SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
一、支持向量与超平面
在了解svm算法之前,我们首先需要了解一下线性分类器这个概念。比如给定一系列的数据样本,每个样本都有对应的一个标签。为了使得描述更加直观,我们采用二维平面进行解释,高维空间原理也是一样。举个简单子:如下图所示是一个二维平面,平面上有两类不同的数据,分别用圆圈和方块表示。我们可以很简单地找到一条直线使得两类数据正好能够完全分开。但是能将据点完全划开直线不止一条,那么在如此众多的直线中我们应该选择哪一条呢?从直观感觉上看图中的几条直线,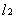
二、SVM算法原理
2.1 点到超平面的距离公式
既然这样的直线是存在的,那么我们怎样寻找出这样的直线呢?与二维空间类似,超平面的方程也可以写成一下形式:
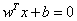
有了超平面的表达式之后之后,我们就可以计算样本点到平面的距离了。假设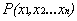

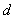
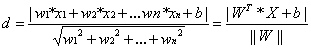
其中||W||为超平面的范数,常数b类似于直线方程中的截距。
上面的公式可以利用解析几何或高中平面几何知识进行推导,这里不做进一步解释。
2.2 最大间隔的优化模型
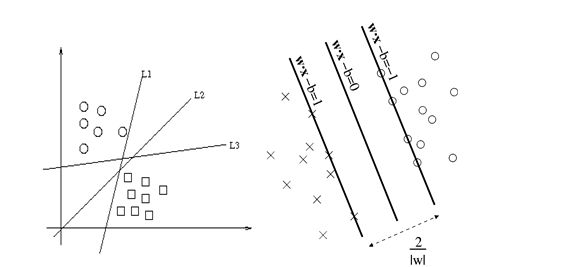
现在我们已经知道了如何去求数据点到超平面的距离,在超平面确定的情况下,我们就能够找出所有支持向量,然后计算出间隔margin。每一个超平面都对应着一个margin,我们的目标就是找出所有margin中最大的那个值对应的超平面。因此用数学语言描述就是确定w、b使得margin最大。这是一个优化问题其目标函数可以写成:
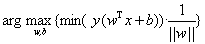
其中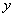
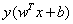
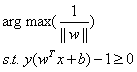
为了后面计算的方便,我们将目标函数等价替换为:
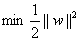
这是一个凸二次规划问题。能直接用现成的优化计算包求解,但我们可以有更高效的办法。
2.3 学习的对偶算法
为了求解线性可分支持向量机的最优化问题,将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,这就是线性可分支持向量的对偶算法。这样的优点:
对偶问题往往更容易求解
自然引入核函数,进而推广到非线性分类问题
改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
首先构建拉格朗日函数。为此,对每个不等式约束引进拉格朗日乘子$a_{i}\geq 0,i=1,2,…,N$,定义拉格朗日函数:
$L(w,b,a)=\frac{1}{2}\left \| w \right \|^{2}-\sum_{i=1}^{N}a\left [ (w^{T}+b)-1 \right ]$ (6)
其中$a_{i}> 0$。
根据拉格朗日函数对偶性,原始问题的对偶问题是极大极小问题:
$max_{a}min_{w,b}L(w,b,a)$ (7)
所以,为了求解问题的解,需要先求求$L(w,b,a)$对$w,b$的极小,再求对$a$的极大。
(1) 求$min_{w,b}L(w,b,a)$
将拉格朗日函数$L(w,b,a)$分别对$w,b$求偏导数令其等于0:
$\bigtriangledown _{w}L(w,b,a)=w-\sum_{i=1}^{N}a_{i}y_{i}x_{i}=0$ (8)
$\bigtriangledown _{b}L(w,b,a)=\sum_{i=1}^{N}a_{i}y_{i}=0$ (9)
得:
$w=\sum_{i=1}^{N}a_{i}y_{i}x_{i}$(10)
$\sum_{i=1}^{N}a_{i}y_{i}=0$(11)
将式(10)代入拉格朗日函数(6)并利用式(11),即得:
