tornado简介
tornado是Python界中非常出名的一款Web框架,和Flask一样它也属于轻量级的Web框架。
但是从性能而言tornado由于其支持异步非阻塞的特性所以对于一些高并发的场景显得更为适用。
tornado简洁,高效,能够支持WebSocket,其I/O多路复用采用epoll模式来实现异步,并且还有Future期程对象来实现非阻塞。
tornado与Django和Flask等基于WSGI的框架有一个根本的区别,就是它实现socket的模块是自己写的,并不是用其他模块。
| A : socket部分 | B: 路由与视图函数对应关系(路由匹配) | C: 模版语法 | |
|---|---|---|---|
| django | 别人的wsgiref模块 | 自己写 | 自己的(没有jinja2好用 但是也很方便) |
| flask | 别人的werkzeug(内部还是wsgiref模块) | 自己写 | 别人的(jinja2) |
| tornado | 自己写的 | 自己写 | 自己写 |
起步介绍
如何编写一个最简单的tornado:
import os
import tornado.ioloop
import tornado.web
BASE_DIR = os.path.dirname(__file__)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
settings = {
"debug": True,
"template_path": os.path.join(BASE_DIR, "views"), # 存放模板的文件夹
"static_path": os.path.join(BASE_DIR, "static"), # 存放静态文件的文件夹
}
application = tornado.web.Application(
[
(r"/index", IndexHandler), # 正则匹配,路由规则
],
**settings) # 配置项
if __name__ == '__main__':
# 1.新增socket Server端,并将fp描述符添加至select或者epoll中
application.listen(8888)
# 2.循环epoll进行监听
tornado.ioloop.IOLoop.instance().start()
模板文件:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>INDEX</title>
<link rel="stylesheet" href="{{static_url('common.css')}}">
<!-- <link rel="stylesheet" href="/static/common.css">-->
</head>
<body>
<p>INDEX</p>
</body>
</html>
HTTP请求处理方式
下面将来探究Django/Flask/tornado如何处理一次HTTP请求:
Django中处理一次HTTP请求默认是以多线程模式完成。
在DJnago1.x版本之后,默认启动都是多线程形式,如果要启用单线程模式:
python manage.py runserver –nothreading
from django.shortcuts import HttpResponse
from threading import get_ident
def api1(request):
print(get_ident()) # 13246
return HttpResponse("api1")
def api2(request):
print(get_ident()) # 13824
return HttpResponse("api2")
Flask的底层其实也是wsgiref模块实现,所以处理一次HTTP请求也是以多线程。
import flask
from threading import get_ident
app = flask.Flask(__name__)
@app.route('/api1')
def api1():
print(get_ident()) # 15952
return "api1"
@app.route('/api2')
def api2():
print(get_ident()) # 15236
return "api2"
if __name__ == '__main__':
app.run()
tornado的处理方式是单线程+I/O多路复用,这意味着必须挨个挨个排队处理每一个HTTP请求:
import tornado.ioloop
import tornado.web
from threading import get_ident
class Api1Handler(tornado.web.RequestHandler):
def get(self):
print(get_ident()) # 10168
self.write("api1")
class Api2Handler(tornado.web.RequestHandler):
def get(self):
print(get_ident()) # 10168
self.write("api2")
application = tornado.web.Application([
(r"/api1",Api1Handler),
(r"/api2",Api2Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
tornado的异步
要想了解tornado的异步,就结合前面请求处理方式来看。
同步Web框架与异步Web框架的区别,这里有一篇文章写的不错:
同步与异步 Python 有何不同?
上面文章的一句话来概括就是说同步大多数都是监听一个socket对象(服务器),当服务器对象的描述符状态(可读)发生改变后,就会创建一个新的线程来处理本次请求,Django/Flask内部其实都是通过wsgiref模块实现,并且wsgiref依赖于socketserver模块。如果想了解他们如何启动多线程进行服务监听,可参照早期文章(调用方式一模一样):
socketserver使用及源码分析
而对于tornado来说,它不会创建多线程,而是将conn双向连接对象放入事件循环中予以监听。
得益于epoll的主动性,tornado的速度非常快,而在处理完conn(本次会话后),则会将conn(Socket)进行断开。 (HTTP短链接)
tornado的非阻塞
拿Django的单线程举例,当一个HTTP请求到来并未完成时,下一个HTTP请求将会被阻塞。
python manage.py runserver --nothreading
# 尝试以单线程的方式运行...对比tornado的单线程
代码如下:
from django.shortcuts import HttpResponse
import time
def api1(request):
time.sleep(5)
return HttpResponse("api1")
def api2(request):
return HttpResponse("api2")
而如果是tornado的非阻塞方式,单线程模式下即使第一个视图阻塞了,第二个视图依旧能够进行访问.
import time
import tornado.ioloop
import tornado.web
from tornado import gen
from tornado.concurrent import Future
class Api1Handler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
future = Future()
# 方式一:添加回调 五秒后执行该异步任务
tornado.ioloop.IOLoop.current().add_timeout(time.time() + 5, self.done)
# 方式二:添加future
# tornado.ioloop.IOLoop.current().add_future(future,self.done)
# 方式三:添加回调
# future.add_done_callback(self.doing)
yield future
def done(self, *args, **kwargs):
self.write('api1')
self.finish() # 完成本次HTTP请求,将future的result状态改变
class Api2Handler(tornado.web.RequestHandler):
def get(self):
self.write("api2")
application = tornado.web.Application([
(r"/api1", Api1Handler),
(r"/api2", Api2Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
有关于Future对象如何实现异步,下面会进行详细的探讨。
如何了解tornado
tornado实现异步的根本技术点:I/O多路复用的epoll模式
tornado实现非阻塞的根本技术点:Future期程(未来)对象
tornado配置项
仔细看起步介绍中,tornado的配置,它是作为关键字传参传入Application这个类中。
所以我们可以使用**{k1:v1}的方式来设定配置项,下面举例一些常见的配置项。
常规设置
常规配置项:
| 设置项 | 描述 |
|---|---|
| autoreload | 如果True,任何源文件更改时服务器进程将重新启动,如调试模式和自动重新加载中所述。此选项是Tornado 3.2中的新选项; 以前此功能由debug设置控制 |
| debug | 几种调试模式设置的简写,在调试模式和自动重新加载中描述。设置debug=True相当于autoreload=True,compiled_template_cache=False,static_hash_cache=False,serve_traceback=True |
| default_handler_class|default_handler_args | 如果没有找到其他匹配项,将使用此处理程序; 使用它来实现自定义404页面(Tornado 3.2中的新增功能) |
| compress_response | 如果True,文本格式的响应将自动压缩。Tornado 4.0的新功能 |
| gzip | compress_response自Tornado 4.0以来已弃用的别名 |
| log_function | 此函数将在每个记录结果的请求结束时调用(使用一个参数,即RequestHandler对象)。默认实现将写入logging模块的根记录器。也可以通过覆盖来定制Application.log_request。 |
| serve_traceback | 如果True,默认错误页面将包含错误的回溯。此选项是Tornado 3.2中的新选项; 以前此功能由debug设置控制 |
| ui_modules | ui_methods | 可以设置为UIModule可用于模板的映射或UI方法。可以设置为模块,字典或模块和/或dicts列表。有关详细信息,请参阅UI模块。 |
| websocket_ping_interval | 如果设置为数字,则每n秒钟将对所有websockets进行ping操作。这有助于通过关闭空闲连接的某些代理服务器保持连接活动,并且它可以检测websocket是否在未正确关闭的情况下发生故障。 |
| websocket_ping_timeout | 如果设置了ping间隔,并且服务器在这么多秒内没有收到“pong”,它将关闭websocket。默认值是ping间隔的三倍,最少30秒。如果未设置ping间隔,则忽略。 |
说点人话,debug或者autoreload为True时,修改源文件代码将会自动重启服务,相当于Django的重启功能。
而log_function则可以自定制日志的输出格式,如下所示:
def log_func(handler):
if handler.get_status() < 400:
log_method = access_log.info
elif handler.get_status() < 500:
log_method = access_log.warning
else:
log_method = access_log.error
request_time = 1000.0 * handler.request.request_time()
log_method("%d %s %s (%s) %s %s %.2fms",
handler.get_status(), handler.request.method,
handler.request.uri, handler.request.remote_ip,
handler.request.headers["User-Agent"],
handler.request.arguments,
settings = {"log_function":log_func}
身份/验证/安全
关于身份、验证、安全的配置项:
| 设置项 | 描述 |
|---|---|
| cookie_secret | 用于RequestHandler.get_secure_cookie 和set_secure_cookie签署cookie |
| key_version | set_secure_cooki 当cookie_secret是密钥字典时,requestHandler 使用特定密钥对cookie进行签名 |
| login_url | authenticated如果用户未登录,装饰器将重定向到此URL。可以通过覆盖进一步自定义RequestHandler.get_login_url |
| xsrf_cookies | 如果True,将启用跨站点请求伪造保护 |
| xsrf_cookie_version | 控制此服务器生成的新XSRF cookie的版本。通常应该保留默认值(它始终是支持的最高版本),但可以在版本转换期间临时设置为较低的值。Tornado 3.2.2中的新功能,它引入了XSRF cookie版本2 |
| xsrf_cookie_kwargs | 可以设置为要传递给RequestHandler.set_cookie XSRF cookie 的其他参数的字典 |
