参考资料:
- 《PyTorch深度学习》(人民邮电出版社)第6章 序列数据和文本的深度学习
- PyTorch官方文档
- 廖星宇著《深度学习入门之Pytorch》第5章 循环神经网络
- 其他参考的网络资料在文中以超链接的方式给出
目录
-
- 0. 写在前面
- 1. 循环神经网络( Recurrent Neural Network )
- 2. LSTM(Long Short Term Memory Networks)
- 2.1 LSTM的内部结构
- 2.1.1 遗忘门
- 2.1.2 输入门
- 2.1.3 细胞状态的遗忘和更新
- 2.1.4 输出门
- 2.2 利用PyTorch实现LSTM
- 2.1 LSTM的内部结构
- 3. 【案例一】小试牛刀:使用LSTM进行图片分类
- 4. 【案例二】循环神经网络真正适用的场景:序列预测
- 4.1 数据准备
- 4.2 搭建网络模型
- 4.3 开始训练
- 5. LSTM与自然语言处理
- 5.1 自然语言处理基础
- 5.1.1 分词
- 5.1.2 N Gram模型
- 5.1.3 词嵌入(Word Embedding)
- 5.2 【案例三】基于词向量构建情感分类器
- 5.2.1 数据准备
- 5.2.2 构建词表
- 5.2.3 生成向量的批数据(构建迭代器)
- 5.2.4 使用词向量创建网络模型
- 5.2.5 训练模型
- 5.2.6 使用预训练好的词向量
- 5.2.7 模型结果讨论
- 5.3 【案例四】基于LSTM的情感分类器
- 5.1 自然语言处理基础
- 6. 循环神经网络的更多应用
- 6.1 GRU(Gated Recurrent Unit)
- 6.2 Encoder-Decoder/Seq2Seq
- 6.2.1 模型框架与注意力机制
- 6.2.2 【案例五】Seq2Seq实战
- 6.3 CNN+RNN——基于序列数据的卷积网络
0. 写在前面
对于自然语言处理,推荐课程:CS224n: Natural Language Processing with Deep Learning。这门课程是斯坦福大学课程,课程网站上可以下载到老师上课的PPT、视频、学习资料等等。B站上有熟肉版的视频:【官方】【中英】CS224n 斯坦福深度自然语言处理课 @雷锋字幕组。其实老师上课的英文不是很难听懂,配合PPT加上网上一些小伙伴整理的资料,应该不难理解。
1. 循环神经网络( Recurrent Neural Network )
前面提到的卷积神经网络(从零开始深度学习(三):卷积神经网络与计算机视觉 )相当于人类的视觉,它没有记忆能力,所以它只能处理一种特定的视觉任务。当处理一些对时间或者序列有依赖的问题时,卷积神经网络并不能起到很好的作用。 比如说下面这个问题:
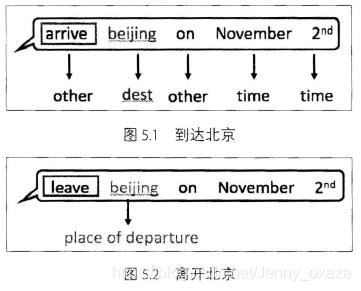 想要准确地理解“beijing”这个词在这个句子中的语义,网络的输入不能仅仅是“beijing”,还应该包括它的上下文。因此,需要网络能够记住“beijing”前面的词。 而循环神经网络是基于记忆模型提出的。循环神经网络能够记住前面出现的特征,并依据特征推断后面的结果;整体的网络结构不断循环。
想要准确地理解“beijing”这个词在这个句子中的语义,网络的输入不能仅仅是“beijing”,还应该包括它的上下文。因此,需要网络能够记住“beijing”前面的词。 而循环神经网络是基于记忆模型提出的。循环神经网络能够记住前面出现的特征,并依据特征推断后面的结果;整体的网络结构不断循环。
1.1 循环神经网络的基本结构
推荐阅读:
- 详解循环神经网络(Recurrent Neural Network)
- 深入浅出循环神经网络 RNN(这一篇我觉得讲的更好一些)
- RNN
循环神经网络有很多种结构:
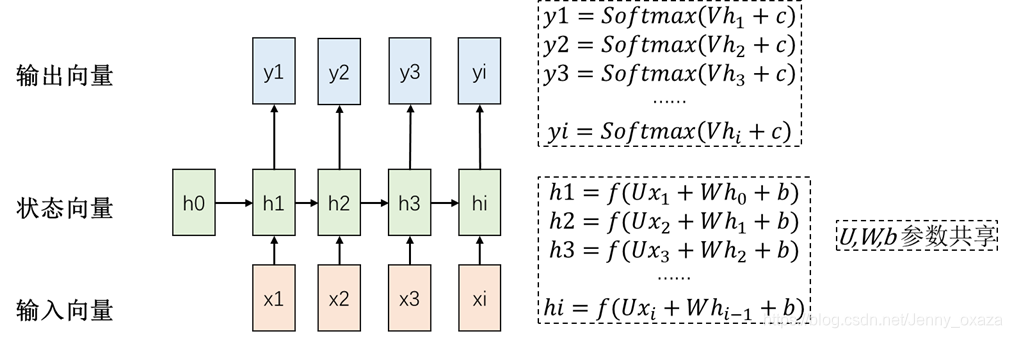
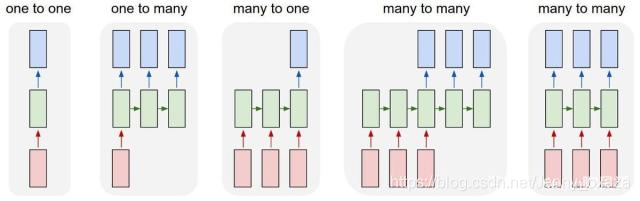 one-to-one结构 是RNN最基本的单层网络,可以类比成全连接神经网络。 many-to-many结构 many-to-many结构使RNN中最经典的结构,输入和输出都是等长的序列数据。应用场景:词性标注、语音识别。
one-to-one结构 是RNN最基本的单层网络,可以类比成全连接神经网络。 many-to-many结构 many-to-many结构使RNN中最经典的结构,输入和输出都是等长的序列数据。应用场景:词性标注、语音识别。
 这里h=f(x)的f(x)是激活函数,一般为tanh函数。 one-to-many结构 输入不是序列,但输出是序列。例如:看图说话。 可以看成是输入全为x的many-to-many结构。
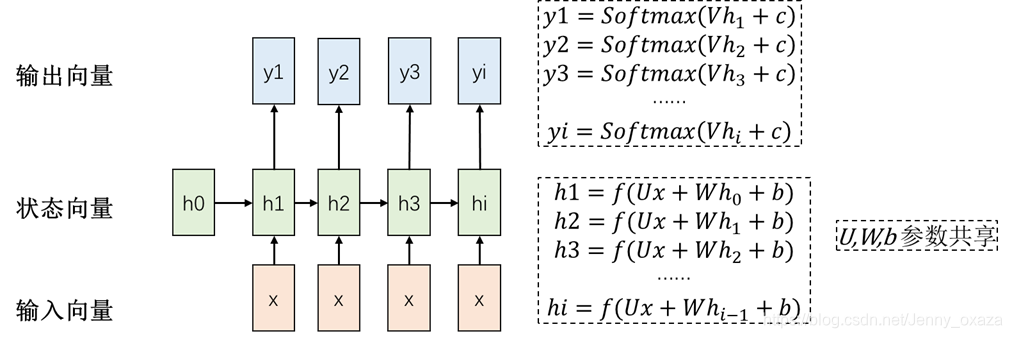
这里h=f(x)的f(x)是激活函数,一般为tanh函数。 one-to-many结构 输入不是序列,但输出是序列。例如:看图说话。 可以看成是输入全为x的many-to-many结构。
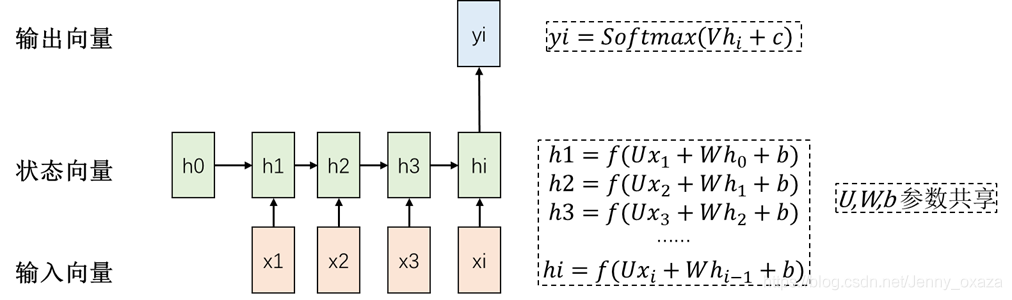
 many-to-one结构 输入时序列,但输出不是序列。应用场景:情感分析、关键字提取。
many-to-one结构 输入时序列,但输出不是序列。应用场景:情感分析、关键字提取。
1.2 利用PyTorch实现RNN
1.2.1 PyTorch中的标准RNN
PyTorch标准RNN网络模型中的计算如下:
:RNN与自然语言处理") 在PyTorch中调用标准RNN只需要使用 nn.RNN() 即可。相关参数: input_size :输入xt的特征维度。 hidden_size:输出ht的特征维度。 num_layers:网络层数。 nonlinearity:非线性激活函数的选择,默认是tanh,如果nonlinearity=‘relu’,则选择ReLU作为非线性激活函数。 bias:是否使用偏置,默认为True。 batch_first:默认为False。该参数确定网络输入的维度顺序,默认为 (seq, batch, feature)。如果设置为True,则为 (batch, seq, feature)。seq表示序列长度,batch表示批数据,feature表示维度。 dropout:默认为0,表示不设置Dropout层;如果设置为0~1之间的数值,则表示每层后面都加上一个Dropout层,该Dropout层以设置的数值的概率进行Dropout。 bidirectional:默认为False。如果设置为True,则为双向循环神经网络结构。 关于这些参数的一些更详细的解释,可以看:pytorch中RNN参数的详细解释 下面这行代码,就建立了一个简单的循环神经网络:输入维度是20,输出维度是50,两层的单向网络。
在PyTorch中调用标准RNN只需要使用 nn.RNN() 即可。相关参数: input_size :输入xt的特征维度。 hidden_size:输出ht的特征维度。 num_layers:网络层数。 nonlinearity:非线性激活函数的选择,默认是tanh,如果nonlinearity=‘relu’,则选择ReLU作为非线性激活函数。 bias:是否使用偏置,默认为True。 batch_first:默认为False。该参数确定网络输入的维度顺序,默认为 (seq, batch, feature)。如果设置为True,则为 (batch, seq, feature)。seq表示序列长度,batch表示批数据,feature表示维度。 dropout:默认为0,表示不设置Dropout层;如果设置为0~1之间的数值,则表示每层后面都加上一个Dropout层,该Dropout层以设置的数值的概率进行Dropout。 bidirectional:默认为False。如果设置为True,则为双向循环神经网络结构。 关于这些参数的一些更详细的解释,可以看:pytorch中RNN参数的详细解释 下面这行代码,就建立了一个简单的循环神经网络:输入维度是20,输出维度是50,两层的单向网络。
<code class="prism language-python has-numbering"><span class="token keyword">from</span> torch <span class="token keyword">import</span> nn simple_rnn <span class="token operator">=</span> nn<span class="token punctuation">.</span>RNN<span class="token punctuation">(</span>input_size <span class="token operator">=</span> <span class="token number">20</span><span class="token punctuation">,</span> hidden_size <span class="token operator">=</span> <span class="token number">50</span><span class="token punctuation">,</span> num_layers <span class="token operator">=</span> <span class="token number">2</span><span class="token punctuation">)</span> </code>
也可以查询网络的一些属性:
 注意在代码中这些属性的访问不需要写中括号。
注意在代码中这些属性的访问不需要写中括号。
<code class="prism language-python has-numbering"><span class="token comment"># 访问网络中第一层的 Wih</span> <span class="token keyword">print</span><span class="token punctuation">(</span>simple_rnn<span class="token punctuation">.</span>weight_ih_l0<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: torch.Size([50, 20]) 因为第一层是20维向量,第二层是50维向量,所以第一层的Wih是 50×20 向量 '''</span> <span class="token comment"># 访问网络中第一层的 Whh</span> <span class="token keyword">print</span><span class="token punctuation">(</span>simple_rnn<span class="token punctuation">.</span>weight_hh_l0<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: torch.Size([50, 50]) '''</span> </code>
这些参数都是Variable,可以取出它们的data进行自定义的初始化。
1.2.2 标准RNN的输入和输出
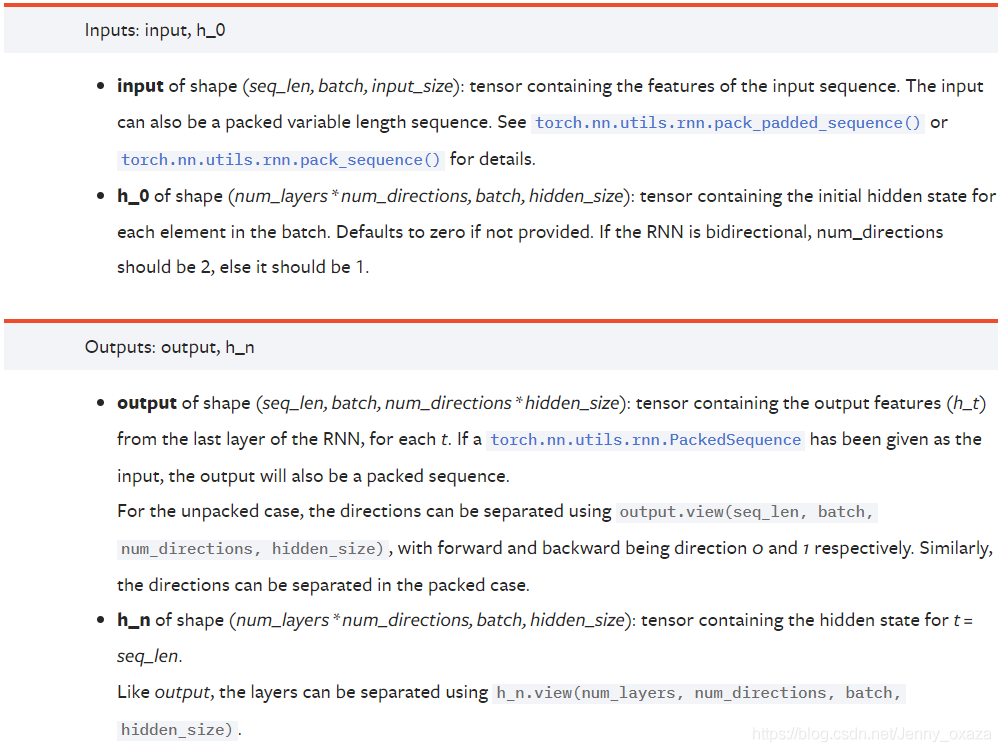
推荐阅读:[PyTorch] rnn,lstm,gru中输入输出维度 网络的输入 网络接收两个输入。 一个是序列输入xt。xt的维度是 (seq_len, batch, input_size),分别表示序列长度、批量和输入的特征维度。 一个是记忆输入h0。h0也叫隐藏状态,输入维度是 (num_layers * num_directions, batch, hidden_size)。如果没有指定h0,则默认为0。如果是单向网络,num_directions=1;如果是双向网络,则num_directions=2。 网络的输出 网络的输出也有两个。 一个是网络的实际输出output。维度是(seq_len, batch, num_directions * hidden_size)。 一个是记忆单元hn,也就是t=seq_len时的隐藏状态。维度是(num_layers * num_directions, batch, hidden_size)。 关于网络的输入和输出,官网的描述比较准确,我感觉我翻译不出那个感觉ε=(´ο`*))):
 我们可以实际操作一下:
我们可以实际操作一下:
<code class="prism language-python has-numbering"><span class="token comment"># 输入</span> rnn_input <span class="token operator">=</span> Variable<span class="token punctuation">(</span>randn<span class="token punctuation">(</span><span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">32</span><span class="token punctuation">,</span> <span class="token number">20</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' 输入大小是 三维tensor[seq_len,batch_size,input_dim] 输入的维度是(100, 32, 20) 表示一个长度为100,批量为32, 维度为20的张量 input_dim是输入的维度,比如是20 batch_size是一次往RNN输入句子的数目,比如是32。 seq_len是一个句子的最大长度,比如100 '''</span> h_0 <span class="token operator">=</span> Variable<span class="token punctuation">(</span>randn<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">32</span><span class="token punctuation">,</span> <span class="token number">50</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' 维度是三维tensor (num_layers * num_directions, batch, hidden_size) 这里网络设置的是单向双层网络,所以第一个维度是 2×1=2 batch_size和上面一样,是32 hidden_size和网络保持一致,是50 '''</span> <span class="token comment">#输出</span> rnn_output<span class="token punctuation">,</span> h_n <span class="token operator">=</span> simple_rnn<span class="token punctuation">(</span>rnn_input<span class="token punctuation">,</span> h_0<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>rnn_output<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: torch.Size([100, 32, 50]) 维度是(seq_len, batch, num_directions * hidden_size) seq_len=100, batch_size = 32, 第三个维度为 1×50=50 '''</span> <span class="token keyword">print</span><span class="token punctuation">(</span>h_n<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: torch.Size([2, 32, 50]) 维度是(num_layers * num_directions, batch, hidden_size) 第一个维度是 2×1=2,第二个维度是 batch_size=32,第三个维度是 hidden_size=50 '''</span> </code>