$L(w,b,a)=\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}x_{j})-\sum_{i=1}^{N}a_{i}\left [ y_{i} \right ((\sum_{j=1}^{N}a_{i}y_{j}x_{j})x_{i}+b)-1]+\sum_{i=1}^{N}a_{i}
=-\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (12)
(2) 求$max_{w,b}L(w,b,a)$对$a$的极大
$max_{a} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (13)
subject to
$\sum_{i=1}^{N}a_{i}y_{i}=0$
$a_{i}\geq 0,i=1,2,…,N$
将上式的目标函数由极大转换成极小,就得到下面与之等价的对偶最优化问题:
$min_{a} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (14)
subject to
$\sum_{i=1}^{N}a_{i}y_{i}=0$
$a_{i}\geq 0,i=1,2,…,N$
从对偶问题解出的是原式中的拉格朗日乘子。注意到原式中有不等式约束,因此上述过程需要满足KKT条件,即要求:
$\left\{\begin{matrix}
a_{i}\geq 0\\
y_{i}f(x_{i})-1\geq 0\\
a_{i}(y_{i}f(x_{i})-1)=0
\end{matrix}\right.$ (15)
于是,对于训练数据$(x_{i},y_{i})$,总有$a_{i}=0$或$y_{i}f(x_{i})=1$。若$a_{i}=0$,则该样本不会出现在上述求和公式中,也就不会对$f(x)$产生任何影响;若$a_{i}>0$则必有$y_{i}f(x_{i})=1$,所对应样本点位于最大间隔上,是一个支撑向量。这里显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量相关。
那么如何求解式(14)不难发现,这是一个二次规划问题,可使用通用的二次规划算法求解;然而,该问题的规模正比于训练样本数,这会在实际任务中造成很大的开销。为了避开这个障碍,人们通过利用问题本身的特性,提出了很多高校的算法,SMO(Sequential Minimal Optimization)是其中一个著名的代表。
2.4 松弛变量
由上一节的分析我们知道实际中很多样本数据都不能够用一个超平面把数据完全分开。如果数据集中存在噪点的话,那么在求超平的时候就会出现很大问题。从下图中可以看出其中一个蓝点偏差太大,如果把它作为支持向量的话所求出来的margin就会比不算入它时要小得多。更糟糕的情况是如果这个蓝点落在了红点之间那么就找不出超平面了。
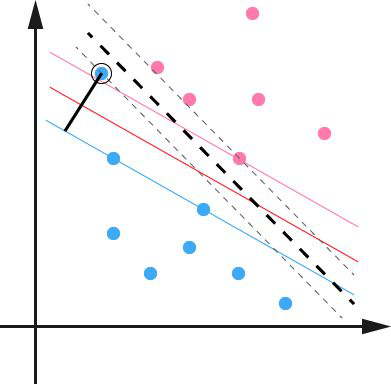
因此引入一个松弛变量ξ来允许一些数据可以处于分隔面错误的一侧。这时新的约束条件变为:
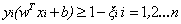
式中ξi的含义为允许第i个数据点允许偏离的间隔。如果让ξ任意大的话,那么任意的超平面都是符合条件的了。所以在原有目标的基础之上,我们也尽可能的让ξ的总量也尽可能地小。所以新的目标函数变为:
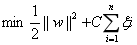
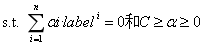
其中的C是用于控制“最大化间隔”和“保证大部分的点的函数间隔都小于1”这两个目标的权重。将上述模型完整的写下来就是:
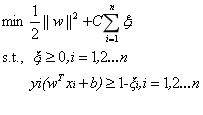
新的拉格朗日函数变为:
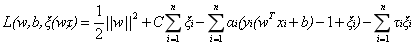
接下来将拉格朗日函数转化为其对偶函数,首先对
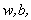
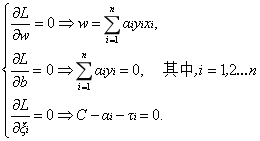
代入原式化简之后得到和原来一样的目标函数:
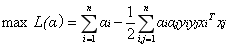
但是由于我们得到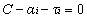
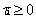