| twitter_consumer_key | 所用的 tornado.auth模块来验证各种API,如检测这些种类账号是否登录等… |
| twitter_consumer_secret | 同上.. |
| friendfeed_consumer_key | 同上.. |
| friendfeed_consumer_secret | 同上.. |
| google_consumer_key | 同上.. |
| google_consumer_secret | 同上.. |
| facebook_api_key | 同上.. |
| facebook_secret | 同上.. |
模板设置
模板设置项:
| 设置项 | 描述 |
|---|---|
| autoescape | 控制模板的自动转义。可以设置为None禁用转义,或者设置 应该传递所有输出的函数的名称。默认为”xhtml_escape”。可以使用该指令在每个模板的基础上进行更改。{% autoescape %} |
| compiled_template_cache | 默认是True; 如果False每个请求都会重新编译模板。此选项是Tornado 3.2中的新选项; 以前此功能由debug设置控制 |
| template_path | 包含模板文件的目录。可以通过覆盖进一步定制RequestHandler.get_template_path |
| template_loader | 分配给tornado.template.BaseLoader自定义模板加载的实例 。如果使用此 设置,则忽略template_path和autoescape设置。可以通过覆盖进一步定制RequestHandler.create_template_loader |
| template_whitespace | 控制模板中空格的处理; 查看tornado.template.filter_whitespace允许的值。Tornado 4.3中的新功能 |
静态文件
静态文件相关设置:
| 设置项 | 描述 |
|---|---|
| static_hash_cache | 默认是True; 如果False 每次请求都会重新计算静态网址。此选项是Tornado 3.2中的新选项; 以前此功能由debug设置控制 |
| static_path | 将从中提供静态文件的目录 |
| static_url_prefix | 静态文件的Url前缀,默认为/static/ |
| static_handler_class | static_handler_args | 可以设置为静态文件而不是默认文件使用不同的处理程序 tornado.web.StaticFileHandler。 static_handler_args如果设置,则应该是要传递给处理程序initialize方法的关键字参数的字典。 |
url与路由
正则匹配
在tornado中,一个url对应一个类。
匹配方式为正则匹配,因此要注意使用^与$的使用。
由于匹配行为是从上至下,所以在定义时一定要注意顺序。
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/admin
class APIHandler(tornado.web.RequestHandler):
def get(self):
self.write("...")
settings = {"debug": True}
application = tornado.web.Application([
(r"^/a.{4}$", APIHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
无名分组
使用正则分组()解析出资源请求地址的一些参数。
匹配到的参数会通过位置传参的形式传递给控制器处理函数,所以接收参数可以任意命名,因此你可以通过*args接收到所有匹配的参数:
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register/yunya
class RegisterHandler(tornado.web.RequestHandler):
def get(self,*args):
self.write(str(args)) # ('yunya',)
settings = {"debug": True}
application = tornado.web.Application([
(r"^/register/(\w+)", RegisterHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
如果确定这一被捕捉参数将被使用,则可指定形参进行接收:
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register/yunya
class RegisterHandler(tornado.web.RequestHandler):
def get(self,params):
self.write(params) # 'yunya'
settings = {"debug": True}
application = tornado.web.Application([
(r"^/register/(\w+)", RegisterHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
有命分组
使用正则的有命分组(?P<组名>规则)解析出资源请求地址的一些参数。
匹配到的参数会通过关键字传参的形式传递给控制器处理函数,所以接收参数必须与组名相同,因此你可以通过**kwargs接收到所有匹配的参数:
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register/yunya
class RegisterHandler(tornado.web.RequestHandler):
def get(self,**kwargs):
self.write(str(kwargs)) # {'username': 'yunya'}
settings = {"debug": True}
application = tornado.web.Application([
(r"^/register/(?P<username>\w+)", RegisterHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
如果确定这一被捕捉参数将被使用,则可指定形参进行接收(形参命名必须与正则匹配的组名相同):
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register/yunya
class RegisterHandler(tornado.web.RequestHandler):
def get(self,username):
self.write(username) # 'yunya'
settings = {"debug": True}
application = tornado.web.Application([
(r"^/register/(?P<username>\w+)", RegisterHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
混合使用
在tornado中,路由匹配的参数捕捉不允许无名分组和有名分组的混合使用,这会引发一个异常:
application = tornado.web.Application([
(r"^/register/(/d+)/(?P<username>\w+)", RegisterHandler),
], **settings)
抛出的错误:
AssertionError: groups in url regexes must either be all named or all positional: '^/register/(/d+)/(?P<username>\\w+)$'
分组必须全部使用位置、或者使用命名。
反向解析
反向解析要与路由命名同时使用:
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register
class RegisterHandler(tornado.web.RequestHandler):
def get(self):
print(self.reverse_url("reg")) # /register
self.write("注册页面")
settings = {"debug": True}
# 使用tornado.web.url来进行添加路由规则
application = tornado.web.Application([
tornado.web.url(r'/register', RegisterHandler, name="reg")
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
前端模板中的反向解析(必须注册名字):
{{reverse_url('reg')}}
控制器
基本概念
在MCV模型中,C代表Controller即为控制器,类似于Django中的views。
我们可以看见在tornado中,控制器处理函数都毫不意外的继承了一个叫做tornado.web.RequestHandler的对象,所有的方法都是从self中进行调用,所以你可以查看它的源码获取所有方法,或者使用help()函数获得它的DOC。
下面我将例举出一些常用的方法。
获取相关
以下是常用的获取相关属性以及方法,基本是RequestHandler中的属性、方法与self.request对象中封装的方法和属性:
| 属性/方法 | 描述 |
|---|---|
| self.request | 获取用户请求相关信息 |
| self._headers | 获取请求头信息,基本请求头被过滤 |
| self.request.headers | 获取请求头信息,包含基本请求头 |
| slef.request.body | 获取请求体信息,bytes格式 |
| self.request.remote_ip | 获取客户端IP |
| self.request.method | 获取请求方式 |
| self.request.version | 获取所使用的HTTP版本 |
| self.get_query_argument() | 获取单个GET中传递过来的参数,如果多个参数同名,获取最后一个 |
| slef.get_query_arguments() | 获取所有GET中传递过来的参数,返回列表的形式 |
| self.get_body_argument() | 获取单个POST中传递过来的参数,如果多个参数同名,获取最后一个 |
| self.get_body_arguments() | 获取所有POST中传递过来的参数,返回列表的形式 |
| self.get_argument() | 获取单个GET/POST中传递过来的参数,如果多个参数同名,获取最后一个 |
| self.get_arguments() | 获取所有GET/POST中传递过来的参数,返回列表的形式 |
| self.request.files | 获取所有通过 multipart/form-data POST 请求上传的文件 |
| self.request.host | 获取主机名 |
| self.request.uri | 获取请求的完整资源标识,包括路径和查询字符串 |
| self.request.query | 获取查询字符串的部分 |
| self.request.path | 获取请求的路径( ?之前的所有内容) |
示例演示:
import tornado.ioloop
import tornado.web
# http://127.0.0.1:8888/register?name=yunya&hobby=%E7%AF%AE%E7%90%83&hobby=%E8%B6%B3%E7%90%83
class RegisterHandler(tornado.web.RequestHandler):
def get(self):
# 获取客户端IP
print(self.request.remote_ip) # 127.0.0.1
# 查看请求方式
print(self.request.method) # GET
# 获取单个GET/POST传递的参数
print(self.get_query_argument("name")) # yunya
# 获取多个GET/POST传递的参数、list形式
print(self.get_query_arguments("hobby")) # ['篮球', '足球']
print(self.request.host) # 127.0.0.1:8888
print(self.request.uri) # register?name=yunya&hobby=%E7%AF%AE%E7%90%83&hobby=%E8%B6%B3%E7%90%83
print(self.request.path) # /register
print(self.request.query) # name=yunya&hobby=%E7%AF%AE%E7%90%83&hobby=%E8%B6%B3%E7%90%83
self.write("OK")
settings = {"debug":True}
application = tornado.web.Application([
tornado.web.url(r'/register', RegisterHandler, name="reg")
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
文件上传案例:
import tornado.ioloop
import tornado.web
class APIHandler(tornado.web.RequestHandler):
def post(self):
# step01:获取所有名为img的文件对象,返回一个列表 [img,img,img]
file_obj_list = self.request.files.get("img")
# step02:获取第一个对象
file_obj = file_obj_list[0]