1.3 循环神经网络的问题
- 不能很好地解决长时依赖问题(long-term dependency problem)。如果记忆的信息和预测的位置跨度太大,网络往往不能记忆这么长时间的信息,而且随着时间跨度越来越大,循环神经网络也越来越难以学习这些信息。
- 在实际应用中,输入和输出很大情况下都不是等长的序列。例如机器翻译中,将英文翻译成中文,输入序列的长度和输出序列的长度基本上都不相等。
针对这些问题,也衍生除了很多RNN的变体,例如Encoder-Decoder、LSTM、GRU等。
2. LSTM(Long Short Term Memory Networks)
推荐阅读/参考文献:
- [译] 理解 LSTM 网络
- 人人都能看懂的LSTM
- 如何简单的理解LSTM——其实没有那么复杂
- Understanding LSTM Networks【必看】(英文好的小伙伴建议直接看这一篇,前面2篇推荐的文章都是基于这篇文章翻译的)
- 动图形象理解LSTM【必看】(这篇文章里面的图感觉更好看且更好看懂一点)
LSTM是一种特殊的RNN,能够学习长期依赖性,旨在通过可以记住长时间段内信息的设计来避免长期依赖性问题。 LSTM的抽象网络结构如下图所示。
:RNN与自然语言处理") 可以看出,LSTM由三个门来控制——输入门、输出门和遗忘门。输入门控制网络的输入,输出门控制网络的输出,遗忘门控制记忆单元,决定之前哪些记忆被保留,哪些记忆被去掉。正是由于遗忘门,使得LSTM具有了长时记忆的功能。此外,对于给定的任务,遗忘门能够自己学习保留多少以前的记忆,这使得不再需要人为干扰,网络就能够自主学习。 LSTM具体的内部结构如下图所示。这也是和普通RNN不一样的地方。
可以看出,LSTM由三个门来控制——输入门、输出门和遗忘门。输入门控制网络的输入,输出门控制网络的输出,遗忘门控制记忆单元,决定之前哪些记忆被保留,哪些记忆被去掉。正是由于遗忘门,使得LSTM具有了长时记忆的功能。此外,对于给定的任务,遗忘门能够自己学习保留多少以前的记忆,这使得不再需要人为干扰,网络就能够自主学习。 LSTM具体的内部结构如下图所示。这也是和普通RNN不一样的地方。
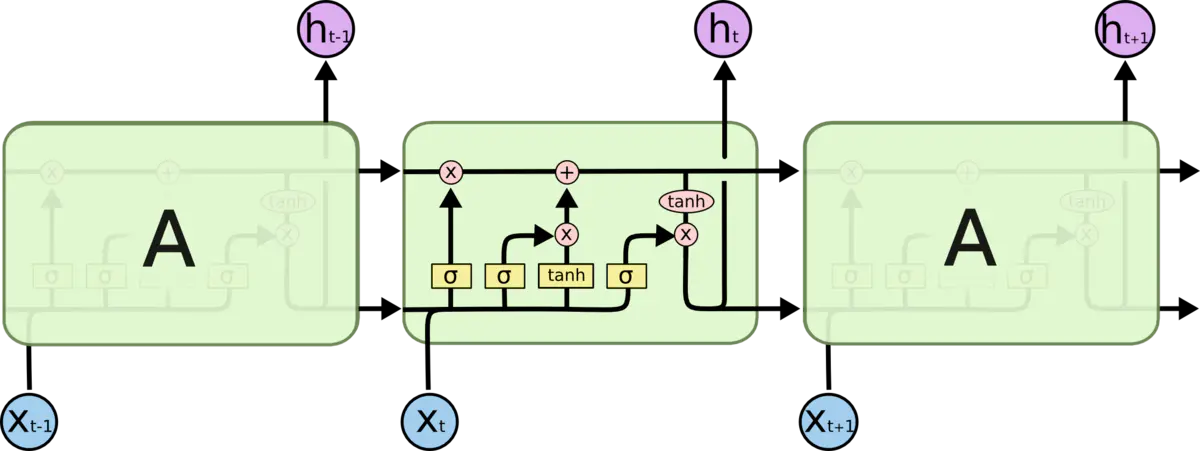 普通RNN的内部只进行一次tanh的计算,只有一个简单的层结构;而LSTM要复杂的多,有四个层结构。RNN只传递一个状态——隐藏状态h;LSTM传递两个状态——细胞状态c和隐藏状态h。
普通RNN的内部只进行一次tanh的计算,只有一个简单的层结构;而LSTM要复杂的多,有四个层结构。RNN只传递一个状态——隐藏状态h;LSTM传递两个状态——细胞状态c和隐藏状态h。
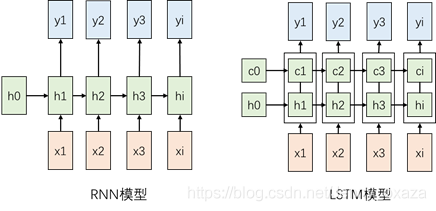 下面依次对LSTM内部的运算方式进行解释。
下面依次对LSTM内部的运算方式进行解释。
2.1 LSTM的内部结构
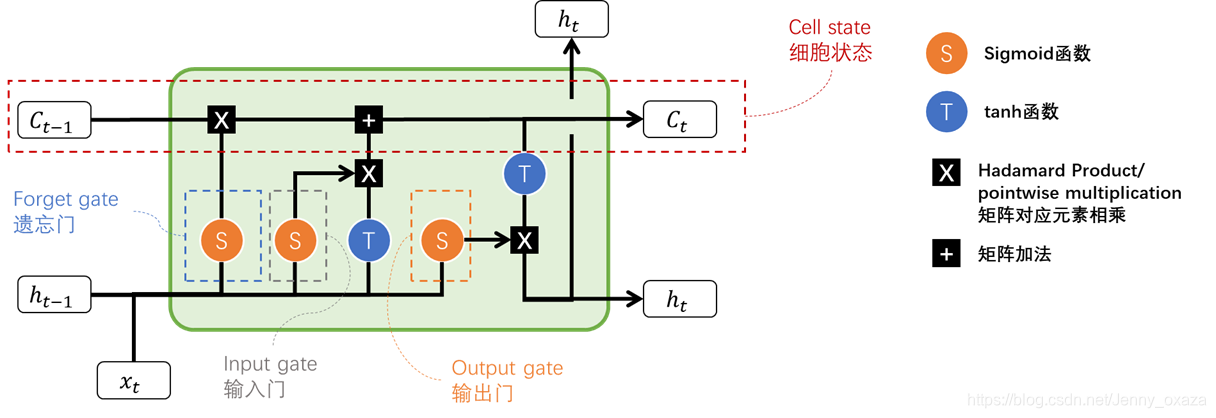 LSTM 的核心概念在于细胞状态以及“门”结构。 细胞状态 细胞状态是LSTM的核心,是模型结构图中最上面的那条直线。细胞状态相当于信息流,可以看到,由于整个信息流上几乎没有复杂的操作,网络能够将序列信息一直保存下去,相当于是网络的“记忆”。 这样一来,即使是很久时间以前的信息也能参与到后面的细胞的计算中,这样就克服了短时记忆的影响。但是我们知道,记忆是会被“筛选”的,就好比我们不会记得上个月第二个周三的晚上吃了什么,但我们会记得恋爱纪念日。那么在细胞状态的信息流中,就有两个重要的操作,分别在图中用两个黑框框表示出来了。
LSTM 的核心概念在于细胞状态以及“门”结构。 细胞状态 细胞状态是LSTM的核心,是模型结构图中最上面的那条直线。细胞状态相当于信息流,可以看到,由于整个信息流上几乎没有复杂的操作,网络能够将序列信息一直保存下去,相当于是网络的“记忆”。 这样一来,即使是很久时间以前的信息也能参与到后面的细胞的计算中,这样就克服了短时记忆的影响。但是我们知道,记忆是会被“筛选”的,就好比我们不会记得上个月第二个周三的晚上吃了什么,但我们会记得恋爱纪念日。那么在细胞状态的信息流中,就有两个重要的操作,分别在图中用两个黑框框表示出来了。
 这两个重要的操作就是遗忘和更新。好比我们的生活体验,说的文艺一点,就是我们每天都会忘记一些昨天的事情,同时我们每天都会产生新的记忆。 那么,我们对忘记多少,又会记得多少呢?这就由各种门结构来影响。 门结构 门结构控制信息的进出和进出的程度。门结构包含一个sigmoid神经网络层和一个按位的乘法操作。通常门结构会选择sigmoid函数是因为sigmoid函数有很好的性质,函数的输出在0~1之间,0表示不允许任何信息通过,1表示任何信息都被允许通过。 推荐阅读: 深度学习计算模型中“门函数(Gating Function)”的作用 LSTM神经网络结构中有三个重要的门——遗忘门、输入门和输出门。这些门通过调节信息流,来确定哪些信息需要保留,哪些信息要被删除(遗忘)。 接下来就重点讨论这些门结构如何影响我们的细胞状态(记忆),又如何进行工作。
这两个重要的操作就是遗忘和更新。好比我们的生活体验,说的文艺一点,就是我们每天都会忘记一些昨天的事情,同时我们每天都会产生新的记忆。 那么,我们对忘记多少,又会记得多少呢?这就由各种门结构来影响。 门结构 门结构控制信息的进出和进出的程度。门结构包含一个sigmoid神经网络层和一个按位的乘法操作。通常门结构会选择sigmoid函数是因为sigmoid函数有很好的性质,函数的输出在0~1之间,0表示不允许任何信息通过,1表示任何信息都被允许通过。 推荐阅读: 深度学习计算模型中“门函数(Gating Function)”的作用 LSTM神经网络结构中有三个重要的门——遗忘门、输入门和输出门。这些门通过调节信息流,来确定哪些信息需要保留,哪些信息要被删除(遗忘)。 接下来就重点讨论这些门结构如何影响我们的细胞状态(记忆),又如何进行工作。
2.1.1 遗忘门
遗忘门的功能是决定应丢弃或保留哪些信息。首先将输入和隐藏状态结合起来,做一个线性变换,最后再经过sigmoid激活函数,得到记忆衰减系数。记忆衰减系数的值在0-1之间,越接近0表示越被忘记;越接近1,表示越应该保留。
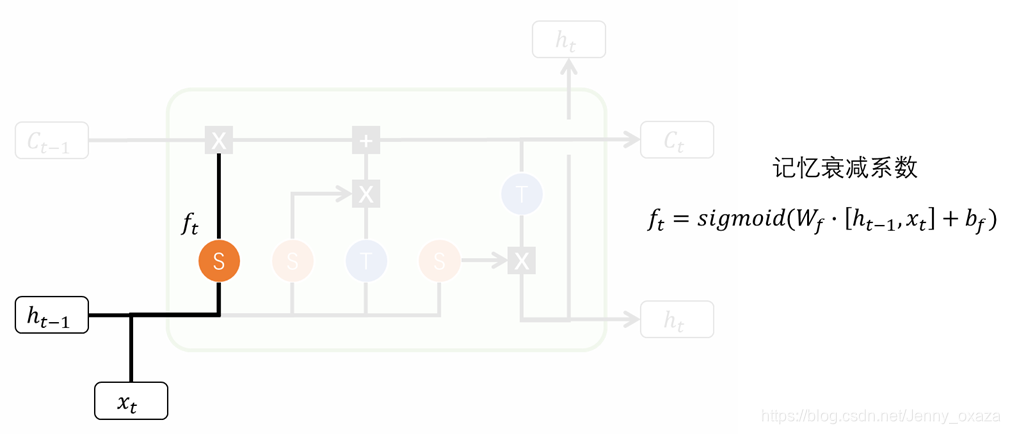
2.1.2 输入门
输入门影响当前获得的记忆。首先,通过输入门计算记忆学习系数(类似记忆衰减系数),该系数影响我们对目前的输入的记忆能力(好比我们能记得今天发生的多少事情)。当前状态学习到的记忆通过线性变换和tanh激活函数得到。
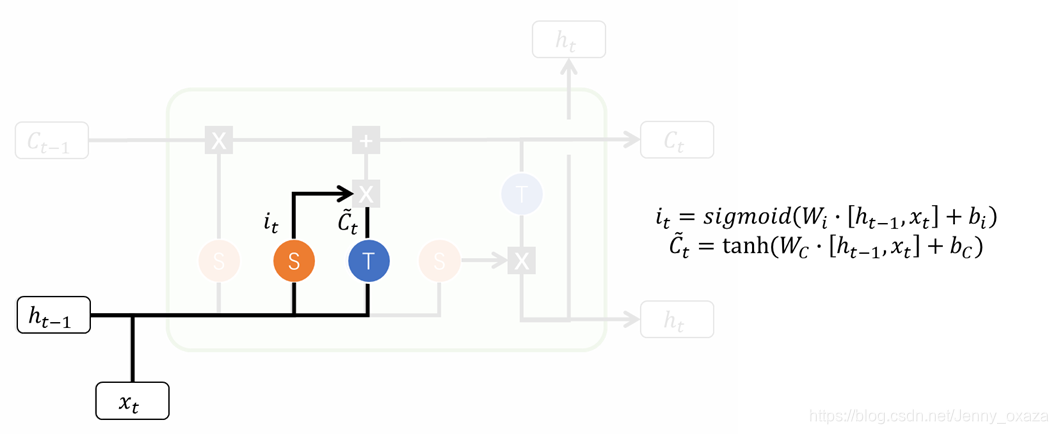
2.1.3 细胞状态的遗忘和更新
有了遗忘门和输入门之后,就可以完成对细胞状态的遗忘和更新两个操作。
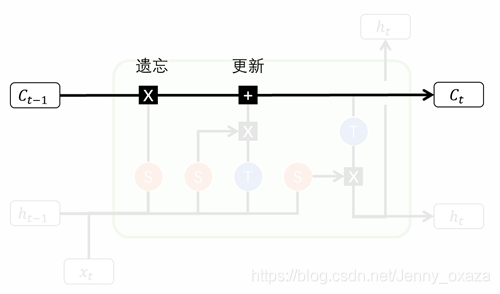
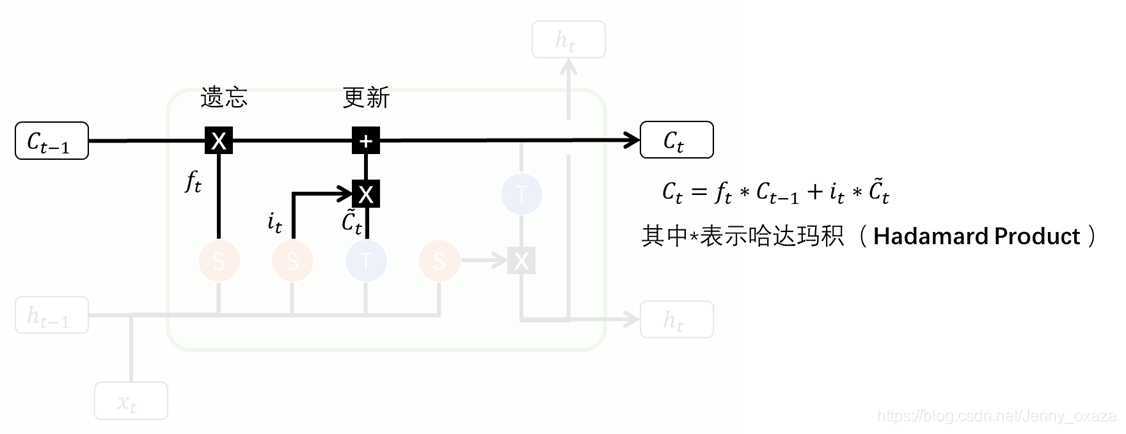 遗忘 在遗忘阶段,我们首先要确定我们对上一状态的记忆还记得多少。那么,就可以通过将上一状态的记忆和遗忘门输出的记忆衰减函数计算哈达玛积来得到。 门结构中包含着 sigmoid 激活函数。经过遗忘门操作以后,记忆衰减系数的元素值都在0-1之间。如果元素值为0,表示完全遗忘,与该元素值相乘即得到0;如果元素值为1,表示完全记得,与该元素值相乘,不发生改变;如果元素值为0-1之间的值,与该元素值相乘,得到的是没有被忘记的记忆。 更新 在更新阶段,我们首先确定我们能记住多少当前状态的记忆——计算记忆学习系数和当前状态学习到的记忆之间的哈达玛积。 接着,把学习到的记忆和没有被忘记的记忆相加,就可以得到经过该记忆操作的细胞状态。
遗忘 在遗忘阶段,我们首先要确定我们对上一状态的记忆还记得多少。那么,就可以通过将上一状态的记忆和遗忘门输出的记忆衰减函数计算哈达玛积来得到。 门结构中包含着 sigmoid 激活函数。经过遗忘门操作以后,记忆衰减系数的元素值都在0-1之间。如果元素值为0,表示完全遗忘,与该元素值相乘即得到0;如果元素值为1,表示完全记得,与该元素值相乘,不发生改变;如果元素值为0-1之间的值,与该元素值相乘,得到的是没有被忘记的记忆。 更新 在更新阶段,我们首先确定我们能记住多少当前状态的记忆——计算记忆学习系数和当前状态学习到的记忆之间的哈达玛积。 接着,把学习到的记忆和没有被忘记的记忆相加,就可以得到经过该记忆操作的细胞状态。
2.1.4 输出门
输出门确定下一个隐藏状态的值。它的工作原理和输入门、遗忘门一样。
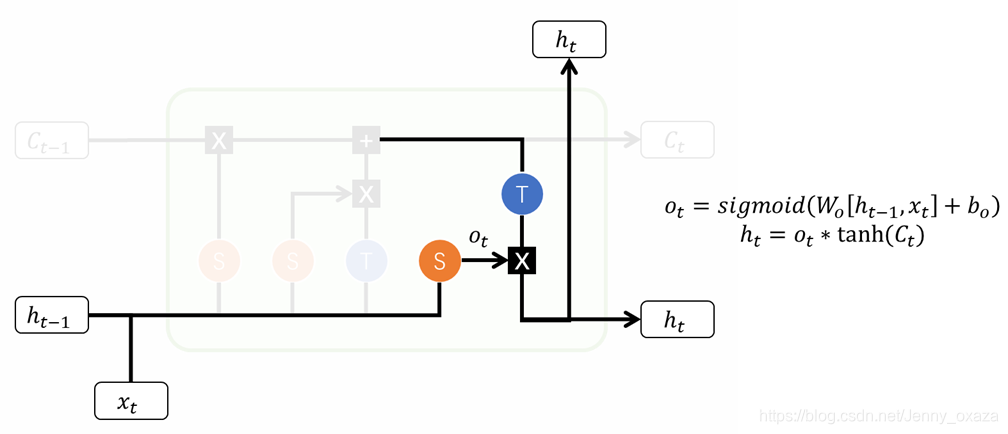 关于这三个门的关系,推荐知乎@刘冬煜的回答,我觉得特别形象:
关于这三个门的关系,推荐知乎@刘冬煜的回答,我觉得特别形象:
图中有三个Sigmoid门结构,自左向右依次是遗忘门(f)、输入门(i)、输出门(o)。由于Sigmoid函数将输入映射到(0, 1)区间的特点,这三个门分别决定了长期记忆流的保留程度、输入单元的嵌入程度、短期记忆流的呈现程度。其原因很容易理解,如果Sigmoid输出为1代表信息完全保留,输出为0代表信息完全丢弃,而在0和1之间则代表了信息不完全保留而有所丢弃。 事实上,去掉f、i、o中的任意一个门,网络的实际效果也并不会太差,但确实不如标准的LSTM——这还是很容易理解的,我们人类一天会记住很多信息,但遗忘、捕获和表达却是有一定独立性的。
2.2 利用PyTorch实现LSTM
在PyTorch里面调用LSTM只需要使用 nn.LSTM() 即可。相关参数的含义和RNN的一样,具体的可以看官网的介绍。参数的访问方式也是一样的,不同的地方在于LSTM的参数比标准RNN的多,其维度是RNN维度的4倍,因为LSTM中间比标准RNN多了三个线性变换,多的三个线性变换的权重拼在一起,所以一共是4倍。
<code class="prism language-python has-numbering">simple_rnn <span class="token operator">=</span> nn<span class="token punctuation">.</span>RNN<span class="token punctuation">(</span>input_size <span class="token operator">=</span> <span class="token number">20</span><span class="token punctuation">,</span> hidden_size <span class="token operator">=</span> <span class="token number">50</span><span class="token punctuation">,</span> num_layers <span class="token operator">=</span> <span class="token number">2</span><span class="token punctuation">)</span>
lstm <span class="token operator">=</span> nn<span class="token punctuation">.</span>LSTM<span class="token punctuation">(</span>input_size <span class="token operator">=</span> <span class="token number">20</span><span class="token punctuation">,</span> hidden_size <span class="token operator">=</span> <span class="token number">50</span><span class="token punctuation">,</span> num_layers <span class="token operator">=</span> <span class="token number">2</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'simple_rnn_weight_ih_l0_size: {}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>simple_rnn<span class="token punctuation">.</span>weight_ih_l0<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'LSTM_weight_ih_l0_size:{}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>lstm<span class="token punctuation">.</span>weight_ih_l0<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
simple_rnn_weight_ih_l0_size: torch.Size([50, 20])
LSTM_weight_ih_l0_size:torch.Size([200, 20])
'''</span>
</code>
其次,LSTM的输入和输出不再只有序列输入和隐藏状态,还多了一个细胞状态。
<code class="prism language-python has-numbering">lstm_input <span class="token operator">=</span> Variable<span class="token punctuation">(</span>randn<span class="token punctuation">(</span><span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">32</span><span class="token punctuation">,</span> <span class="token number">20</span><span class="token punctuation">)</span><span class="token punctuation">)</span> lstm_out<span class="token punctuation">,</span> <span class="token punctuation">(</span>h_n<span class="token punctuation">,</span> c_n<span class="token punctuation">)</span> <span class="token operator">=</span> lstm<span class="token punctuation">(</span>lstm_input<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>lstm_out<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>h_n<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>c_n<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: torch.Size([100, 32, 50]) torch.Size([2, 32, 50]) torch.Size([2, 32, 50]) '''</span> </code>
3. 【案例一】小试牛刀:使用LSTM进行图片分类
完整代码参考廖老师的github:RNN 做图像分类 循环神经网络特别适用于序列数据,要想利用循环神经网络进行图片分类,首先就是要把图片数据转化成一个序列数据。 这里我们利用之前用到的MNIST手写数字图片数据集进行案例应用。对于一张手写字体的图片,其大小是 28 * 28,我们可以将其看做是一个长为 28 的序列,每个序列的特征都是 28; 定义用于图片分类的循环神经网络
