需要耗费一点时间,我们等待dlib编译完成就好 通过以上步骤,我们的face_recognition人脸识别包就安装好了,接下来,我们进行其他相关库的安装吧!
4、扩展
1)、以上安装的重点其实是对dlib库的安装,其他库下载比较简单,这里林君学长给出dlib的另一种安装方法,当以上安装出错的时候,我们不妨试一下以下方法进行dlib源码编译 2)、dlib源码包的下载
git clone https://github.com/davisking/dlib.git
3)、dlib源码包的编译
cd dlib
mkdir build
cd build
cmake ..
cmake --build .
![]() 编译出现百分百就可以成功了哦! 4)、当然,除了dlib有源码包之外,face_recognition也有源码,可以下载编译后安装,但是不推荐该库的此种安装方法,因为下载得实在是太慢了
编译出现百分百就可以成功了哦! 4)、当然,除了dlib有源码包之外,face_recognition也有源码,可以下载编译后安装,但是不推荐该库的此种安装方法,因为下载得实在是太慢了
pip3 install -i https://pypi.douban.com/simple/ face_recognition
下载巨慢,以上的方法已经可以解决本次的问题了哦!
三、实现基础人脸识别
1、项目创建及数据准备
1)、创建项目 在自己喜欢的位置创建一个项目文件夹,用于存放,我们编写的python代码及数据,以林君学长自己的为准,小伙伴们自己创建就好
cd ~/lenovo
mkdir python人脸识别
cd python人脸识别
2)、dlib的68点模型,使用网络上大神训练好的特征预测器
 该数据就是以上的face.dat模型,林君学长已经将该模型上传到csdn我的资源模块,小伙伴可以通过如下链接进行下载: https://download.csdn.net/download/qq_42451251/12525399 3)、人脸准备
该数据就是以上的face.dat模型,林君学长已经将该模型上传到csdn我的资源模块,小伙伴可以通过如下链接进行下载: https://download.csdn.net/download/qq_42451251/12525399 3)、人脸准备
 对于人脸的选取,百度图片可以解决一切,随便百度一张漂亮的夏普姐姐就好!数据准备完成,全部放在我们创建的目录下哦,接下来我们就开始
对于人脸的选取,百度图片可以解决一切,随便百度一张漂亮的夏普姐姐就好!数据准备完成,全部放在我们创建的目录下哦,接下来我们就开始

2、基础人脸识别python代码
在项目中创建基础人脸识别的python文件faceDetection.py,并打开,写入代码:
touch faceDetection.py
gedit faceDetection.py
1)、导入基本库
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
import cv2
import dlib
from skimage import io
sys.path.remove(’/opt/ros/kinetic/lib/python2.7/dist-packages’) 该句代码是因为林君学长Ubuntu16.04上安装过ROS,而ROS默认设置的为python2.7,所以,我们首先需要将ROS设置的python2.7的路径移除,才能继续使用我们python3.5! 提示:sys.path.remove(’/opt/ros/kinetic/lib/python2.7/dist-packages’)代码一定要放在import cv2之前 2)、dlib图像设置
# 使用特征提取器get_frontal_face_detector
detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
predictor = dlib.shape_predictor("face.dat")
# 图片所在路径
img = io.imread("my.jpg")
# 生成dlib的图像窗口
win = dlib.image_window()
win.clear_overlay()
win.set_image(img)
# 特征提取器的实例化
dets = detector(img, 1)
3)、人脸识别结果展示及终端打印识别结果
print("人脸数:", len(dets))
for k, d in enumerate(dets):
print("第", k + 1, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
width = d.right() - d.left()
heigth = d.bottom() - d.top()
print('人脸面积为:', (width * heigth))
# 利用预测器预测
shape = predictor(img, d)
# 标出68个点的位置
for i in range(68):
cv2.circle(img, (shape.part(i).x, shape.part(i).y), 4, (0, 255, 0), -1, 8)
cv2.putText(img, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
# 显示一下处理的图片,然后销毁窗口
cv2.imshow('face', img)
3、人脸识别结果
1)、运行faceDetection.py代码
python3 faceDetection.py
2)、运行结果如下所示:

4、整体python代码
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
import cv2
import dlib
from skimage import io
