环境:Ubuntu16.04+Tensorflow-cpu-1.6.0+ROS Kinetic+OpenCV3.3.1
前期准备:
- 完成Object Detection api配置
- 完成OpenCV配置
完成模型训练后就是模型的应用,这里通过ROS利用Object Detection api调用模型实现目标物体的识别。
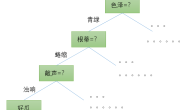
一、模型导入
模型路径设置如下图所示,注意设置目标对象类型数目。
#Get models
rospy.loginfo("begin initialization...")
self.PATH_TO_CKPT = '../frozen_inference_graph.pb'
self.PATH_TO_LABELS = '../bottel.pbtxt'
self.NUM_CLASSES = 2
self.detection_graph = self._load_model()
self.category_index = self._load_label_map()
self.image_tensor = self.detection_graph.get_tensor_by_name('image_tensor:0')
self.boxes = self.detection_graph.get_tensor_by_name('detection_boxes:0')
self.scores = self.detection_graph.get_tensor_by_name('detection_scores:0')
self.classes = self.detection_graph.get_tensor_by_name('detection_classes:0')
self.num_detections = self.detection_graph.get_tensor_by_name('num_detections:0')
二、数据处理
调用模型识别目标对象前需进行数据处理,流程如下图所示。
- 相机获取的图像信息会以ROSImage Message的格式发布在ROS平台上,然后通过CvBridge对获取的图像信息进行转换,将其从ROSImage Message格式转变为Mat格式。
- 通过OpenCV对获取图像数据进行预处理后转换为numpy数组,然后调用ObjectDetection API进行识别。
- 完成图像中目标物体的识别后,识别结果以数组的形式发布到相关话题中,同时视觉识别程序会将识别出来的目标物体使用带有颜色的矩形框出来并在其上方标识识别物体的标签及其概率,然后在转换为ROSImage Message格式发布到相应话题中。

代码实现
# detect object from the image
def imgprogress(self, image_msg):
with self.detection_graph.as_default():
with tf.Session(graph=self.detection_graph) as sess:
#translate image_msg data
cv_image = self._cv_bridge.imgmsg_to_cv2(image_msg, "rgb8")
pil_img = Image.fromarray(cv_image)
(im_width, im_height) = pil_img.size
image_np =np.array(pil_img.getdata()).reshape((im_height, im_width, 3)).astype(np.uint8)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run([self.boxes, self.scores, self.classes, self.num_detections],feed_dict={self.image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(image_np,np.squeeze(boxes),np.squeeze(classes).astype(np.int32),np.squeeze(scores),
self.category_index,
use_normalized_coordinates=True,
line_thickness=8)
#public img_msg
ROSImage_pro=self._cv_bridge.cv2_to_imgmsg(image_np,encoding="rgb8")
self._pub.publish(ROSImage_pro)
三、触发识别
因通过Object Detection API进行物体识别需要占用大量资源,所以采用动态识别的会非常卡,这里采用触发器进行触发识别,本程序设置了一个订阅器self._sub用于获取用于识别的图片,当需要进行识别时,发布图片到image_topic即可触发程序,同时结果会通过self._pub发布到object_detection话题中。
# Subscribe to judge
self._sub = rospy.Subscriber(image_topic, ROSImage, self.imgprogress, queue_size=10)
# Subscribe to the image
self._pub = rospy.Publisher('object_detection', ROSImage, queue_size=1)
完整程序
#!/usr/bin/env python
import rospy
from sensor_msgs.msg import Image as ROSImage
from cv_bridge import CvBridge
import cv2
import matplotlib
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
import uuid
from collections import defaultdict
from io import StringIO
from PIL import Image
from math import isnan
# This is needed since the notebook is stored in the object_detection folder.
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
class ObjectDetectionDemo():
def __init__(self):
rospy.init_node('tfobject')
# Set the shutdown function (stop the robot)
rospy.on_shutdown(self.shutdown)
camera_topic = "/camera/rgb/image_raw" #rospy.get_param("~image_topic", "")
image_topic = "/image/rgb/object"
self.vfc=0
self._cv_bridge = CvBridge()
#Get models
rospy.loginfo("begin initialization...")
self.PATH_TO_CKPT = '../frozen_inference_graph.pb'
self.PATH_TO_LABELS = '../bottel.pbtxt'
self.NUM_CLASSES = 2
self.detection_graph = self._load_model()
self.category_index = self._load_label_map()
self.image_tensor = self.detection_graph.get_tensor_by_name('image_tensor:0')
self.boxes = self.detection_graph.get_tensor_by_name('detection_boxes:0')
self.scores = self.detection_graph.get_tensor_by_name('detection_scores:0')
self.classes = self.detection_graph.get_tensor_by_name('detection_classes:0')
self.num_detections = self.detection_graph.get_tensor_by_name('num_detections:0')
# Subscribe to judge
self._sub = rospy.Subscriber(image_topic, ROSImage, self.imgprogress, queue_size=10)
# Subscribe to the image
self._pub = rospy.Publisher('object_detection', ROSImage, queue_size=1)
rospy.loginfo("initialization has finished...")
def _load_model(self):
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(self.PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
return detection_graph
def _load_label_map(self):
label_map = label_map_util.load_labelmap(self.PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map,max_num_classes=self.NUM_CLASSES,use_display_name=True)
category_index = label_map_util.create_category_index(categories)
return category_index
# detect object from the image
def imgprogress(self, image_msg):
with self.detection_graph.as_default():
with tf.Session(graph=self.detection_graph) as sess:
#translate image_msg data
cv_image = self._cv_bridge.imgmsg_to_cv2(image_msg, "rgb8")
pil_img = Image.fromarray(cv_image)
(im_width, im_height) = pil_img.size
image_np =np.array(pil_img.getdata()).reshape((im_height, im_width, 3)).astype(np.uint8)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run([self.boxes, self.scores, self.classes, self.num_detections],feed_dict={self.image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(image_np,np.squeeze(boxes),np.squeeze(classes).astype(np.int32),np.squeeze(scores),
self.category_index,
use_normalized_coordinates=True,
line_thickness=8)
#public img_msg
ROSImage_pro=self._cv_bridge.cv2_to_imgmsg(image_np,encoding="rgb8")
self._pub.publish(ROSImage_pro)
# stop node
def shutdown(self):
rospy.loginfo("Stopping the tensorflow object detection...")
rospy.sleep(1)
if __name__ == '__main__':
try:
ObjectDetectionDemo()
rospy.spin()
except rospy.ROSInterruptException:
rospy.loginfo("RosTensorFlow_ObjectDetectionDemo has started.")