<code class="prism language-python has-numbering"><span class="token comment"># 定义用于图片分类的循环神经网络</span>
<span class="token keyword">class</span> <span class="token class-name">rnn_classify</span><span class="token punctuation">(</span>nn<span class="token punctuation">.</span>Module<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> in_feature<span class="token operator">=</span><span class="token number">28</span><span class="token punctuation">,</span> hidden_feature<span class="token operator">=</span><span class="token number">100</span><span class="token punctuation">,</span> num_class<span class="token operator">=</span><span class="token number">10</span><span class="token punctuation">,</span> num_layers<span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token builtin">super</span><span class="token punctuation">(</span>rnn_classify<span class="token punctuation">,</span> self<span class="token punctuation">)</span><span class="token punctuation">.</span>__init__<span class="token punctuation">(</span><span class="token punctuation">)</span>
self<span class="token punctuation">.</span>rnn <span class="token operator">=</span> nn<span class="token punctuation">.</span>LSTM<span class="token punctuation">(</span>in_feature<span class="token punctuation">,</span> hidden_feature<span class="token punctuation">,</span> num_layers<span class="token punctuation">)</span> <span class="token comment"># 使用两层 lstm</span>
self<span class="token punctuation">.</span>classifier <span class="token operator">=</span> nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>hidden_feature<span class="token punctuation">,</span> num_class<span class="token punctuation">)</span> <span class="token comment"># 将最后一个 rnn 的输出使用全连接得到最后的分类结果</span>
<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token triple-quoted-string string">'''
x 大小为 (batch, 1, 28, 28),所以我们需要将其转换成 RNN 的输入形式,即 (28, batch, 28)
'''</span>
x <span class="token operator">=</span> x<span class="token punctuation">.</span>squeeze<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token comment"># 去掉 (batch, 1, 28, 28) 中的 1,变成 (batch, 28, 28)</span>
x <span class="token operator">=</span> x<span class="token punctuation">.</span>permute<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token comment"># 将最后一维放到第一维,变成 (28, batch, 28)</span>
out<span class="token punctuation">,</span> _ <span class="token operator">=</span> self<span class="token punctuation">.</span>rnn<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 使用默认的隐藏状态,得到的 out 是 (28, batch, hidden_feature)</span>
out <span class="token operator">=</span> out<span class="token punctuation">[</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">]</span> <span class="token comment"># 取序列中的最后一个,大小是 (batch, hidden_feature)</span>
out <span class="token operator">=</span> self<span class="token punctuation">.</span>classifier<span class="token punctuation">(</span>out<span class="token punctuation">)</span> <span class="token comment"># 得到分类结果</span>
<span class="token keyword">return</span> out
</code>
这个图片分类器主要由LSTM网络和线性网络构成。LSTM网络接收图片的序列,线性网络将它输出成最后的概率向量。 因为处理的是图片数据,往往是batch放在前面,所以设置 bacth_first = True。这样网络的输出也是batch放在前面。 因为循环神经网络的输出也是一个序列,但是我们只想要这些序列中的一个结果。那保留最后一个结果自然是最好的,因为最后一个结果记忆的图片信息最多,因此这里要进行一个 out = out[:, -1, :] 的操作。 训练结果
<code class="prism language-python has-numbering">Epoch <span class="token number">0</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">2.300989</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.108400</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">2.297259</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.113518</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">1</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">2.291054</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.117533</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">2.275467</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.142173</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">32</span> Epoch <span class="token number">2</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">2.120327</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.208700</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">1.911413</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.267772</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">3</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">1.694258</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.386183</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">1.473689</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.502696</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">4</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">1.265647</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.580450</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">1.083146</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.644069</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">5</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">0.957952</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.685917</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">0.845352</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.738019</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">6</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">0.757960</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.767317</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">0.681056</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.801617</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">33</span> Epoch <span class="token number">7</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">0.608743</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.821900</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">0.547598</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.844249</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">34</span> Epoch <span class="token number">8</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">0.499851</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.855733</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">0.452200</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.871206</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> Epoch <span class="token number">9</span><span class="token punctuation">.</span> Train Loss<span class="token punctuation">:</span> <span class="token number">0.420936</span><span class="token punctuation">,</span> Train Acc<span class="token punctuation">:</span> <span class="token number">0.878233</span><span class="token punctuation">,</span> Valid Loss<span class="token punctuation">:</span> <span class="token number">0.383465</span><span class="token punctuation">,</span> Valid Acc<span class="token punctuation">:</span> <span class="token number">0.890176</span><span class="token punctuation">,</span> Time <span class="token number">00</span><span class="token punctuation">:</span><span class="token number">00</span><span class="token punctuation">:</span><span class="token number">31</span> </code>
可以看到,循环神经网络在图片分类上的效果还是可以的,10轮训练就有将近90%的准确率。但是,循环神经网络还是不适合处理图片分类,主要有以下两个原因:
- 图片的序列关系不明确。对于一张图片,可以从上往下看,也可以从左往右看。