# step03:获取文件名称
file_name = file_obj.filename
# step04:获取文件数据
file_body = file_obj.body
# step05:获取文件类型
file_type = file_obj.content_type
with open(f"./{file_name}",mode="wb") as f:
f.write(file_body)
self.write("OK")
settings = {"debug":True}
application = tornado.web.Application([
tornado.web.url(r'/api', APIHandler)
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
响应相关
响应一般就分为以下几种,返回单纯的字符串,返回一个模板页面,返回JSON格式数据,返回一个错误,以及重定向:
返回单纯字符串:
self.write("OK")
返回一个模板页面:
self.render("templatePath",**kwargs) # 传递给模板的数据
返回JSON格式数据(手动JSON):
import json
json_data = json.dumps({"k1":"v1"})
self.write(json_data)
返回一个错误:
self.send_error(404)
self.finish() # 结束本次请求重定向:
self.redirect("/",status=301)
响应头相关的操作:
self.set_header("k1", 1)
self.add_header("k2", 2)
self.clear_header("k1")
钩子函数
我们可以在控制器中定义一个钩子函数initialize(),并且可以在url中对他进行一些参数传递,注意这些钩子函数均不能够作为真正的拦截中间件使用,比如你想在initialize()中结束掉本次HTTP请求是不被允许的:
import tornado.ioloop
import tornado.web
class APIHandler(tornado.web.RequestHandler):
def initialize(self, *args, **kwargs) -> None:
print(kwargs) # {k1:v1}
self.data = "某个数据"
def post(self):
print(self.data) # 某个数据
self.write("ok")
settings = {"debug": True}
application = tornado.web.Application([
tornado.web.url(r'/api', APIHandler, {"k1": "v1"}), # dict -> **kwargs
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
所有的钩子函数:
class APIHandler(tornado.web.RequestHandler):
def set_default_headers(self):
print("first--设置headers")
def initialize(self):
print("second--初始化")
def prepare(self):
print("third--准备工作")
def get(self):
print("fourth--处理get请求")
def post(self):
print('fourth--处理post请求')
def write_error(self, status_code, **kwargs):
print("fifth--处理错误")
def on_finish(self):
print("sixth--处理结束,释放资源--")
模板
指定目录
在settings中指定模板所在目录,如不指定,默认在当前文件夹下:
import tornado.ioloop
import tornado.web
class APIHandler(tornado.web.RequestHandler):
def get(self):
# 找当前目录下的views文件夹,到views下去找api.html模板文件
self.render("api.html")
settings = {
"debug": True,
"template_path": "views", # 指定模板目录
"static_path": "static", # 指定静态文件目录
}
application = tornado.web.Application([
tornado.web.url(r'/api', APIHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
模板传参
tornado中的模板传参与Flask相同。
模板传参可以通过k=v的方式传递,也可以通过**dict的方式进行解包传递:
class APIHandler(tornado.web.RequestHandler):
def get(self):
context = {
"name": "云崖",
"age": 18,
"hobby": ["篮球", "足球"]
}
self.render("api.html",**context)
# self.render("api.html",name="云崖",age=18,hobby=["篮球", "足球"])
渲染,通过{{}}进行,注意:trdtmp中不支持.的深度查询访问,这点与DTL和JinJa2不同:
<body>
<p>{{name}}</p>
<p>{{age}}</p>
<p>{{hobby[0]}}-{{hobby[1]}}</p>
</body>
模板形式
模板中有两种表现形式,一种是表达式形式以{{}}进行包裹,另一种是命令形式以{% 命令 %}包裹。
注意:tornado的模板语法的结束标识是{% end %},不是Django或jinja2的{% endblock %}
举例表达式形式:
# 渲染控制器函数传入的变量
<body>
欢迎{{ username }}登录
</body>
# 进行Python表达式
{{ 1 + 1 }}
# 导入模块并使用
{{ time.time() }}
举例命令形式:
{% if 1 %}
this is if
{% end %}
如果想对命令进行注释,则可以使用{# #},如果不想执行内容,则可以使用{{! {%! {#为前缀,如下示例:
{{! 1 + 1}}
{%! if 1 %}
this is if
{%! end %}
{#! time.time() #}}
导入模块
tornado中的模板语言允许导入Python包、模块:
{% import time %}
{{ time.time() }}
{% from util.modify import mul %}
{{mul(6,6)}}
模板功能
模板中提供一些功能,可以在{{}}或者{% %}中进行使用:
| 模板调用的方法/功能/模块 | 描述 |
|---|---|
| escape | tornado.escape.xhtml_escape的别名 |
| xhtml_escape | tornado.escape.xhtml_escape的别名 |
| url_escape | tornado.escape.url_escape的别名 |
| json_encode | tornado.escape.json_encode的别名 |
| squeeze | tornado.escape.squeeze的别名 |
| linkify | tornado.escape.linkify的别名 |
| datetime | Python 的 datetime模组 |
| handler | 当前的 RequestHandler对象 |
| request | handler.request的別名 |
| current_user | handler.current_user的别名 |
| locale | handler.locale`的別名 |
| _ | handler.locale.translate 的別名 |
| static_url | for handler.static_url 的別名 |
| xsrf_form_html | handler.xsrf_form_html 的別名 |
| reverse_url | Application.reverse_url 的別名 |
| Application | 设置中ui_methods和 ui_modules下面的所有项目 |
分支循环
模板中的if判断:
{% if username != 'no' %}
欢迎{{ username }}登录
{% else %}
请登录
{% end %}
for循环:
<body>
{% for item in range(10) %}
{% if item == 0%}
<p>start</p>
{% elif item == len(range(10))-1 %}
<p>end</p>
{% else %}
<p>{{item}}</p>
{% end %}
{% end %}
</body>
while循环:
{% set a = 0 %}
{% while a<5 %}
{{ a }}<br>
{% set a += 1 %}
{% end %}
模板转义
默认的模板在渲染时都会将<与>以及空格等特殊字符替换为HTML内容,如<,>等。
关于模板转义的方式有以下几种。
1.单变量去除转义:
{{'<b>你好</b>'}} # <b>你好</b>
{% raw '<b>你好</b>' %} # <b>你好</b>
2.当前模板全局去除转义:
{% autoescape None %} # 模板首行加入
3.整个项目去掉转义,为当前的application进行配置:
settings = {
"autoescape":None, # 禁用转义
}
模板继承
使用{% extends %}引入一个定义好的模板。
使用{% blocak %}和{% end %}定义并替换块。
定义主模板:
# views/base.html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>{% block title %}Document{% end %}</title>
{% block css %}
{% end %}
</head>
<body>
{% block main %}
{% end %}
</body>
{% block js %}
{% end %}
</html>
继承与使用模板:
{% extends 'base.html'%}
{% block title %}
API
{% end %}
{% block css %}
<style>
body{
background-color: red;
}
</style>
{% end %}
{% block main %}
<p>HELLO</p>
{% end %}
{% block js %}
<script>
alert("HELLO")
</script>
{% end %}
模板引入
如果一个地方需要一块完整的模板文件,则使用模板引入即可:
{include 'templateName'}
定义公用模板:
# views/common.html
<h1>公用内容</h1>
引入公用模板:
{% extends 'base.html'%}
{% block main %}
{% include 'common.html' %} <!-- 模板引入 -->
{% end %}
静态资源
模板中访问静态资源方式有两种,但首先你需要在application的配置项中对其进行配置:
settings = {
'template_path': 'views',
'static_path': 'static', # 指定静态文件目录
'static_url_prefix': '/static/', # 如果使用静态导入,则这个是前缀
}
推荐动态导入的方式:
<head lang="en">
<link href={{static_url("common.css")}} rel="stylesheet" />
</head>
也可进行静态导入:
<head lang="en">
<link href="/static/common.css" rel="stylesheet" />
</head>
ui_methods
允许定义全局可用的方法,以便在模板中进行调用。
第一步,创建独立的一个.py文件,并且书写函数即可:
# ./templates_methods
# 所有模板公用函数一定有self
def add(self, x, y):
return x + y
# 如果方法中返回的是html字符串,则会被转义掉
def input(self, type, name):
return f"<input type={type} name={name}>"
第二步,在appliction注册ui_methods:
import tornado.ioloop
import tornado.web
# 导入自定义的py文件
import templates_methods
class APIHandler(tornado.web.RequestHandler):
def get(self):
self.render("api.html")
settings = {
"debug": True,
"template_path": "views", # 指定模板目录
"static_path": "static", # 指定静态文件目录
"ui_methods": templates_methods, # 注册
}
application = tornado.web.Application([
tornado.web.url(r'/api', APIHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
第三步,在模板中使用:
{{ add(1,2) }}
{% raw input('text','username') %}