# 使用特征提取器get_frontal_face_detector
detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
predictor = dlib.shape_predictor("face.dat")
# 图片所在路径
img = io.imread("my.jpg")
# 生成dlib的图像窗口
win = dlib.image_window()
win.clear_overlay()
win.set_image(img)
# 特征提取器的实例化
dets = detector(img, 1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
print("第", k + 1, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
width = d.right() - d.left()
heigth = d.bottom() - d.top()
print('人脸面积为:', (width * heigth))
# 利用预测器预测
shape = predictor(img, d)
# 标出68个点的位置
for i in range(68):
cv2.circle(img, (shape.part(i).x, shape.part(i).y), 4, (0, 255, 0), -1, 8)
cv2.putText(img, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
# 显示一下处理的图片,然后销毁窗口
cv2.imshow('face', img)
cv2.waitKey(0)
接下来,我们便可以进行摄像头的人脸检测了,一起来看吧!
四、实现摄像头人脸检测
1、摄像头人脸检测python代码
在项目中创摄像头人脸检测的python文件face2.py,并打开,写入代码:
touch face2.py
gedit face2.py
1)、由于代码中写入注释,所以林君学长直接给出全部代码
"""
从视屏中识别人脸,并实时标出面部特征点
"""
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
import dlib # 人脸识别的库dlib
import numpy as np # 数据处理的库numpy
import cv2 # 图像处理的库OpenCv
class face_emotion():
def __init__(self):
# 使用特征提取器get_frontal_face_detector
self.detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
self.predictor = dlib.shape_predictor("face.dat")
# 建cv2摄像头对象,这里使用电脑自带摄像头,如果接了外部摄像头,则自动切换到外部摄像头
self.cap = cv2.VideoCapture(0)
# 设置视频参数,propId设置的视频参数,value设置的参数值
self.cap.set(3, 480)
# 截图screenshoot的计数器
self.cnt = 0
def learning_face(self):
# 眉毛直线拟合数据缓冲
line_brow_x = []
line_brow_y = []
# cap.isOpened() 返回true/false 检查初始化是否成功
while (self.cap.isOpened()):
# cap.read()
# 返回两个值:
# 一个布尔值true/false,用来判断读取视频是否成功/是否到视频末尾
# 图像对象,图像的三维矩阵
flag, im_rd = self.cap.read()
# 每帧数据延时1ms,延时为0读取的是静态帧
k = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY)
# 使用人脸检测器检测每一帧图像中的人脸。并返回人脸数rects
faces = self.detector(img_gray, 0)
# 待会要显示在屏幕上的字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 如果检测到人脸
if (len(faces) != 0):
# 对每个人脸都标出68个特征点
for i in range(len(faces)):
# enumerate方法同时返回数据对象的索引和数据,k为索引,d为faces中的对象
for k, d in enumerate(faces):
# 用红色矩形框出人脸
cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0, 0, 255))
# 计算人脸热别框边长
self.face_width = d.right() - d.left()
# 使用预测器得到68点数据的坐标
shape = self.predictor(im_rd, d)
# 圆圈显示每个特征点
for i in range(68):
cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8)
# cv2.putText(im_rd, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
# (255, 255, 255))
# 分析任意n点的位置关系来作为表情识别的依据
mouth_width = (shape.part(54).x - shape.part(48).x) / self.face_width # 嘴巴咧开程度
mouth_higth = (shape.part(66).y - shape.part(62).y) / self.face_width # 嘴巴张开程度