- 当图片很大时,循环神经网络会变得非常非常慢。
4. 【案例二】循环神经网络真正适用的场景:序列预测
4.1 数据准备
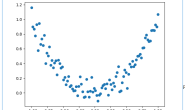
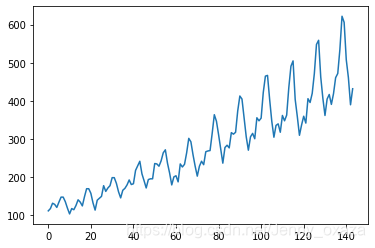
数据下载 读入的数据是2010年的飞机月流量,数据可视化如下图所示。
 我们的目标是使用前几个月的流量,预测当前月的流量。所以可以建立以下数据集。
我们的目标是使用前几个月的流量,预测当前月的流量。所以可以建立以下数据集。
<code class="prism language-python has-numbering"><span class="token comment"># 数据预处理</span>
data_csv <span class="token operator">=</span> data_csv<span class="token punctuation">.</span>dropna<span class="token punctuation">(</span><span class="token punctuation">)</span>
dataset <span class="token operator">=</span> data_csv<span class="token punctuation">.</span>values
dataset <span class="token operator">=</span> dataset<span class="token punctuation">.</span>astype<span class="token punctuation">(</span><span class="token string">'float32'</span><span class="token punctuation">)</span>
<span class="token comment"># 对数据进行标准化</span>
max_value <span class="token operator">=</span> np<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>dataset<span class="token punctuation">)</span>
min_value <span class="token operator">=</span> np<span class="token punctuation">.</span><span class="token builtin">min</span><span class="token punctuation">(</span>dataset<span class="token punctuation">)</span>
scalar <span class="token operator">=</span> max_value <span class="token operator">-</span>min_value
dataset <span class="token operator">=</span> <span class="token builtin">list</span><span class="token punctuation">(</span><span class="token builtin">map</span><span class="token punctuation">(</span><span class="token keyword">lambda</span> x<span class="token punctuation">:</span> x<span class="token operator">/</span>scalar<span class="token punctuation">,</span> dataset<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token comment"># 创建数据集</span>
<span class="token keyword">def</span> <span class="token function">create_dataset</span><span class="token punctuation">(</span>dataset<span class="token punctuation">,</span> look_back <span class="token operator">=</span> <span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
dataX<span class="token punctuation">,</span> dataY <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token punctuation">]</span>
<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>dataset<span class="token punctuation">)</span><span class="token operator">-</span>look_back<span class="token punctuation">)</span><span class="token punctuation">:</span>
a <span class="token operator">=</span> dataset<span class="token punctuation">[</span>i<span class="token punctuation">:</span><span class="token punctuation">(</span>i<span class="token operator">+</span>look_back<span class="token punctuation">)</span><span class="token punctuation">]</span>
dataX<span class="token punctuation">.</span>append<span class="token punctuation">(</span>a<span class="token punctuation">)</span>
dataY<span class="token punctuation">.</span>append<span class="token punctuation">(</span>dataset<span class="token punctuation">[</span>i<span class="token operator">+</span>look_back<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>dataX<span class="token punctuation">)</span><span class="token punctuation">,</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>dataY<span class="token punctuation">)</span>
data_X<span class="token punctuation">,</span> data_Y <span class="token operator">=</span> create_dataset<span class="token punctuation">(</span>dataset<span class="token punctuation">)</span>
</code>
这里的look_back=2表示希望通过前两个月的流量来预测当月的流量。因此,输入样本的序列就是前两个月的流量,输出的是当月的流量。
:RNN与自然语言处理") 建立好数据之后,需要划分训练集和验证集(7:3)。
建立好数据之后,需要划分训练集和验证集(7:3)。
<code class="prism language-python has-numbering"><span class="token comment"># 划分训练集和测试集,70% 作为训练集</span> train_size <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>data_X<span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token number">0.7</span><span class="token punctuation">)</span> test_size <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>data_X<span class="token punctuation">)</span> <span class="token operator">-</span> train_size train_X <span class="token operator">=</span> data_X<span class="token punctuation">[</span><span class="token punctuation">:</span>train_size<span class="token punctuation">]</span> train_Y <span class="token operator">=</span> data_Y<span class="token punctuation">[</span><span class="token punctuation">:</span>train_size<span class="token punctuation">]</span> test_X <span class="token operator">=</span> data_X<span class="token punctuation">[</span>train_size<span class="token punctuation">:</span><span class="token punctuation">]</span> test_Y <span class="token operator">=</span> data_Y<span class="token punctuation">[</span>train_size<span class="token punctuation">:</span><span class="token punctuation">]</span> </code>
为了能够使用LSTM,我们还需要改变一下数据的维度。
<code class="prism language-python has-numbering"><span class="token comment"># 改变数据的维度</span> train_X <span class="token operator">=</span> train_X<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">)</span> train_Y <span class="token operator">=</span> train_Y<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span> test_X <span class="token operator">=</span> test_X<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">)</span> train_x <span class="token operator">=</span> torch<span class="token punctuation">.</span>from_numpy<span class="token punctuation">(</span>train_X<span class="token punctuation">)</span> train_y <span class="token operator">=</span> torch<span class="token punctuation">.</span>from_numpy<span class="token punctuation">(</span>train_Y<span class="token punctuation">)</span> test_x <span class="token operator">=</span> torch<span class="token punctuation">.</span>from_numpy<span class="token punctuation">(</span>test_X<span class="token punctuation">)</span> </code>
这里只有一个序列,所以 batch 是 1,而输入的 feature 就是我们希望依据的几个月份,这里我们定的是两个月份,所以 feature 就是 2。
4.2 搭建网络模型
<code class="prism language-python has-numbering"><span class="token comment"># 定义模型</span>
<span class="token keyword">class</span> <span class="token class-name">lstm_reg</span><span class="token punctuation">(</span>nn<span class="token punctuation">.</span>Module<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> input_size<span class="token punctuation">,</span> hidden_size<span class="token punctuation">,</span> output_size<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">,</span> num_layers<span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token builtin">super</span><span class="token punctuation">(</span>lstm_reg<span class="token punctuation">,</span> self<span class="token punctuation">)</span><span class="token punctuation">.</span>__init__<span class="token punctuation">(</span><span class="token punctuation">)</span>
self<span class="token punctuation">.</span>rnn <span class="token operator">=</span> nn<span class="token punctuation">.</span>LSTM<span class="token punctuation">(</span>input_size<span class="token punctuation">,</span> hidden_size<span class="token punctuation">,</span> num_layers<span class="token punctuation">)</span> <span class="token comment"># rnn</span>