# 受限于ui_methods中返回字符串会经过转义的设定,所以在前端上我们选择用raw来做转义
ui_modules
ui_modules定义一些公用的组件,在这里返回的字符串将默认关闭HTML字符转义功能。
比如有一个多页面网站,我们希望对该网站中每一个页面都加上一则广告窗口,就可以使用ui_modules。
首先第一步,广告弹窗肯定是一个独立的组件,需要有HTML代码,CSS样式,JS脚本,所以我们可以看一下ui_modules中到底提供了什么方法让我们对其进行实现。
简单的做一下说明:
| 需要覆写的方法 | 描述 |
|---|---|
| render() | 覆写该方法,返回该UI模块的输出 |
| embedded_javascript() | 覆写该方法,返回一段JavaScript代码字符串,它将会在模板中自动添加script标签,并且该script标签内部会填入该方法返回的JavaScript代码字符串 |
| javascript_files() | 覆写该方法,返回值应当是str,它将会在模板中自动添加script标签并且该script标签的src属性会指向该方法所返回的字符串,如果返回值是一个相对路径,则会去application的settings中寻找静态资源的path做拼接 |
| embedded_css() | 覆写该方法,返回一段CSS代码字符串,它将会在模板中自动添加style标签,并且该style标签内部会填入该方法返回的CSS代码字符串 |
| css_files() | 覆写该方法,返回值应当是str,它将会在模板中自动添加link标签并且该link标签的href属性会指向该方法所返回的字符串,如果返回值是一个相对路径,则会去application的settings中寻找静态资源的path做拼接 |
| html_head() | 重写该方法,返回值将放置在<head />元素中的HTML字符串。 |
| html_body() | 重写该方法,返回值将放置在<body />元素末尾的HTML字符串。 |
| render_string() | 渲染模板并将其作为字符串返回。 |
下面我们来写一个非常简单的广告组件,新建一个叫ui_modules.py的文件:
from tornado.web import UIModule
class AD(UIModule):
def render(self, *args, **kwargs):
"""
模板调用时传递的参数分别放入args以及kwargs中
"""
return "<div id='ad'>这是一段广告</div>"
def embedded_css(self):
"""
注意:配置的CSS或者JS代码是全局生效的,所以我们应该只对AD组件做一个约束
"""
return """
#ad{
width: 200px;
height: 200px;
position: fixed;
left: 25%;
line-height: 200px;
text-align: center;
background: red;
}
"""
需要为application注册一下这个ui_modules:
import tornado.ioloop
import tornado.web
# 导入
import ui_modules
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
class HomeHandler(tornado.web.RequestHandler):
def get(self):
self.render("home.html")
settings = {
"debug": True,
"template_path": "views", # 指定模板目录
"static_path": "static", # 指定静态文件目录
"ui_modules":ui_modules, # 注册
}
application = tornado.web.Application([
tornado.web.url(r'^/index/', IndexHandler, name="index"),
tornado.web.url(r'^/home/', HomeHandler, name="home"),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
然后只需要在模板中进行使用即可:
# views/index.html
{% extends 'base.html' %}
{% block title %}
主页
{% end %}
{% block main %}
<h1>欢迎来到主页</h1>
{% module AD() %}
{% end %}
现在我们的index就有这个组件了:
")
如果想在home页面中也加入这个组件,直接使用{% module AD() %}即可。
模板原理
- 使用内置的open函数读取Html文件中的内容
- 根据模板语言的标签分割Html文件的内容,例如:{{}} 或 {%%}
- 将分割后的部分数据块格式化成特殊的字符串(表达式)
- 通过python的内置函数执行字符串表达式,即:将html文件的内容和嵌套的数据整合
- 将数据返回给请求客户端
也就是说,它会将一个文件进行读取,以{{}}或者{%%}作为分隔符,拿到其中的内容并进行替换。
举个例子:
<h1>大家好,我是{{username}}</h1>
它内部会这样进行拆分:
["<h1>大家好,我是","username","</h1>"]
然后将username这一部分替换为控制器视图中的对应变量,假设username='yunya',最后就会变为:
["<h1>大家好,我是","yunya","</h1>"]
当然在替换的时候也会进行模板字符串转义的检测,如果检测出有字符<或者>等,则特换为<与>等。
所以最后的结果就是:
<h1>大家好,我是yunya</h1>
cookies
基本操作
操作cookie有两个最基本的方法:
| 方法 | 描述 |
|---|---|
| self.get_cookie() | 获取cookie键值对 |
| self.set_cookie() | 设置cookie键值对,参数expires可设置过期时间(日期:datetime/time,默认30天),expires_day设置过期天数(优先级更高),示例:expirse = time.time() + 60 * 60 * 24 * 7 |
简单示例:
class APIHandler(tornado.web.RequestHandler):
def get(self):
if self.get_cookie("access"):
self.write("你来访问过了")
else:
self.set_cookie("access","yes")
self.write("七天内可再次访问")
加密cookies
cookies是明文存储在了用户的浏览器中,因此可能会产生不安全的因素。
使用加密的cookies来让用户隐私更加安全,你需要在application的配置项中设定一个加密的盐cookie_secret,然后使用下面的两个方法进行加密cookies的操作:
| 方法 | 描述 |
|---|---|
| self.get_secure_cookie() | 获取cookie键值对,并对其进行解密 |
| self.set_secure_cookie() | 设置cookie键值对,将其与cookie_secret进行结合加密 |
简单示例:
class APIHandler(tornado.web.RequestHandler):
def get(self):
if self.get_secure_cookie("access"):
self.write("你来访问过了")
else:
self.set_secure_cookie("access", "yes")
self.write("七天内可再次访问")
settings = {
"debug": True,
"template_path": "views", # 指定模板目录
"static_path": "static", # 指定静态文件目录
"cookie_secret": "0dsa0D9d0a%39433**das9))|ddsa", # cookie加密的盐
}
application = tornado.web.Application([
tornado.web.url(r'/api', APIHandler),
], **settings)
用户认证
当前已经认证的用户信息被保存在每一个请求处理器的 self.current_user 当中, 同时在模板的 current_user 中也是。默认情况下,current_user 为 None。
要在应用程序实现用户认证的功能,你需要复写请求处理中 get_current_user() 这 个方法,在其中判定当前用户的状态,比如通过 cookie。下面的例子让用户简单地使用一个 nickname登陆应用,该登陆信息将被保存到 cookie中:
class BaseHandler(tornado.web.RequestHandler):
def get_current_user(self):
return self.get_secure_cookie("user")
class MainHandler(BaseHandler):
def get(self):
if not self.current_user:
self.redirect("/login")
return
name = tornado.escape.xhtml_escape(self.current_user)
self.write("Hello, " + name)
class LoginHandler(BaseHandler):
def get(self):
self.write('<html><body><form action="/login" method="post">'
'Name: <input type="text" name="name">'
'<input type="submit" value="Sign in">'
'</form></body></html>')
def post(self):
self.set_secure_cookie("user", self.get_argument("name"))
self.redirect("/")
application = tornado.web.Application([
(r"/", MainHandler),
(r"/login", LoginHandler),
], cookie_secret="61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=")
对于那些必须要求用户登陆的操作,可以使用装饰器 tornado.web.authenticated。 如果一个方法套上了这个装饰器,但是当前用户并没有登陆的话,页面会被重定向到 login_url(应用配置中的一个选项),上面的例子可以被改写成:
class MainHandler(BaseHandler):
@tornado.web.authenticated
def get(self):
name = tornado.escape.xhtml_escape(self.current_user)
self.write("Hello, " + name)
settings = {
"cookie_secret": "61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=",
"login_url": "/login",
}
application = tornado.web.Application([
(r"/", MainHandler),
(r"/login", LoginHandler),
], **settings)
如果你使用 authenticated 装饰器来装饰 post() 方法,那么在用户没有登陆的状态下, 服务器会返回 403 错误。
Tornado内部集成了对第三方认证形式的支持,比如Google的OAuth 。
参阅 auth 模块 的代码文档以了解更多信息。 for more details. Checkauth 模块以了解更多的细节。在Tornado的源码中有一个 Blog的例子,你也可以从那里看到 用户认证的方法(以及如何在 MySQL 数据库中保存用户数据)。
内部原理
tornado的cookies操作相关原理非常简单,以加密cookies为例:
写cookie过程:
将值进行base64加密
对除值以外的内容进行签名,哈希算法(无法逆向解析)
拼接 签名 + 加密值
读cookie过程:
读取 签名 + 加密值
对签名进行验证
base64解密,获取值内容
XSRF跨域请求伪造
基本介绍
跨域请求伪造被称为CSRF或者是XSRF(Django中称其为CSRF,tornado中称其为XSRF)。
Django中间件与CSRF跨域请求伪造
如何防止跨域请求伪造就是对该站发出的网页添加上一个随机字符串(随机的cookie),所有的向本网站后端提交的POST/PUT/PATCH/DELETE请求都需要带上这一随机字符串,如果随机字符串不是本网站后端发出或者压根没有,就认为该次提交是一个伪造的请求。
验证时tornado会检查这两个点,满足任意一个点即可:
- 请求头中有没有X-XSRFToken的请求头,如果有就检查值
- 携带的参数中,有没有_xsrf命名的键值对,如果有就检查值
tornado中如何开启跨域请求伪造呢?只需要在application的配置项中打开即可:
settings = {
"xsrf_cookies": True,
}
如果提交数据时没有携带这个xsrf_cookies,就会提示异常:
")
form表单提交
如果是form表单提交,只需要在表单中添加{{ xsrf_form_html() }}即可,这样会满足第二种检查机制:
<form action="/api" method="post">
{% raw xsrf_form_html() %}
<p><input type="text" name="username"></p>
<p><button type="submit">提交</button></p>
</form>
它其实是会返回给你一个hidden的input,在表单提交的时候也一起发送了过去:
