风起云涌的大数据战场上,早已迎百花齐放繁荣盛景,各大企业加速跑向“大数据时代”。而我们作为大数据的践行者,在这个“多智时代”如何才能跟上大数据的潮流,把握住大数据的发展方向。 前言 大数据起源于200……继续阅读 » 5年前 (2021-04-07) 2592浏览 0评论1287个赞
阅读本文小建议:本文适合细嚼慢咽,不要一目十行,不然会错过很多有价值的细节。 文章首发于公众号:五分钟学大数据 前言 在进行数仓搭建和数据分析时最常用的就是 sql,其语法简洁明了,易于理解,目前大数……继续阅读 » 5年前 (2021-04-07) 2820浏览 0评论150个赞
🧡先来一个问题,也是面试中常问的: Spark为什么会流行? 原因1:优秀的数据模型和丰富计算抽象 Spark 产生之前,已经有MapReduce这类非常成熟的计算系统存在了,……继续阅读 » 5年前 (2021-04-07) 2183浏览 0评论660个赞
HBase简介 HBase 是一个分布式的、面向列的开源数据库。建立在 HDFS 之上。Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库。HBase 的计算和存储能力……继续阅读 » 5年前 (2021-04-01) 3125浏览 0评论684个赞
Kafka 简介 Apache Kafka 是一个分布式发布-订阅消息系统。是大数据领域消息队列中唯一的王者。最初由 linkedin 公司使用 scala 语言开发,在2010年贡献给了Apache……继续阅读 » 5年前 (2021-03-31) 1622浏览 0评论1038个赞
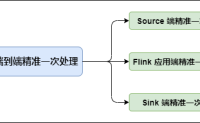
前言 Flink 是流式的、实时的 计算引擎 上面一句话就有两个概念,一个是流式,一个是实时。 流式:就是数据源源不断的流进来,也就是数据没有边界,但是我们计算的时候必须在一个有边界的范围内进行,所以……继续阅读 » 5年前 (2021-03-29) 2613浏览 0评论2079个赞
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优……继续阅读 » 5年前 (2021-03-29) 3088浏览 0评论2102个赞
超详细,纯干货!……继续阅读 » 6年前 (2021-02-01) 2301浏览 0评论397个赞
Spark简介 Apache Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,……继续阅读 » 6年前 (2021-01-29) 3125浏览 0评论2431个赞
hive窗口函数/分析函数 在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的。但是有时……继续阅读 » 6年前 (2021-01-21) 3287浏览 0评论785个赞