# print("嘴巴宽度与识别框宽度之比:",mouth_width_arv)
# print("嘴巴高度与识别框高度之比:",mouth_higth_arv)
# 通过两个眉毛上的10个特征点,分析挑眉程度和皱眉程度
brow_sum = 0 # 高度之和
frown_sum = 0 # 两边眉毛距离之和
for j in range(17, 21):
brow_sum += (shape.part(j).y - d.top()) + (shape.part(j + 5).y - d.top())
frown_sum += shape.part(j + 5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y)
# self.brow_k, self.brow_d = self.fit_slr(line_brow_x, line_brow_y) # 计算眉毛的倾斜程度
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线
self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的
brow_hight = (brow_sum / 10) / self.face_width # 眉毛高度占比
brow_width = (frown_sum / 5) / self.face_width # 眉毛距离占比
# print("眉毛高度与识别框高度之比:",round(brow_arv/self.face_width,3))
# print("眉毛间距与识别框高度之比:",round(frown_arv/self.face_width,3))
# 眼睛睁开程度
eye_sum = (shape.part(41).y - shape.part(37).y + shape.part(40).y - shape.part(38).y +
shape.part(47).y - shape.part(43).y + shape.part(46).y - shape.part(44).y)
eye_hight = (eye_sum / 4) / self.face_width
# print("眼睛睁开距离与识别框高度之比:",round(eye_open/self.face_width,3))
# 分情况讨论
# 张嘴,可能是开心或者惊讶
if round(mouth_higth >= 0.03):
if eye_hight >= 0.056:
cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
# 没有张嘴,可能是正常和生气
else:
if self.brow_k <= -0.3:
cv2.putText(im_rd, "angry", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
# 标出人脸数
cv2.putText(im_rd, "Faces: " + str(len(faces)), (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
else:
# 没有检测到人脸
cv2.putText(im_rd, "No Face", (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
# 添加说明
im_rd = cv2.putText(im_rd, "S: screenshot", (20, 400), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
im_rd = cv2.putText(im_rd, "Q: quit", (20, 450), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
# 按下s键截图保存
if (k == ord('s')):
self.cnt += 1
cv2.imwrite("screenshoot" + str(self.cnt) + ".jpg", im_rd)
# 按下q键退出
if (k == ord('q')):
break
# 窗口显示
cv2.imshow("camera", im_rd)
# 释放摄像头
self.cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()
if __name__ == "__main__":
my_face = face_emotion()
my_face.learning_face()
2、接入笔记本的摄像头
1)、打开ubuntu16.04,进入图像界面后,选择VM上面的用户看,右击,选择可移动设备
 上图中是我自己的摄像头名称,小伙伴的可能不一样,然后再圈圈4中点击连接,我的是连接好的,所以显示断开连接,小伙伴们最开始应该是连接
上图中是我自己的摄像头名称,小伙伴的可能不一样,然后再圈圈4中点击连接,我的是连接好的,所以显示断开连接,小伙伴们最开始应该是连接
3、摄像头人脸检测结果
1)、运行摄像头人脸检测python文件
python3 face2.py
2)、运行结果如下所示: (1)、检测到人脸
 林君学长自己笔记本电脑摄像头像素不高,请见谅! (2)、未检测到人脸 S截图保存、Q退出摄像头人脸识别 以上就是本次博客的全部内容啦,希望小伙伴们对本次博客的阅读可以帮助大家深入了解基础人脸检测,了解检测原理,实现基本的人脸检测的编写 遇到问题的小伙伴记得评论区留言,林君学长看到会为大家解答的,这个学长不太冷! 陈一月的又一天编程岁月^ _ ^
林君学长自己笔记本电脑摄像头像素不高,请见谅! (2)、未检测到人脸 S截图保存、Q退出摄像头人脸识别 以上就是本次博客的全部内容啦,希望小伙伴们对本次博客的阅读可以帮助大家深入了解基础人脸检测,了解检测原理,实现基本的人脸检测的编写 遇到问题的小伙伴记得评论区留言,林君学长看到会为大家解答的,这个学长不太冷! 陈一月的又一天编程岁月^ _ ^