self<span class="token punctuation">.</span>reg <span class="token operator">=</span> nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>hidden_size<span class="token punctuation">,</span> output_size<span class="token punctuation">)</span> <span class="token comment"># 回归</span>
<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span>
x<span class="token punctuation">,</span> _ <span class="token operator">=</span> self<span class="token punctuation">.</span>rnn<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># (seq, batch, hidden)</span>
s<span class="token punctuation">,</span> b<span class="token punctuation">,</span> h <span class="token operator">=</span> x<span class="token punctuation">.</span>shape
x <span class="token operator">=</span> x<span class="token punctuation">.</span>view<span class="token punctuation">(</span>s<span class="token operator">*</span>b<span class="token punctuation">,</span> h<span class="token punctuation">)</span> <span class="token comment"># 转换成线性层的输入格式</span>
x <span class="token operator">=</span> self<span class="token punctuation">.</span>reg<span class="token punctuation">(</span>x<span class="token punctuation">)</span>
x <span class="token operator">=</span> x<span class="token punctuation">.</span>view<span class="token punctuation">(</span>s<span class="token punctuation">,</span> b<span class="token punctuation">,</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> x
net <span class="token operator">=</span> lstm_reg<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">4</span><span class="token punctuation">)</span>
criterion <span class="token operator">=</span> nn<span class="token punctuation">.</span>MSELoss<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer <span class="token operator">=</span> torch<span class="token punctuation">.</span>optim<span class="token punctuation">.</span>Adam<span class="token punctuation">(</span>net<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">1e</span><span class="token operator">-</span><span class="token number">2</span><span class="token punctuation">)</span>
</code>
网络模型特别简单,一层LSTM层用于记住序列特征,一层线性层用于预测。在前向传播过程中,我们只关注得到的序列,由于线性层不接受三维输入,所以要将得到的序列转化成一维向量,经过线性层预测后再分开。
4.3 开始训练
<code class="prism language-python has-numbering"><span class="token comment"># 开始训练</span>
<span class="token keyword">for</span> e <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">1000</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
var_x <span class="token operator">=</span> Variable<span class="token punctuation">(</span>train_x<span class="token punctuation">)</span>
var_y <span class="token operator">=</span> Variable<span class="token punctuation">(</span>train_y<span class="token punctuation">)</span>
<span class="token comment"># 前向传播</span>
out <span class="token operator">=</span> net<span class="token punctuation">(</span>var_x<span class="token punctuation">)</span>
loss <span class="token operator">=</span> criterion<span class="token punctuation">(</span>out<span class="token punctuation">,</span> var_y<span class="token punctuation">)</span>
<span class="token comment"># 反向传播</span>
optimizer<span class="token punctuation">.</span>zero_grad<span class="token punctuation">(</span><span class="token punctuation">)</span>
loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer<span class="token punctuation">.</span>step<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> <span class="token punctuation">(</span>e <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">%</span> <span class="token number">100</span> <span class="token operator">==</span> <span class="token number">0</span><span class="token punctuation">:</span> <span class="token comment"># 每 100 次输出结果</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'Epoch: {}, Loss: {:.5f}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>e <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">,</span> loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
</code>
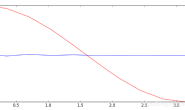
可以将模型预测的数据和真实数据放在一起对比,整体效果还是不错的:
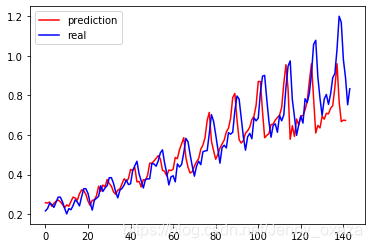
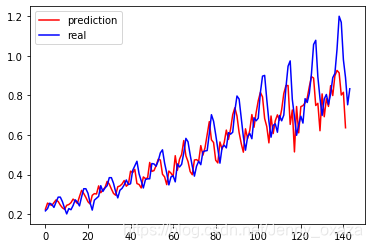 我们可以增加以下hidden_size的大小,设置hidden_size=5,模型的效果会更好。这是因为隐藏状态的维度增加,模型的序列记忆更多了,也就更加准确。
我们可以增加以下hidden_size的大小,设置hidden_size=5,模型的效果会更好。这是因为隐藏状态的维度增加,模型的序列记忆更多了,也就更加准确。
5. LSTM与自然语言处理
自然语言处理是LSTM最典型的应用场景。在使用LSTM之前,需要对文本数据进行一系列处理。这里简单介绍一些概念,如果要系统地学习自然语言处理,建议还是去学习一下斯坦福cs224n这门课程。
5.1 自然语言处理基础
5.1.1 分词
将一个句子分为字符或词的过程称为分词。Python里面有一些内置的函数(如split和token)可以处理文本分词。
<code class="prism language-python has-numbering">text <span class="token operator">=</span> <span class="token string">'Father borrowed money form his rich cousins to start a small jewellery shop, His chief customers were his old college friends.'</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token builtin">list</span><span class="token punctuation">(</span>text<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: ['F', 'a', 't', 'h', 'e', 'r', ' ', 'b', 'o', 'r', 'r', 'o', 'w', 'e', 'd', ' ', 'm', 'o', 'n', 'e', 'y', ' ', 'f', 'o', 'r', 'm', ' ', 'h', 'i', 's', ' ', 'r', 'i', 'c', 'h', ' ', 'c', 'o', 'u', 's', 'i', 'n', 's', ' ', 't', 'o', ' ', 's', 't', 'a', 'r', 't', ' ', 'a', ' ', 's', 'm', 'a', 'l', 'l', ' ', 'j', 'e', 'w', 'e', 'l', 'l', 'e', 'r', 'y', ' ', 's', 'h', 'o', 'p', ',', ' ', 'H', 'i', 's', ' ', 'c', 'h', 'i', 'e', 'f', ' ', 'c', 'u', 's', 't', 'o', 'm', 'e', 'r', 's', ' ', 'w', 'e', 'r', 'e', ' ', 'h', 'i', 's', ' ', 'o', 'l', 'd', ' ', 'c', 'o', 'l', 'l', 'e', 'g', 'e', ' ', 'f', 'r', 'i', 'e', 'n', 'd', 's', '.'] '''</span> <span class="token keyword">print</span><span class="token punctuation">(</span>text<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># 默认情况下,split采用空格来分隔</span> <span class="token triple-quoted-string string">''' out: ['Father', 'borrowed', 'money', 'form', 'his', 'rich', 'cousins', 'to', 'start', 'a', 'small', 'jewellery', 'shop,', 'His', 'chief', 'customers', 'were', 'his', 'old', 'college', 'friends.'] '''</span> <span class="token keyword">print</span><span class="token punctuation">(</span>text<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token string">','</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: ['Father borrowed money form his rich cousins to start a small jewellery shop', ' His chief customers were his old college friends.'] '''</span> </code>
对于中文的处理,推荐阅读:
5.1.2 N Gram模型
推荐阅读:
Python的nltk包可以实现n-gram表示。
<code class="prism language-python has-numbering"><span class="token keyword">from</span> nltk <span class="token keyword">import</span> ngrams
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token builtin">list</span><span class="token punctuation">(</span>ngrams<span class="token punctuation">(</span>text<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
[('Father', 'borrowed'), ('borrowed', 'money'), ('money', 'form'), ('form', 'his'), ('his', 'rich'), ('rich', 'cousins'), ('cousins', 'to'), ('to', 'start'), ('start', 'a'), ('a', 'small'), ('small', 'jewellery'), ('jewellery', 'shop,'), ('shop,', 'His'), ('His', 'chief'), ('chief', 'customers'), ('customers', 'were'), ('were', 'his'), ('his', 'old'), ('old', 'college'), ('college', 'friends.')]