<input type="hidden" name="_xsrf" value="2|5a04ca78|fe6c8cdc75a4b2e304a9b2e3da98c7a4|1611128917">
表单发送数据时的参数数据是会进行url编码的,所以它的编码格式就会变成下面这个样子,而tornado就检查有没有_xsrf这个键值对以及值是否正确:
usernmae=xxx&_xsrf=xxx
AJAX请求提交
如果是AJAX异步提交POST/PUT/PATCH/DELETE请求,则你需要在提交数据的请求头中添加X-XSRFToken的一组键值对,这样会满足第一种检查机制:
{% block main %}
<form id="form">
<p><input type="text" name="username"></p>
<p>
<button type="button">提交</button>
</p>
</form>
{% end %}
{% block js %}
<script src="https://code.jquery.com/jquery-3.1.1.min.js"></script>
<script>
// step01:定义获取_xsrf值的函数
function getCookie(name) {
var r = document.cookie.match("\\b" + name + "=([^;]*)\\b");
return r ? r[1] : undefined;
}
// step02:进行赋值
let xsrf = getCookie("_xsrf")
// step03:在请求头中设置X-XSRFToken的请求头
$("button").on("click", function () {
$.ajax({
type: "post",
url:"/api",
headers: {"X-XSRFToken": xsrf},
data: $("#form").serialize(),
dataType: "text",
success: ((res) => {
console.log(res)
})
})
})
</script>
{% end %}
或者你也可以按照第二种检查机制来做,$.(form).serialize()实际上会将数据进行url编码,你需要添加后面的_xsrf与其对应值即可:
// step01:获取_xsrf的值
function getCookie(name) {
var r = document.cookie.match("\\b" + name + "=([^;]*)\\b");
return r ? r[1] : undefined;
}
// step02:在提交的数据中添加_xsrf与其值
$("button").on("click", function () {
$.ajax({
type: "post",
url:"/api",
// url编码中,&代表与,你可以理解为分割符,后面就是一组新的键值对
data: $("#form").serialize() + `&_xsrf=${getCookie('_xsrf')}`,
dataType: "text",
success: ((res) => {
console.log(res)
})
})
})
异步非阻塞
基本概念
在tornado中,异步非阻塞是其代言词。
我们知道tornado处理一次HTTP请求是以单线程加I/O多路复用的epoll模式实现的,所以在一次HTTP请求中,你可以发现Tornado的控制器处理函数里并没有return响应的写法(当然你也可以手动进行return None),它内部会自己进行return响应,这是一个非常关键的点,用下面这张图进行一下说明,如何实现异步非阻塞(其实还是有一些问题的):
")
tornado.gen.coroutine
tornado.gen.coroutine协程模式装饰器,使用yield关键字来将任务包装成协程任务。
1.这种方式一定要确保协程任务中不存在同步方法
2.如果控制器函数没有进行gen.coroutine装饰器进行修饰,单纯使用yield时将不会具有非阻塞的效果
3.究其内部原因,yield的一个控制器处理函数头顶上如果具有gen.coroutine装饰器,则内部会创建Future对象用于实现非阻塞,如果不具有gen.coroutine则不会创建Future对象
4.一言以蔽之,tornado.gen.coroutine必须与yield同时出现
如下所示,使用request同步库对谷歌发起请求(不可能成功返回),将产生阻塞:
import tornado.ioloop
import tornado.web
from tornado import gen
import requests
class Api1Handler(tornado.web.RequestHandler):
# 通过async和await进行异步网络请求
@gen.coroutine
def get(self):
result = yield self.callback()
self.write(result)
def callback(self):
response = requests.request(method="GET",url="http://www.google.com")
response_text = response.text
return response_text
class Api2Handler(tornado.web.RequestHandler):
def get(self):
self.write("api2")
application = tornado.web.Application([
(r"/api1", Api1Handler),
(r"/api2", Api2Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
如果采用异步网络库aiohttp,就不会出现这样的问题了,其还是异步调用:
@gen.coroutine
def get(self):
response_text = yield self.callback()
self.write(response_text)
async def callback(self):
async with aiohttp.ClientSession() as session:
async with await session.get("http://www.google.com") as response:
response_text = await response.text()
return response_text
async await
新版的tornado全面依赖于asyncio模块,所以我们只需要使用async与await即可开启异步编程。
按照第一个协程模式装饰器的示例,其实我们可以对其进行简写:
import tornado.ioloop
import tornado.web
import aiohttp
class Api1Handler(tornado.web.RequestHandler):
# 通过async和await进行异步网络请求,如果替换成http://www.google.com
# 这依旧不影响api2的访问
async def get(self):
async with aiohttp.ClientSession() as session:
async with await session.get("http://www.cnblogs.com") as response:
result = await response.text()
self.write(result)
class Api2Handler(tornado.web.RequestHandler):
def get(self):
self.write("api2")
application = tornado.web.Application([
(r"/api1", Api1Handler),
(r"/api2", Api2Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
tornado.web.asynchronous
tornado.web.asynchronous装饰器,将本次HTTP请求转变为长连接的方式。
如果要断开本次长连接,则必须使用self.finish()方法:
经测试、6.0版本已移除
import tornado.ioloop
import tornado.web
class Api1Handler(tornado.web.RequestHandler):
@tornado.web.asynchronous # step01:添加该装饰器,本次HTTP请求将变为长连接状态
def get(self):
with open(file="testDocument.text", mode="rb") as f:
file_context = f.read()
self.write(file_context)
self.finish() # 手动结束本次长连接
class Api2Handler(tornado.web.RequestHandler):
def get(self):
self.write("api2")
application = tornado.web.Application([
(r"/api1", Api1Handler),
(r"/api2", Api2Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
HttpClient库
tornado的协程任务中必须是异步方法,因此tornado内置一些异步组件。
比如自带的异步发送网络请求的HttpClient库。
另外还有一些第三方的异步模块,如tornado-mysql等。
tornadoHttpClient官方文档
以下是基本使用方式:
import tornado.ioloop
import tornado.web
import tornado.gen
from tornado import httpclient
class Api1Handler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self):
client = httpclient.AsyncHTTPClient()
response = yield client.fetch("http://www.cnblogs.com")
self.write(response.body)
application = tornado.web.Application([
(r"/api1", Api1Handler),
])
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
如果tornado是新版,则也可以使用下面的方式:
class Api1Handler(tornado.web.RequestHandler):
# 新版:6.01测试通过
async def get(self):
client = httpclient.AsyncHTTPClient()
try:
response = await client.fetch("http://www.cnblogs.com")
except Exception as e:
print(e)
else:
self.write(response.body)
websocket
基础介绍
我们都知道,HTTP/WebSocket都属于应用层的协议,其本身是对TCP协议的封装。
那么WebSocket对于HTTP协议来说有什么不同呢?首先要从HTTP协议特性入手。
HTTP协议是一种单主动协议,即只能由Browser端主动发送请求,而Server端只能被动回应Browser端的请求,无法主动向Browser端发送请求
WebSocket则是一种双主动协议,Server端也能够主动向Browser端发送请求,该请求一般被称之为推送
WebSocket必须要浏览器支持。
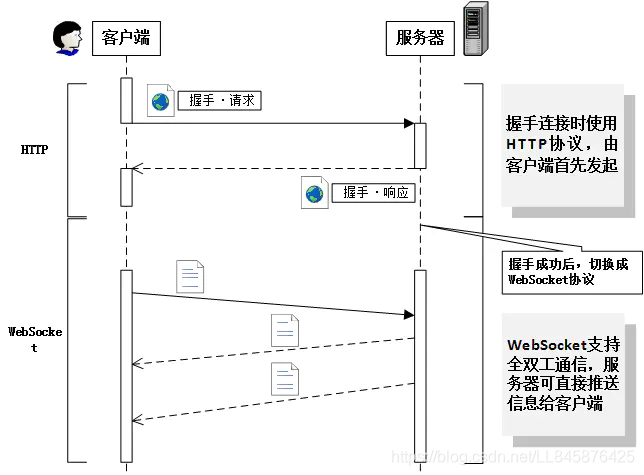
握手流程
以下是WebSocket的握手流程:
1.服务端开启监听
2.客户端发送请求企图建立连接
3.服务端进行三次握手,确认连接建立
4.客户端生成一个随机字符串,在请求头中添加随机字符串,超服务器发送过去(请求头名字:Sec-WebSocket-Key)
5.服务端接收到请求,decode解码出随机字符串,通过sha1进行加密,并且把魔法字符串当盐添加进去,然后通过base64编码,将编码完成后的数据超客户端发送回去
6.客户端进行验证,将服务端返回的内容首先通过base64解码,然后进行sha1+本地随机字符串+魔法字符串进行比对,如果相同则代表websocket服务建立完成
魔法字符串是一个固定的值,如下:
258EAFA5-E914-47DA-95CA-C5AB0DC85B11
看Server端代码,理解上面的步骤:
import socket
import base64
import hashlib
def get_headers(data):
"""
将请求头格式化成字典
:param data:
:return:
"""
header_dict = {}
data = str(data, encoding='utf-8')
for i in data.split('\r\n'):
print(i)
header, body = data.split('\r\n\r\n', 1)
header_list = header.split('\r\n')
for i in range(0, len(header_list)):
if i == 0:
if len(header_list[i].split(' ')) == 3:
header_dict['method'], header_dict['url'], header_dict['protocol'] = header_list[i].split(' ')
else:
k, v = header_list[i].split(':', 1)
header_dict[k] = v.strip()
return header_dict
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8002))