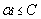
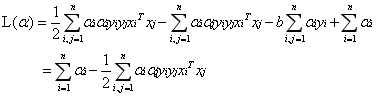
经过添加松弛变量的方法,我们现在能够解决数据更加混乱的问题。通过修改参数C,我们可以得到不同的结果而C的大小到底取多少比较合适,需要根据实际问题进行调节。
2.5核函数
以上讨论的都是在线性可分情况进行讨论的,但是实际问题中给出的数据并不是都是线性可分的,比如有些数据可能是如下图样子。
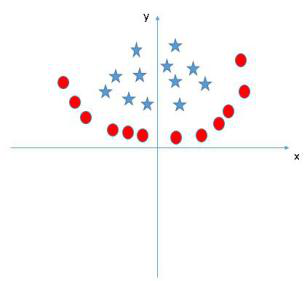
那么这种非线性可分的数据是否就不能用svm算法来求解呢?答案是否定的。事实上,对于低维平面内不可分的数据,放在一个高维空间中去就有可能变得可分。以二维平面的数据为例,我们可以通过找到一个映射将二维平面的点放到三维平面之中。理论上任意的数据样本都能够找到一个合适的映射使得这些在低维空间不能划分的样本到高维空间中之后能够线性可分。我们再来看一下之前的目标函数:
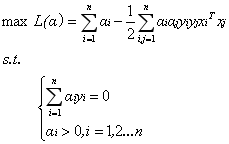
定义一个映射使得将所有映射到更高维空间之后等价于求解上述问题的对偶问题:
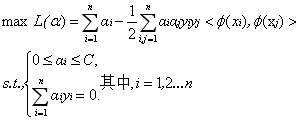
这样对于线性不可分的问题就解决了,现在只需要找出一个合适的映射即可。当特征变量非常多的时候在,高维空间中计算内积的运算量是非常庞大的。考虑到我们的目的并不是为找到这样一个映射而是为了计算其在高维空间的内积,因此如果我们能够找到计算高维空间下内积的公式,那么就能够避免这样庞大的计算量,我们的问题也就解决了。实际上这就是我们要找的核函数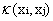
通过以上例子,我们可以很明显地看到核函数是怎样运作的。上述问题的对偶问题可以写成如下形式:
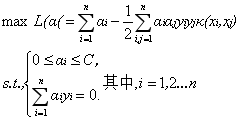
那么怎样的函数才可以作为核函数呢?下面的一个定理可以帮助我们判断。
Mercer定理:任何半正定的函数都可以作为核函数。其中所谓半正定函数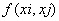
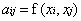
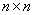
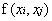
值得注意的是,上述定理中所给出的条件是充分条件而非充要条件。因为有些非正定函数也可以作为核函数。
下面是一些常用的核函数:
核函数名称 | 核函数表达式 | 核函数名称 | 核函数表达式 |
线性核 | 指数核 | ||
多项式核 | 拉普拉斯核 | ||
高斯核 | Sigmoid核 |

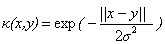
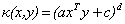
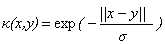
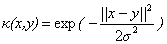
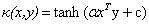
现在我们已经了解了一些支持向量机的理论基础,我们通过对偶问题的的转化将最开始求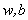
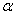
三、SMO 算法
SMO算法是支持向量机学习的一种快速算法,其特点是不断地将原二次规划问题分解为只有两个变量的二次规划子问题,并对子问题进行解析求解,知道所有变量满足KKT条件为止。这样通过启发式的方法得到原二次规划问题的最优解。因为子问题有解析解,所以每次计算子问题都很快,虽然计算子问题次数很多,但在总体上还是高效的。
参考
《统计学习方法(第2版)》 李航 著
https://zhuanlan.zhihu.com/p/31886934
https://www.cnblogs.com/xfydjy/p/9065541.html
https://www.zybuluo.com/77qingliu/note/1137445
http://www.360doc.com/content/18/0424/21/47919125_748467297.shtml