'''</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token builtin">list</span><span class="token punctuation">(</span>ngrams<span class="token punctuation">(</span>text<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token number">3</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
[('Father', 'borrowed', 'money'), ('borrowed', 'money', 'form'), ('money', 'form', 'his'), ('form', 'his', 'rich'), ('his', 'rich', 'cousins'), ('rich', 'cousins', 'to'), ('cousins', 'to', 'start'), ('to', 'start', 'a'), ('start', 'a', 'small'), ('a', 'small', 'jewellery'), ('small', 'jewellery', 'shop,'), ('jewellery', 'shop,', 'His'), ('shop,', 'His', 'chief'), ('His', 'chief', 'customers'), ('chief', 'customers', 'were'), ('customers', 'were', 'his'), ('were', 'his', 'old'), ('his', 'old', 'college'), ('old', 'college', 'friends.')]
'''</span>
</code>
n-gram表示法的一个问题在于失去了文本的额顺序性,通常它会和浅层机器学习模型一起使用。这种技术目前很少应用于深度学习,因为RNN等深度学习架构会自动学习这些表示法。
5.1.3 词嵌入(Word Embedding)
要让深度学习能够学习文本,首先要让文本变成向量。对于每个单词来说,他有两种向量表示方式——独热编码(one-hot)和词嵌入(word embedding)。 对于这两种表示方式的区别推荐阅读:Word Embedding&word2vec 在Pytorch里面,词嵌入通过函数 nn.Embedding(m,n) 来实现。其中m表示所有的单词数目,n表示词嵌入的维度。
<code class="prism language-python has-numbering"><span class="token keyword">import</span> torch
<span class="token keyword">from</span> torch <span class="token keyword">import</span> nn
<span class="token keyword">from</span> torch<span class="token punctuation">.</span>autograd <span class="token keyword">import</span> Variable
<span class="token comment"># 定义词嵌入</span>
embeds <span class="token operator">=</span> nn<span class="token punctuation">.</span>Embedding<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span> <span class="token comment"># 2 个单词,维度 5</span>
<span class="token comment"># 得到词嵌入矩阵</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>embeds<span class="token punctuation">.</span>weight<span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
Parameter containing:
tensor([[ 0.0424, 0.4599, 0.9241, -0.7641, -1.3289],
[-0.6479, 1.2009, -0.7487, -0.6281, 0.5704]], requires_grad=True)
'''</span>
</code>
我们可以通过embeds.weight来访问词嵌入的转换矩阵,矩阵的初始值随机分配(服从标准正态分布)。在网络训练的过程中,embeds.weight会不断地学习、更新。我们也可以手动修改这个词向量:
<code class="prism language-python has-numbering"><span class="token comment"># 直接手动修改词嵌入的值</span>
embeds<span class="token punctuation">.</span>weight<span class="token punctuation">.</span>data <span class="token operator">=</span> torch<span class="token punctuation">.</span>ones<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>embeds<span class="token punctuation">.</span>weight<span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
Parameter containing:
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]], requires_grad=True)
'''</span>
</code>
如果我们要访问其中一个单词的词向量,我们可以直接调用定义好的词嵌入,但是输入必须传入一个 Variable,且类型是 LongTensor。
<code class="prism language-python has-numbering"><span class="token comment"># 访问第 50 个词的词向量</span>
embeds <span class="token operator">=</span> nn<span class="token punctuation">.</span>Embedding<span class="token punctuation">(</span><span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">10</span><span class="token punctuation">)</span>
single_word_embed <span class="token operator">=</span> embeds<span class="token punctuation">(</span>Variable<span class="token punctuation">(</span>torch<span class="token punctuation">.</span>LongTensor<span class="token punctuation">(</span><span class="token punctuation">[</span><span class="token number">50</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>single_word_embed<span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
tensor([[ 0.6256, -1.2384, -0.1407, -0.1965, -0.9944, 1.5932, 0.3888, 0.4468,
-0.8390, -1.2636]], grad_fn=<EmbeddingBackward>)
'''</span>
</code>
很多时候为了得到更高的准确率,我们往往会在NLP任务中使用已经预训练好的词向量。
5.2 【案例三】基于词向量构建情感分类器
在进行自然语言处理时,可以使用torchtext库,这个库可以帮助我们很容易地实现下载、向量化文本和批处理等操作。 推荐阅读/参考文献: pytorch学习笔记(十九):torchtext [TorchText]使用 Pytorch学习记录-更深的TorchText学习01 第一篇参考文献总结的特别有条理,我把文中整理的框架贴在这里:

5.2.1 数据准备
首先,定义两个torchtext.data.Field。
<code class="prism language-python has-numbering">TEXT <span class="token operator">=</span> data<span class="token punctuation">.</span>Field<span class="token punctuation">(</span>lower<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">,</span> batch_first<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">,</span>fix_length<span class="token operator">=</span><span class="token number">20</span><span class="token punctuation">)</span> LABEL <span class="token operator">=</span> data<span class="token punctuation">.</span>Field<span class="token punctuation">(</span>sequential<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">)</span> </code>
这里的data.Field,官网上的定义是:
Defines a datatype together with instructions for converting to Tensor.
我觉得可以理解为前面做图像处理时的transforms的作用。也就是说,data.Field定义了你对这些文本数据的处理。 TEXT用于实际的文本,lower=True表示将文本全部转换成小写形式(默认情况下lower=False,为False时表示不进行上述操作);batch_first=True表示将文本转化成张量(默认情况下batch_first=False);fix_length表示把所有的文本扩充到一定的长度。 LABEL用于标签数据。sequential表示是否切分数据,如果数据已经是序列化的了而且是数字类型的,则应该传递参数use_vocab = False和sequential = False。 定义好数据之后,就可以从torchtext.datasets中下载IMDB数据,并按照上面定义好的Field拆分成训练集和测试集。
<code class="prism language-python has-numbering">train<span class="token punctuation">,</span> test <span class="token operator">=</span> datasets<span class="token punctuation">.</span>IMDB<span class="token punctuation">.</span>splits<span class="token punctuation">(</span>TEXT<span class="token punctuation">,</span> LABEL<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token builtin">type</span><span class="token punctuation">(</span>train<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token triple-quoted-string string">''' out: <class 'torchtext.datasets.imdb.IMDB'> '''</span> </code>
可以看到,IMDB数据集拆分成了train和test两个数据库。trian.fields中包含一个字典,其中’text’是key,label是value。train数据集中一共包含25000个样本;该数据集的每个样本都包括已经分好词的文本以及分类标签。
<code class="prism language-python has-numbering"><span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'train.fields'</span><span class="token punctuation">,</span> train<span class="token punctuation">.</span>fields<span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
train.fields {'text': <torchtext.data.field.Field object at 0x000001E5326EB160>, 'label': <torchtext.data.field.Field object at 0x000001E555392B38>}
'''</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'len(train)'</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>train<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
len(train) 25000
'''</span>
<span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'vars(train[0])'</span><span class="token punctuation">,</span> <span class="token builtin">vars</span><span class="token punctuation">(</span>train<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token triple-quoted-string string">'''
out:
vars(train[0]) {'text': ['bromwell', 'high', 'is', 'a', 'cartoon', 'comedy.', 'it', 'ran', 'at', 'the', 'same', 'time', 'as', 'some', 'other', 'programs', 'about', 'school', 'life,', 'such', 'as', '"teachers".', 'my', '35', 'years', 'in', 'the', 'teaching', 'profession', 'lead', 'me', 'to', 'believe', 'that', 'bromwell', "high's", 'satire', 'is', 'much', 'closer', 'to', 'reality', 'than', 'is', '"teachers".', 'the', 'scramble', 'to', 'survive', 'financially,', 'the', 'insightful', 'students', 'who', 'can', 'see', 'right', 'through', 'their', 'pathetic', "teachers'", 'pomp,', 'the', 'pettiness', 'of', 'the', 'whole', 'situation,', 'all', 'remind', 'me', 'of', 'the', 'schools', 'i', 'knew', 'and', 'their', 'students.', 'when', 'i', 'saw', 'the', 'episode', 'in', 'which', 'a', 'student', 'repeatedly', 'tried', 'to', 'burn', 'down', 'the', 'school,', 'i', 'immediately', 'recalled', '.........', 'at', '..........', 'high.', 'a', 'classic', 'line:', 'inspector:', "i'm", 'here', 'to', 'sack', 'one', 'of', 'your', 'teachers.', 'student:', 'welcome', 'to', 'bromwell', 'high.', 'i', 'expect', 'that', 'many', 'adults', 'of', 'my', 'age', 'think', 'that', 'bromwell', 'high', 'is', 'far', 'fetched.', 'what', 'a', 'pity', 'that', 'it', "isn't!"], 'label': 'pos'}
'''</span>
</code>
5.2.2 构建词表
torchtext.data.Field对象提供了build_vocab方法来帮助构建词表。 词表对象trochtext.vocab包含以下参数:
 从训练集中构建词表的代码如下。文本数据的词表最多包含10000个词,并删除了出现频次不超过10的词。
从训练集中构建词表的代码如下。文本数据的词表最多包含10000个词,并删除了出现频次不超过10的词。
<code class="prism language-python has-numbering">TEXT<span class="token punctuation">.</span>build_vocab<span class="token punctuation">(</span>train<span class="token punctuation">,</span> dim<span class="token operator">=</span><span class="token number">300</span><span class="token punctuation">,</span>max_size<span class="token operator">=</span><span class="token number">10000</span><span class="token punctuation">,</span>min_freq<span class="token operator">=</span><span class="token number">20</span><span class="token punctuation">)</span> LABEL<span class="token punctuation">.</span>build_vocab<span class="token punctuation">(</span>train<span class="token punctuation">)</span> </code>
TEXT.vocab类的三个variables,可以返回我们需要的属性。(参考:[TorchText]词向量) freqs 用来返回每一个单词和其对应的频数。 itos 按照下标的顺序返回每一个单词。 stoi 返回每一个单词与其对应的下标,即返回词索引。 vectors返回单词的词向量。
pytorch学习笔记(十九):torchtext: 为什么使用 Field 抽象: torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。 Field: 定义对应字段的处理操作 Vocab: 定义了 词汇表 Vectors: 用来保存预训练好的 word vectors
5.2.3 生成向量的批数据(构建迭代器)
trochtext提供了BucketIterator,可以帮助我们批处理所有文本并将词替换成词的索引。如果序列的长度差异很大,则填充将消耗大量浪费的内存和时间。BucketIterator可以将每个批次的相似长度的序列组合在一起,以最小化填充。
<code class="prism language-python has-numbering"><span class="token comment"># 生成向量的批数据</span> train_iter<span class="token punctuation">,</span> test_iter <span class="token operator">=</span> data<span class="token punctuation">.</span>BucketIterator<span class="token punctuation">.</span>splits<span class="token punctuation">(</span><span class="token punctuation">(</span>train<span class="token punctuation">,</span> test<span class="token punctuation">)</span><span class="token punctuation">,</span> batch_size<span class="token operator">=</span><span class="token number">32</span><span class="token punctuation">,</span> device<span class="token operator">=</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span>shuffle<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span> train_iter<span class="token punctuation">.</span>repeat <span class="token operator">=</span> <span class="token boolean">False</span> test_iter<span class="token punctuation">.</span>repeat <span class="token operator">=</span> <span class="token boolean">False</span> </code>
这里device=-1表示使用cpu,设置为None时使用gpu。并设置为非重复的迭代器。 然后,可以根据迭代器创建批数据。
<code class="prism language-python has-numbering">batch <span class="token operator">=</span> <span class="token builtin">next</span><span class="token punctuation">(</span><span class="token builtin">iter</span><span class="token punctuation">(</span>train_iter<span class="token punctuation">)</span><span class="token punctuation">) </span> </code>