sock.listen(5)
conn, address = sock.accept()
data = conn.recv(1024)
headers = get_headers(data) # 提取请求头信息
# 对请求头中的sec-websocket-key进行加密
response_tpl = "HTTP/1.1 101 Switching Protocols\r\n" \
"Upgrade:websocket\r\n" \
"Connection: Upgrade\r\n" \
"Sec-WebSocket-Accept: %s\r\n" \
"WebSocket-Location: ws://%s%s\r\n\r\n"
magic_string = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11'
value = headers['Sec-WebSocket-Key'] + magic_string
ac = base64.b64encode(hashlib.sha1(value.encode('utf-8')).digest())
response_str = response_tpl % (ac.decode('utf-8'), headers['Host'], headers['url'])
# 响应【握手】信息
conn.send(bytes(response_str, encoding='utf-8'))
请求解析
当一个WebSocket请求到来时,接收到请求的一方(server/browser)要对他的数据进行解析,如何进行数据解析是一个非常有趣的话题。
首先,一个WebSocket的数据帧会大体上分为三部分,(头部、MASK、数据体),我们要研究的是如何区分这三部分。

1.将接收到的数据第1个字节进行提取,并且与b00001111做&运算(与),得到一个数值。
2.如果该数值等于126,则头部信息占2个字节(第2字节和第3字节),MASK数据则是第4字节至第7字节,从第8字节开始均为数据体部分。
3.如果该数值等于127,则头部信息占8个字节(第2字节至第9字节),MASK数据则是第10字节至第13字节,从第14字节开始均为数据体部分。
4.如果该数值等于125,则无头部信息,Mask数据是第2字节至第5字节,从第6字节开始均为数据体部分。
而对数据体进行解析时,则会用到^异或运算。
^ 按位异或运算符:当两对应的二进位相异时,结果为1
简单的示例:
a = 0011 1100
b = 0000 1101
a^b = 0011 0001
下面是官网中提供的Js解析数据体示例:
var DECODED = "";
for (var i = 0; i < ENCODED.length; i++) {
DECODED[i] = ENCODED[i] ^ MASK[i % 4];
}
用Python代码进行实现 (Broswer端已自动做好,但是如果我们手动写服务端,这些逻辑都需要自己搞明白):
info = conn.recv(8096) # 读取数据
# step01:提取第一个字节的数据,与00001111(十进制127)进行与运算
payload_len = info[1] & 127
# step02:解析头部、MASK部、体部信息
if payload_len == 126:
extend_payload_len = info[2:4]
mask = info[4:8]
decoded = info[8:]
elif payload_len == 127:
extend_payload_len = info[2:10]
mask = info[10:14]
decoded = info[14:]
else:
extend_payload_len = None
mask = info[2:6]
decoded = info[6:]
# step03:读取数据体信息(官网示例)
bytes_list = bytearray()
for i in range(len(decoded)):
# 核心代码,数据体解析,异或运算
chunk = decoded[i] ^ mask[i % 4]
bytes_list.append(chunk)
body = str(bytes_list, encoding='utf-8')
print(body)
其他的一些知识点:
FIN:1bit
Websocket不可一次接收过长的消息。所以用FIN来区分是否分片接收一条长消息。
如果是1代表这是单条消息,没有后续分片了。而如果是0代表,代表此数据帧是不是一个完整的消息,而是一个消息的分片,并且不是最后一个分片后面还有其他分片
RSV1, RSV2, RSV3: 1 bit each
必须是0,除非客户端和服务端使用WS扩展时,可以为非0。
Opcode: 4bit
这个为操作码,表示对后面的有效数据荷载的具体操作,如果未知接收端需要断开连接
%x0:表示连续帧
%x1:表示文本帧
%x2:表示二进制帧
%x3-7:保留用于其他非控制帧
%x8:表示连接关闭
%x9:表示ping操作
%xA:表示pong操作
%xB-F:保留用于其他控制帧
Mask: 1bit
是否进行过掩码,比如客户端给服务端发送消息,需要进行掩码操作。而服务端到客户端不需要
Payload Length: 7 bits, 7+16 bits, or 7+64 bits(上面已经写过了)
“有效载荷数据”的长度(以字节为单位):如果为0-125,则为有效载荷长度。 如果为126,则以下2个字节解释为16位无符号整数是有效载荷长度。 如果是127,以下8个字节解释为64位无符号整数(最高有效位必须为0)是有效载荷长度。 多字节长度数量以网络字节顺序表示。 注意在所有情况下,必须使用最小字节数进行编码长度,例如124字节长的字符串的长度不能编码为序列126、0、124。有效载荷长度是“扩展数据”的长度+“应用程序数据”。 “扩展数据”的长度可以是零,在这种情况下,有效负载长度是 “应用程序数据”。
Masking-key: 0 or 4 bytes (32bit)
所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask为1,且携带了4字节的Masking-key。如果Mask为0,则没有Masking-key。
Payload data: (x+y) bytes
“有效载荷数据”定义为串联的“Extension data”与“Application data”。
Extension data: x bytes
如果没有协商使用扩展的话,扩展数据数据为0字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。
Application data: y bytes
任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。
请求发送
当发送一个请求时,我们需要对数据进行封装。
以下是WebSocket协议规定:
def send_msg(conn, msg_bytes):
import struct
token = b"\x81" # 协议规定,第一个字节必须是x81
length = len(msg_bytes)
# 判断长度
if length < 126:
token += struct.pack("B", length)
elif length <= 0xFFFF:
token += struct.pack("!BH", 126, length)
else:
token += struct.pack("!BQ", 127, length)
msg = token + msg_bytes
conn.send(msg)
return True
js演示
在JavaScript中,启用WebSocket非常简单,并且它已经将数据解析、数据发送都做好了。
直接用即可:
var ws = new WebSocket('ws://localhost:8080');
webSocket.readyState用于查看当前的连接状态:
switch (ws.readyState) {
case WebSocket.CONNECTING:
// do something 值是0,未连接
break;
case WebSocket.OPEN:
// do something 值为1,表示连接成功,可以通信了。
break;
case WebSocket.CLOSING:
// do something 值为2,表示连接正在关闭。
break;
case WebSocket.CLOSED:
// do something 值为3,表示连接已经关闭,或者打开连接失败。
break;
default:
// this never happens
break;
}
回调函数系列:
| 函数名称 | 描述 |
|---|---|
| onopen | 用于指定连接成功后的回调函数 |
| onclose | 用于指定连接关闭后的回调函数 |
| onmessage | 用于指定收到服务器数据后的回调函数 |
| onerror | 用于指定报错时的回调函数 |
两个基本方法:
| 方法名称 | 描述 |
|---|---|
| send() | 用于向服务器发送数据 |
| close() | 关闭连接 |
基本演示:
var ws = new WebSocket("ws://localhost:8080");
//申请一个WebSocket对象,参数是服务端地址,同http协议使用http://开头一样,WebSocket协议的url使用ws://开头,另外安全的
WebSocket协议使用wss://开头
ws.onopen = function(){
//当WebSocket创建成功时,触发onopen事件
console.log("open");
ws.send("hello"); //将消息发送到服务端
}
ws.onmessage = function(e){
//当客户端收到服务端发来的消息时,触发onmessage事件,参数e.data包含server传递过来的数据
console.log(e.data);
}
ws.onclose = function(e){
//当客户端收到服务端发送的关闭连接请求时,触发onclose事件
console.log("close");
}
ws.onerror = function(e){
//如果出现连接、处理、接收、发送数据失败的时候触发onerror事件
console.log(error);
}
onmessage回调函数之接收二进制数据或字符串:
ws.onmessage = function(event){
if(typeOf event.data === String) { // 字符串
console.log("Received data string");
}
if(event.data instanceof ArrayBuffer){ // 二进制
var buffer = event.data;
console.log("Received arraybuffer");
}
}
send()方法之发送文本、发送文件、发送二进制数据:
// 发送文本
ws.send('your message');
// 发送文件
var file = document
.querySelector('input[type="file"]')
.files[0];
ws.send(file);
// ArrayBuffer 二进制数据
// Sending canvas ImageData as ArrayBuffer
var img = canvas_context.getImageData(0, 0, 400, 320);
var binary = new Uint8Array(img.data.length);
for (var i = 0; i < img.data.length; i++) {
binary[i] = img.data[i];
}
ws.send(binary.buffer);
socket服务端
手动用socket实现websocket服务端:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import socket
import base64
import hashlib
def get_headers(data):
"""
将请求头格式化成字典
:param data:
:return:
"""
header_dict = {}
data = str(data, encoding='utf-8')
header, body = data.split('\r\n\r\n', 1)
header_list = header.split('\r\n')
for i in range(0, len(header_list)):
if i == 0:
if len(header_list[i].split(' ')) == 3:
header_dict['method'], header_dict['url'], header_dict['protocol'] = header_list[i].split(' ')
else:
k, v = header_list[i].split(':', 1)
header_dict[k] = v.strip()
return header_dict
def send_msg(conn, msg_bytes):
"""
WebSocket服务端向客户端发送消息
:param conn: 客户端连接到服务器端的socket对象,即: conn,address = socket.accept()
:param msg_bytes: 向客户端发送的字节
:return:
"""
import struct
token = b"\x81"
length = len(msg_bytes)
if length < 126:
token += struct.pack("B", length)
elif length <= 0xFFFF:
token += struct.pack("!BH", 126, length)
else:
token += struct.pack("!BQ", 127, length)
msg = token + msg_bytes
conn.send(msg)
return True