5.2.4 使用词向量创建网络模型
<code class="prism language-python has-numbering"><span class="token keyword">class</span> <span class="token class-name">EmbNet</span><span class="token punctuation">(</span>nn<span class="token punctuation">.</span>Module<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span>emb_size<span class="token punctuation">,</span>hidden_size1<span class="token punctuation">,</span>hidden_size2<span class="token operator">=</span><span class="token number">400</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token builtin">super</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>__init__<span class="token punctuation">(</span><span class="token punctuation">)</span>
self<span class="token punctuation">.</span>embedding <span class="token operator">=</span> nn<span class="token punctuation">.</span>Embedding<span class="token punctuation">(</span>emb_size<span class="token punctuation">,</span>hidden_size1<span class="token punctuation">)</span>
self<span class="token punctuation">.</span>fc <span class="token operator">=</span> nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>hidden_size2<span class="token punctuation">,</span><span class="token number">3</span><span class="token punctuation">)</span>
self<span class="token punctuation">.</span>log_softmax <span class="token operator">=</span> nn<span class="token punctuation">.</span>LogSoftmax<span class="token punctuation">(</span>dim <span class="token operator">=</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span>x<span class="token punctuation">)</span><span class="token punctuation">:</span>
embeds <span class="token operator">=</span> self<span class="token punctuation">.</span>embedding<span class="token punctuation">(</span>x<span class="token punctuation">)</span><span class="token punctuation">.</span>view<span class="token punctuation">(</span>x<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">,</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span>
out <span class="token operator">=</span> self<span class="token punctuation">.</span>fc<span class="token punctuation">(</span>embeds<span class="token punctuation">)</span>
out <span class="token operator">=</span> self<span class="token punctuation">.</span>log_softmax<span class="token punctuation">(</span>out<span class="token punctuation">)</span>
<span class="token keyword">return</span> out
model <span class="token operator">=</span> EmbNet<span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>TEXT<span class="token punctuation">.</span>vocab<span class="token punctuation">.</span>stoi<span class="token punctuation">)</span><span class="token punctuation">,</span><span class="token number">20</span><span class="token punctuation">)</span>
model <span class="token operator">=</span> model<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer <span class="token operator">=</span> optim<span class="token punctuation">.</span>Adam<span class="token punctuation">(</span>model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span>lr<span class="token operator">=</span><span class="token number">0.001</span><span class="token punctuation">)</span>
</code>
模型包括三层,首先是一个embedding层,它接收两个参数,即词表的大小和希望为每个单词创建的word embedding的维度。对于一个句子来说,所有的词的word embedding向量收尾相接(扁平化),通过一个线性层和一个log_softmax层得到最后的分类。
5.2.5 训练模型
<code class="prism language-python has-numbering"><span class="token keyword">def</span> <span class="token function">fit</span><span class="token punctuation">(</span>epoch<span class="token punctuation">,</span> model<span class="token punctuation">,</span> data_loader<span class="token punctuation">,</span> phase <span class="token operator">=</span> <span class="token string">'training'</span><span class="token punctuation">,</span> volatile <span class="token operator">=</span> <span class="token boolean">False</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">if</span> phase <span class="token operator">==</span> <span class="token string">'training'</span><span class="token punctuation">:</span>
model<span class="token punctuation">.</span>train<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> phase <span class="token operator">==</span> <span class="token string">'validation'</span><span class="token punctuation">:</span>
model<span class="token punctuation">.</span><span class="token builtin">eval</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
volatile <span class="token operator">=</span> <span class="token boolean">True</span>
running_loss <span class="token operator">=</span> <span class="token number">0.0</span>
running_correct <span class="token operator">=</span> <span class="token number">0.0</span>
<span class="token keyword">for</span> batch_idx<span class="token punctuation">,</span> batch <span class="token keyword">in</span> <span class="token builtin">enumerate</span><span class="token punctuation">(</span>data_loader<span class="token punctuation">)</span><span class="token punctuation">:</span>
text<span class="token punctuation">,</span> target <span class="token operator">=</span> batch<span class="token punctuation">.</span>text<span class="token punctuation">,</span> batch<span class="token punctuation">.</span>label
<span class="token keyword">if</span> is_cuda<span class="token punctuation">:</span>
text<span class="token punctuation">,</span> target <span class="token operator">=</span> text<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> target<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> phase <span class="token operator">==</span> <span class="token string">'training'</span><span class="token punctuation">:</span>
optimizer<span class="token punctuation">.</span>zero_grad<span class="token punctuation">(</span><span class="token punctuation">)</span>
output <span class="token operator">=</span> model<span class="token punctuation">(</span>text<span class="token punctuation">)</span>
loss <span class="token operator">=</span> F<span class="token punctuation">.</span>nll_loss<span class="token punctuation">(</span>output<span class="token punctuation">,</span> target<span class="token punctuation">)</span>
running_loss <span class="token operator">+=</span> F<span class="token punctuation">.</span>nll_loss<span class="token punctuation">(</span>output<span class="token punctuation">,</span> target<span class="token punctuation">,</span> reduction<span class="token operator">=</span><span class="token string">'sum'</span><span class="token punctuation">)</span><span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span>
preds <span class="token operator">=</span> output<span class="token punctuation">.</span>data<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>dim<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">,</span> keepdim <span class="token operator">=</span> <span class="token boolean">True</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span>
running_correct <span class="token operator">+=</span> preds<span class="token punctuation">.</span>eq<span class="token punctuation">(</span>target<span class="token punctuation">.</span>data<span class="token punctuation">.</span>view_as<span class="token punctuation">(</span>preds<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">.</span>cpu<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> phase <span class="token operator">==</span> <span class="token string">'training'</span><span class="token punctuation">:</span>
loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer<span class="token punctuation">.</span>step<span class="token punctuation">(</span><span class="token punctuation">)</span>
loss <span class="token operator">=</span> running_loss<span class="token operator">/</span><span class="token builtin">len</span><span class="token punctuation">(</span>data_loader<span class="token punctuation">.</span>dataset<span class="token punctuation">)</span>
accuracy <span class="token operator">=</span> <span class="token number">100</span><span class="token punctuation">.</span> <span class="token operator">*</span> running_correct<span class="token operator">/</span><span class="token builtin">len</span><span class="token punctuation">(</span>data_loader<span class="token punctuation">.</span>dataset<span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>f<span class="token string">'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}'</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> loss<span class="token punctuation">,</span>accuracy
train_losses <span class="token punctuation">,</span> train_accuracy <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">,</span><span class="token punctuation">[</span><span class="token punctuation">]</span>
val_losses <span class="token punctuation">,</span> val_accuracy <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">,</span><span class="token punctuation">[</span><span class="token punctuation">]</span>
<span class="token keyword">for</span> epoch <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">,</span><span class="token number">10</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
epoch_loss<span class="token punctuation">,</span> epoch_accuracy <span class="token operator">=</span> fit<span class="token punctuation">(</span>epoch<span class="token punctuation">,</span>model<span class="token punctuation">,</span>train_iter<span class="token punctuation">,</span>phase<span class="token operator">=</span><span class="token string">'training'</span><span class="token punctuation">)</span>
val_epoch_loss <span class="token punctuation">,</span> val_epoch_accuracy <span class="token operator">=</span> fit<span class="token punctuation">(</span>epoch<span class="token punctuation">,</span>model<span class="token punctuation">,</span>test_iter<span class="token punctuation">,</span>phase<span class="token operator">=</span><span class="token string">'validation'</span><span class="token punctuation">)</span>
train_losses<span class="token punctuation">.</span>append<span class="token punctuation">(</span>epoch_loss<span class="token punctuation">)</span>
train_accuracy<span class="token punctuation">.</span>append<span class="token punctuation">(</span>epoch_accuracy<span class="token punctuation">)</span>
val_losses<span class="token punctuation">.</span>append<span class="token punctuation">(</span>val_epoch_loss<span class="token punctuation">)</span>
val_accuracy<span class="token punctuation">.</span>append<span class="token punctuation">(</span>val_epoch_accuracy<span class="token punctuation">)</span>
</code>
经过10轮训练之后,准确率大致在70%左右。
5.2.6 使用预训练好的词向量
很多时候,在处理特定领域的NLP任务时,使用预训练好的词向量会非常有用。通常使用预训练的词向量包括下面三个步骤。 下载词向量
<code class="prism language-python has-numbering">TEXT<span class="token punctuation">.</span>build_vocab<span class="token punctuation">(</span>train<span class="token punctuation">,</span> vectors<span class="token operator">=</span>GloVe<span class="token punctuation">(</span>name<span class="token operator">=</span><span class="token string">'6B'</span><span class="token punctuation">,</span> dim<span class="token operator">=</span><span class="token number">300</span><span class="token punctuation">)</span><span class="token punctuation">,</span>max_size<span class="token operator">=</span><span class="token number">10000</span><span class="token punctuation">,</span>min_freq<span class="token operator">=</span><span class="token number">20</span><span class="token punctuation">)</span> </code>
这里的vectors设置词向量为GloVe中的向量,执行上面的代码,这些词向量就会自动加载到本地。 torchtext.vocab里面提供了很多预训练了的词向量,入GloVe,charngram,fasttext等。具体可以看官方的文档。 在模型中加载词向量 在模型中加载预训练好的词向量,也就是将这个预训练好的词向量存储到模型中embedding层的权重里。
<code class="prism language-python has-numbering">model <span class="token operator">=</span> EmbNet<span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>TEXT<span class="token punctuation">.</span>vocab<span class="token punctuation">.</span>stoi<span class="token punctuation">)</span><span class="token punctuation">,</span><span class="token number">300</span><span class="token punctuation">,</span> <span class="token number">6000</span><span class="token punctuation">)</span> <span class="token comment"># 利用预训练好的词向量</span> model<span class="token punctuation">.</span>embedding<span class="token punctuation">.</span>weight<span class="token punctuation">.</span>data <span class="token operator">=</span> TEXT<span class="token punctuation">.</span>vocab<span class="token punctuation">.</span>vectors<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span> </code>
这里模型的hidden_size1的值为300,也就是每个词为embedded为300维的向量,这是因为我们前面使用的预训练的词向量是300维的。hidden_size=6000是因为我们前面设置每个句子有20个词 【TEXT.build_vocab(train, dim=300),max_size=10000,min_freq=20)】,每个词是300维的向量,扁平化后线性层的输入维度为300×20=6000。 冻结embedding层 词向量加载后,必须确保训练期间向量的权重不会改变,也就是冻结embedding层的权重。具体分为两步:
<code class="prism language-python has-numbering"><span class="token comment"># 冻结embedding层的权重</span> model<span class="token punctuation">.</span>embedding<span class="token punctuation">.</span>weight<span class="token punctuation">.</span>requires_grad <span class="token operator">=</span> <span class="token boolean">False</span> optimizer <span class="token operator">=</span> optim<span class="token punctuation">.</span>Adam<span class="token punctuation">(</span><span class="token punctuation">[</span> param <span class="token keyword">for</span> param <span class="token keyword">in</span> model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">if</span> param<span class="token punctuation">.</span>requires_grad <span class="token operator">==</span> <span class="token boolean">True</span><span class="token punctuation">]</span><span class="token punctuation">,</span>lr<span class="token operator">=</span><span class="token number">0.001</span><span class="token punctuation">)</span> </code>
- 将embedding层的requires_grad属性设置为False,即不需要梯度;
- 将优化器中的这些权重删除。
5.2.7 模型结果讨论
| 模型 | 准确率(%) |
|---|---|
| 不使用预训练的词向量 | 66.5 |
| 使用预训练的词向量 | 61.8 |
当然在这个案例中使用预训练的词向量的效果并不是那么明显,主要是这个方法啦。
5.3 【案例四】基于LSTM的情感分类器
我们接下来继续使用IMDB数据,利用LSTM构建模型,来搭建一个文本的情感分类器。 构建模型
<code class="prism language-python has-numbering"><span class="token comment">## 创建模型</span>
<span class="token keyword">class</span> <span class="token class-name">IMDBRnn</span><span class="token punctuation">(</span>nn<span class="token punctuation">.</span>Module<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> vocab<span class="token punctuation">,</span> hidden_size<span class="token punctuation">,</span> n_cat<span class="token punctuation">,</span> bs <span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">,</span> nl <span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token builtin">super</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>__init__<span class="token punctuation">(</span><span class="token punctuation">)</span>
self<span class="token punctuation">.</span>hidden_size <span class="token operator">=</span> hidden_size
self<span class="token punctuation">.</span>bs <span class="token operator">=</span> bs
self<span class="token punctuation">.</span>nl <span class="token operator">=</span> nl
self<span class="token punctuation">.</span>n_vocab <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>vocab<span class="token punctuation">)</span>
self<span class="token punctuation">.</span>n_cat <span class="token operator">=</span> n_cat
self<span class="token punctuation">.</span>e <span class="token operator">=</span> nn<span class="token punctuation">.</span>Embedding<span class="token punctuation">(</span>self<span class="token punctuation">.</span>n_vocab<span class="token punctuation">,</span> self<span class="token punctuation">.</span>hidden_size<span class="token punctuation">)</span>
self<span class="token punctuation">.</span>rnn <span class="token operator">=</span> nn<span class="token punctuation">.</span>LSTM<span class="token punctuation">(</span>self<span class="token punctuation">.</span>hidden_size<span class="token punctuation">,</span> self<span class="token punctuation">.</span>hidden_size<span class="token punctuation">,</span> self<span class="token punctuation">.</span>nl<span class="token punctuation">)</span>
self<span class="token punctuation">.</span>fc2 <span class="token operator">=</span> nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>self<span class="token punctuation">.</span>hidden_size<span class="token punctuation">,</span> self<span class="token punctuation">.</span>n_cat<span class="token punctuation">)</span>
self<span class="token punctuation">.</span>sofmax <span class="token operator">=</span> nn<span class="token punctuation">.</span>LogSoftmax<span class="token punctuation">(</span>dim <span class="token operator">=</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span>
bs <span class="token operator">=</span> x<span class="token punctuation">.</span>size<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span>
<span class="token keyword">if</span> bs <span class="token operator">!=</span> self<span class="token punctuation">.</span>bs<span class="token punctuation">:</span>
self<span class="token punctuation">.</span>bs <span class="token operator">=</span> bs
e_out <span class="token operator">=</span> self<span class="token punctuation">.</span>e<span class="token punctuation">(</span>x<span class="token punctuation">)</span>
h0 <span class="token operator">=</span> c0 <span class="token operator">=</span> Variable<span class="token punctuation">(</span>e_out<span class="token punctuation">.</span>data<span class="token punctuation">.</span>new<span class="token punctuation">(</span><span class="token operator">*</span><span class="token punctuation">(</span>self<span class="token punctuation">.</span>nl<span class="token punctuation">,</span> self<span class="token punctuation">.</span>bs<span class="token punctuation">,</span> self<span class="token punctuation">.</span>hidden_size<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">.</span>zero_<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
rnn_o<span class="token punctuation">,</span> _ <span class="token operator">=</span> self<span class="token punctuation">.</span>rnn<span class="token punctuation">(</span>e_out<span class="token punctuation">,</span> <span class="token punctuation">(</span>h0<span class="token punctuation">,</span> c0<span class="token punctuation">)</span><span class="token punctuation">)</span>
rnn_o <span class="token operator">=</span> rnn_o<span class="token punctuation">[</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">]</span>
fc <span class="token operator">=</span> self<span class="token punctuation">.</span>fc2<span class="token punctuation">(</span>rnn_o<span class="token punctuation">)</span>
out <span class="token operator">=</span> self<span class="token punctuation">.</span>sofmax<span class="token punctuation">(</span>fc<span class="token punctuation">)</span>
<span class="token keyword">return</span> out
model <span class="token operator">=</span> IMDBRnn<span class="token punctuation">(</span>n_vocab <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>TEXT<span class="token punctuation">.</span>vocab<span class="token punctuation">)</span><span class="token punctuation">,</span> hidden_size <span class="token operator">=</span> <span class="token number">100</span><span class="token punctuation">,</span> n_cat <span class="token operator">=</span> <span class="token number">3</span><span class="token punctuation">,</span> bs <span class="token operator">=</span> <span class="token number">32</span><span class="token punctuation">)</span>
model <span class="token operator">=</span> model<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer <span class="token operator">=</span> optim<span class="token punctuation">.</span>Adam<span class="token punctuation">(</span>model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span>lr<span class="token operator">=</span><span class="token number">1e</span><span class="token operator">-</span><span class="token number">3</span><span class="token punctuation">)</span>
</code>
训练模型 模型训练的代码和案例四一样。模型效果如下所示:
| 模型 | 准确率 |
|---|---|
| 案例三(无LSTM) | 66.5 |
| 案例四(LSTM) | 68.1 |
6. 循环神经网络的更多应用
6.1 GRU(Gated Recurrent Unit)
GRU和LSTM最大的不同在于GRU将遗忘门和输入门合成为一个“更新门”,输出也没有额外的细胞状态Ct,而是将ht作为记忆状态不断向后循环传递。
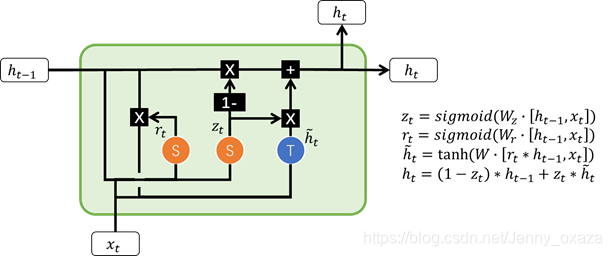
6.2 Encoder-Decoder/Seq2Seq
推荐阅读:
6.2.1 模型框架与注意力机制
Seq2Seq模型是循环神经网络的升级版,它联合了两个神经网络,一个神经网络负责接收来源句子,另外一个神经网络负责将句子输出成翻译的语言。前一个过程叫做编码(encoder),后一个过程叫做解码(decoder)。
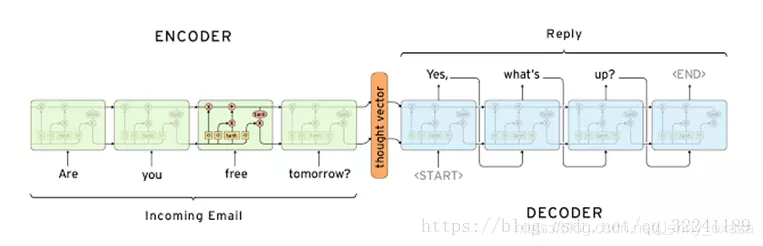 编码(encoder) 实际上运用了循环神经网络的记忆功能,但只保留最后一个隐藏状态,相当于将整句话浓缩在一起,将其转存为一个内容向量(thought vector)。**解码(decoder)**和编码的网络机构几乎是一样的,不同的是前一个细胞的输出作为下一个细胞的输入。 Seq2Seq模型的优势在于可以处理输入序列和输出序列不等长的问题,最典型的就是机器翻译。但是,这样的基本框架在实际应用中表现往往不够好,很大的原因是因为在编码过程中会将一句话的内容压缩成一个固定大小的内容向量;如果一句话比较长,这个压缩过程会导致信息失真——比如说,两句比较相似的话,可能只有一个单词不同,通过压缩后的内容向量过于相似,导致翻译的准确度过低。 那么,能不能不把隐藏状态压缩成一个内容向量,而是对每一个隐藏状态都加以使用呢? 当然可以,这就是 注意力机制(attention) 提出的初衷。注意力机制能让网络在解码的时候“集中注意力”在编码输出的某些部分上,而不仅仅依赖简单的内容向量。 关于这部分在 注意力机制的基本思想和实现原理(很详细)这篇文章里面讲的很详细,也很容易看懂,在此不做赘述。
编码(encoder) 实际上运用了循环神经网络的记忆功能,但只保留最后一个隐藏状态,相当于将整句话浓缩在一起,将其转存为一个内容向量(thought vector)。**解码(decoder)**和编码的网络机构几乎是一样的,不同的是前一个细胞的输出作为下一个细胞的输入。 Seq2Seq模型的优势在于可以处理输入序列和输出序列不等长的问题,最典型的就是机器翻译。但是,这样的基本框架在实际应用中表现往往不够好,很大的原因是因为在编码过程中会将一句话的内容压缩成一个固定大小的内容向量;如果一句话比较长,这个压缩过程会导致信息失真——比如说,两句比较相似的话,可能只有一个单词不同,通过压缩后的内容向量过于相似,导致翻译的准确度过低。 那么,能不能不把隐藏状态压缩成一个内容向量,而是对每一个隐藏状态都加以使用呢? 当然可以,这就是 注意力机制(attention) 提出的初衷。注意力机制能让网络在解码的时候“集中注意力”在编码输出的某些部分上,而不仅仅依赖简单的内容向量。 关于这部分在 注意力机制的基本思想和实现原理(很详细)这篇文章里面讲的很详细,也很容易看懂,在此不做赘述。
6.2.2 【案例五】Seq2Seq实战
数据下载 官网教程 因为这一部分内容比较多,而且官网都有比较详细的代码和介绍,我也把整个过程比较详细地梳理了一遍,指路我的另一篇文章:【深度学习实战】【详细解读】基于Seq2Seq模型实现简单的机器翻译
6.3 CNN+RNN——基于序列数据的卷积网络
CNN+RNN可以完成看图说话的任务,通过预训练的卷积神经网络提取图片特征,接着通过循环网络将特征变成文字描述。