def run():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8003))
sock.listen(5)
conn, address = sock.accept()
data = conn.recv(1024)
headers = get_headers(data)
response_tpl = "HTTP/1.1 101 Switching Protocols\r\n" \
"Upgrade:websocket\r\n" \
"Connection:Upgrade\r\n" \
"Sec-WebSocket-Accept:%s\r\n" \
"WebSocket-Location:ws://%s%s\r\n\r\n"
value = headers['Sec-WebSocket-Key'] + '258EAFA5-E914-47DA-95CA-C5AB0DC85B11'
ac = base64.b64encode(hashlib.sha1(value.encode('utf-8')).digest())
response_str = response_tpl % (ac.decode('utf-8'), headers['Host'], headers['url'])
conn.send(bytes(response_str, encoding='utf-8'))
while True:
try:
info = conn.recv(8096)
except Exception as e:
info = None
if not info:
break
payload_len = info[1] & 127
if payload_len == 126:
extend_payload_len = info[2:4]
mask = info[4:8]
decoded = info[8:]
elif payload_len == 127:
extend_payload_len = info[2:10]
mask = info[10:14]
decoded = info[14:]
else:
extend_payload_len = None
mask = info[2:6]
decoded = info[6:]
bytes_list = bytearray()
for i in range(len(decoded)):
chunk = decoded[i] ^ mask[i % 4]
bytes_list.append(chunk)
body = str(bytes_list, encoding='utf-8')
send_msg(conn,body.encode('utf-8'))
sock.close()
if __name__ == '__main__':
run()
tornado示例
tornado服务端:
import tornado.ioloop
import tornado.web
import tornado.websocket
class WsHandler(tornado.websocket.WebSocketHandler):
# 该类继承RequestHandler类
def open(self):
"""
连接成功后、自动执行
:return:
"""
# 超客户端发送信息
self.write_message("连接成功")
def on_message(self, message):
"""
客户端发送消息时,自动执行
:return:
"""
print(message)
def on_close(self):
"""
客户端关闭连接时,,自动执行
:return:
"""
print("连接已关闭")
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
settings = {
"template_path": "views",
}
application = tornado.web.Application([
(r"/ws/", WsHandler),
(r"/index/", IndexHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
模板文件:
<script>
let ws = new WebSocket("ws://127.0.0.1:8888/ws/");
ws.onmessage = Event=>{
console.log(Event.data);
ws.send("你好");
ws.close();
}
</script>
tornado聊天室
tornado本身支持WebSocket,(Django&Flask原生不支持)。
利用WebSocket,构建网络聊天室:
后端代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import uuid
import json
import tornado.ioloop
import tornado.web
import tornado.websocket
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render('index.html')
class ChatHandler(tornado.websocket.WebSocketHandler):
# 用户存储当前聊天室用户
waiters = set()
# 用于存储历时消息
messages = []
def open(self):
"""
客户端连接成功时,自动执行,加载聊天记录
:return:
"""
ChatHandler.waiters.add(self)
uid = str(uuid.uuid4())
self.write_message(uid)
for msg in ChatHandler.messages:
self.write_message(msg)
def on_message(self, message):
"""
客户端连发送消息时,自动执行,群转发消息
:param message:
:return:
"""
msg = message
ChatHandler.messages.append(msg)
for client in ChatHandler.waiters:
client.write_message(msg)
def on_close(self):
"""
客户端关闭连接时,,自动执行
:return:
"""
ChatHandler.waiters.remove(self)
def run():
settings = {
'template_path': 'views',
'static_path': 'static',
}
application = tornado.web.Application([
(r"/", IndexHandler),
(r"/chat", ChatHandler),
], **settings)
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
if __name__ == "__main__":
run()
模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Python聊天室</title>
</head>
<body>
<div>
<input type="text" id="txt">
<input type="button" id="btn" value="提交" onclick="sendMsg();"/>
<input type="button" id="close" value="关闭连接" onclick="closeConn();"/>
</div>
<div id="container" style="border: 1px solid #dddddd;margin: 20px;min-height: 500px;">
</div>
<script type="text/javascript">
window.onload = () => {
wsUpdater.start();
}
var wsUpdater = {
socket: null,
uid: null,
start: function () {
var url = "ws://127.0.0.1:8888/chat";
wsUpdater.socket = new WebSocket(url);
wsUpdater.socket.onmessage = function (event) {
if (wsUpdater.uid) {
// 解析信息
wsUpdater.showMessage(event.data);
} else {
// 第一次,获取uid
wsUpdater.uid = event.data;
}
}
},
showMessage: function (content) {
content = JSON.parse(content);
let article = document.createElement("article");
let p_name = document.createElement("p");
let p_context = document.createElement("p")
article.append(p_name);
article.append(p_context);
p_name.append(`${content.uid}`)
p_name.style.textIndent = "2rem";
p_context.append(`${content.message}`)
p_context.style.textIndent = "2rem";
document.querySelector("#container").append(article);
}
};
function sendMsg() {
var msg = {
uid: wsUpdater.uid,
message: document.querySelector("#txt").value,
};
wsUpdater.socket.send(JSON.stringify(msg));
}
</script>
</body>
</html>
tornado其他
自定义Session
Session是将用户存储的信息保存在服务器上,然后发送给用户一段随机字符串。
当用户下次来时如果带有该随机字符串,则能获取到保存的信息(代表已登录),否则就获取不到保存的信息(代表未登录)。
其实本质还是对cookie的一次升级操作。
原生tronado中未提供Seesion操作,但是我们可以自己写一个:
")
以下是最基础的示例,将Session放置在内存中。(Session存储时未进行加密,可对此做优化)
如果想放置在Redis、File等地方,原理也是一样的。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import uuid
import tornado.ioloop
import tornado.web
class Session(object):
container = {
# 用户1-nid : {}
}
def __init__(self, handler):
# 获取用户cookie,如果有,不操作,否则,给用户生成随即字符串
# - 写给用户
# - 保存在session
nid = handler.get_cookie('session_id')
if nid:
if nid in Session.container:
pass
else:
nid = str(uuid.uuid4())
Session.container[nid] = {}
else:
nid = str(uuid.uuid4())
Session.container[nid] = {}
handler.set_cookie('session_id', nid)
# nid当前访问用户的随即字符串
self.nid = nid
# 封装了所有用户请求信息
self.handler = handler
def __setitem__(self, key, value):
self.set(key, value)
def __getitem__(self, item):
return self.get(item)
def __delitem__(self, key):
self.delete(key)
def get(self, item):
return Session.container[self.nid].get(item)
def set(self, key, value):
Session.container[self.nid][key] = value
def delete(self, key):
del Session.container[self.nid][key]
class MyHandler(tornado.web.RequestHandler):
def initialize(self):
self.session = Session(self)
class IndexHandler(MyHandler):
def get(self):
if self.session.get("access"):
self.write("你来访问过了")
else:
self.session.set("access", "yes")
self.write("七天内可再次访问")
settings = {
'template_path': 'views',
'static_path': 'statics',
}
application = tornado.web.Application([
(r'/index', IndexHandler),
], **settings)
if __name__ == '__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
Futer探究
-
普通同步(单线程)阻塞服务器框架原理
通过
select与socket我们可以开发一个微型的框架,使用select实现I/O多路复用监听本地服务端socket。当有客户端发送请求时,
select(Linux下为epoll)监听的本地socket发生变化,通过socket.accept()得到客户端发送来的conn(也是一个socket),并将conn也添加到select监听列表里。当客户端通过conn发送数据时,服务端select监听列表的conn发生变化,我们将conn发送的数据(请求数据)接收保存并处理得到request_header与request_body,然后可以根据request_header中的url来匹配本地路由中的url,然后得到对应的控制器处理函数,然后将控制器处理函数的返回值(一般为字符串)通过conn发送回请求客户端,然后将conn关闭,并且移除select监听列表中的conn,这样一次网络I/O请求便算结束。
import socket
import select
class HttpRequest(object):
"""
用户封装用户请求信息
"""
def __init__(self, content):
"""
:param content:用户发送的请求数据:请求头和请求体
"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes()
self.header_dict = {}
self.method = ""
self.url = ""
self.protocol = ""
self.initialize()
self.initialize_headers()
def initialize(self):
temp = self.content.split(b'\r\n\r\n', 1)
if len(temp) == 1:
self.header_bytes += temp
else:
h, b = temp
self.header_bytes += h
self.body_bytes += b
@property
def header_str(self):
return str(self.header_bytes, encoding='utf-8')
def initialize_headers(self):
headers = self.header_str.split('\r\n')
first_line = headers[0].split(' ')
if len(first_line) == 3:
self.method, self.url, self.protocol = headers[0].split(' ')
for line in headers:
kv = line.split(':')
if len(kv) == 2:
k, v = kv
self.header_dict[k] = v
# class Future(object):
# def __init__(self):
# self.result = None
def main(request):
return "main"
def index(request):
return "indexasdfasdfasdf"
routers = [
('/main/',main),
('/index/',index),
]
def run():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(("127.0.0.1", 9999,))
sock.setblocking(False)
sock.listen(128)
inputs = []
inputs.append(sock)
while True:
rlist,wlist,elist = select.select(inputs,[],[],0.05)
for r in rlist:
if r == sock:
"""新请求到来"""
conn,addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else:
"""客户端发来数据"""
data = b""
while True:
try:
chunk = r.recv(1024)
data = data + chunk
except Exception as e:
chunk = None
if not chunk:
break
# data进行处理:请求头和请求体
request = HttpRequest(data)
# 1. 请求头中获取url
# 2. 去路由中匹配,获取指定的函数
# 3. 执行函数,获取返回值
# 4. 将返回值 r.sendall(b'alskdjalksdjf;asfd')
import re
flag = False
func = None
for route in routers:
if re.match(route[0],request.url):
flag = True
func = route[1]
break
if flag:
result = func(request)
r.sendall(bytes(result,encoding='utf-8'))
else:
r.sendall(b"404")
inputs.remove(r)
r.close()
if __name__ == '__main__':
run()
2、Tornado异步非阻塞实现原理
tornado通过装饰器 + Future从而实现异步非阻塞。在控制器处理函数中如果加上gen.coroutine且进行yield时,会产生一个Future对象,此时控制函数的类型是一个生成器,如果是self.write()等操作将会直接返回,如果是Future生成器对象的话将会把返回来的Future对象添加到async_request_dict中,先不给客户端返回响应数据(此时可以处理其他客户端的连接请求),等Future对象的result有值时再返回,还可以设置超时时间,在规定的时间过后返回响应数据。 !! 关键是future对象,future对象里有result属性,默认为None,当result有值时再返回数据。
我们看一下gen.coroutine装饰器的源码,注释里有句话写的很明了:
Functions with this decorator return a `.Future`.
# 使用此函数作为装饰器将返回一个Future
虽然使用gen.coroutine装饰器会自动生成Future,但是你任然可以手动创建一个Future并进行返回。
以下示例将展示Future是依赖于result,如果result未设置值,则HTTP请求不结束。
import tornado.ioloop
import tornado.web
from tornado import gen
from tornado.concurrent import Future
future = None # 全局变量
class MainHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
global future
future = Future()
future.add_done_callback(self.done)
# 自己返回future
yield future
def done(self, *args, **kwargs):
self.write('Main') # 立马写入
self.finish() # 该请求完成!
class IndexHandler(tornado.web.RequestHandler):
def get(self):
global future
# 改变结果,
future.set_result(None)
self.write("Index")
application = tornado.web.Application([
(r"/main", MainHandler),
(r"/index", IndexHandler),
])
if __name__ == "__main__":
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
下面是手动实现异步非阻塞框架(自我感觉还是和tornado有一些差异,下面这个代码是必须要有HTTP请求来才会循环检测Future任务列表,tornado中其实是任务完成后自动就返回了,暂时也没往深处研究….)
import socket
import select
import time
class HttpRequest(object):
"""
用户封装用户请求信息
"""
def __init__(self, content):
"""
:param content:用户发送的请求数据:请求头和请求体
"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes()
self.header_dict = {}
self.method = ""
self.url = ""
self.protocol = ""
self.initialize()
self.initialize_headers()
def initialize(self):
temp = self.content.split(b'\r\n\r\n', 1)
if len(temp) == 1:
self.header_bytes += temp
else:
h, b = temp
self.header_bytes += h
self.body_bytes += b
@property
def header_str(self):
return str(self.header_bytes, encoding='utf-8')
def initialize_headers(self):
headers = self.header_str.split('\r\n')
first_line = headers[0].split(' ')
if len(first_line) == 3:
self.method, self.url, self.protocol = headers[0].split(' ')
for line in headers:
kv = line.split(':')
if len(kv) == 2:
k, v = kv
self.header_dict[k] = v
class Future(object):
def __init__(self,timeout=0):
self.result = None
self.timeout = timeout
self.start = time.time()
def main(request):
f = Future(5)
return f
def index(request):
return "indexasdfasdfasdf"
routers = [
('/main/',main),
('/index/',index),
]
def run():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(("127.0.0.1", 9999,))
sock.setblocking(False)
sock.listen(128)
inputs = []
inputs.append(sock)
async_request_dict = {
# 'socket': futrue
}
while True:
rlist,wlist,elist = select.select(inputs,[],[],0.05)
for r in rlist:
if r == sock:
"""新请求到来"""
conn,addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else:
"""客户端发来数据"""
data = b""
while True:
try:
chunk = r.recv(1024)
data = data + chunk
except Exception as e:
chunk = None
if not chunk:
break
# data进行处理:请求头和请求体
request = HttpRequest(data)
# 1. 请求头中获取url
# 2. 去路由中匹配,获取指定的函数
# 3. 执行函数,获取返回值
# 4. 将返回值 r.sendall(b'alskdjalksdjf;asfd')
import re
flag = False
func = None
for route in routers:
if re.match(route[0],request.url):
flag = True
func = route[1]
break
if flag:
result = func(request)
if isinstance(result,Future):
async_request_dict[r] = result
else:
r.sendall(bytes(result,encoding='utf-8'))
inputs.remove(r)
r.close()
else:
r.sendall(b"404")
inputs.remove(r)
r.close()
for conn in async_request_dict.keys():
future = async_request_dict[conn]
start = future.start
timeout = future.timeout
ctime = time.time()
if (start + timeout) <= ctime :
future.result = b"timeout"
if future.result:
conn.sendall(future.result)
conn.close()
del async_request_dict[conn]
inputs.remove(conn)
if __name__ == '__main__':
run()
tornado源码流程图示
")
写在最后
本文内容主要来源于网络、一些代码等都是手动测一遍结合自己想法就写上去了。
另外,很多知识点都摘自武Sir博客。
欢迎访问武Sir博客地址
其实从异步非阻塞开始,我写的就有点心虚了,因为大多数资料都是从网上找的本身也没翻看过tornado源码,所以有一些地方深入解读会有一些冲突。
如果想了解底层可能会有误差,甩个锅先,但是基本上新版tornado你要单纯使用异步就简单粗暴的async await即可。
以后有空再看源码回来填坑吧、^(* ̄(oo) ̄)^,感谢您的阅读。
2021年1月28日凌晨12.01



